Aligning Teacher with Student Preferences for Tailored Training Data Generation
作者: Yantao Liu, Zhao Zhang, Zijun Yao, Shulin Cao, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2024-06-27
💡 一句话要点
ARTE:对齐教师与学生偏好,定制化生成知识蒸馏训练数据
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 学生偏好 定制化训练数据 指令调整 响应式教学 模型对齐
📋 核心要点
- 现有知识蒸馏方法忽略了学生偏好,导致生成的训练数据可能不适合学生模型,影响学习效果。
- ARTE框架通过收集学生对教师生成内容的偏好,对齐教师模型,从而生成更符合学生需求的定制化训练数据。
- 实验表明,ARTE生成的训练数据能够显著提升学生模型的性能,并在推理能力和跨任务泛化方面表现出色。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中作为辅助工具展现出巨大潜力。在处理隐私敏感数据或延迟敏感任务时,在边缘设备上本地部署LLMs是必要的。但边缘设备的计算约束使得直接部署大型LLMs不切实际,因此需要从大型模型到轻量级模型的知识蒸馏。现有工作主要集中于从LLMs中提取多样性和高质量的训练样本,但很少关注基于学生偏好对齐教师的教学内容,类似于教学中的“响应式教学”。因此,我们提出了ARTE,即对齐教师与学生偏好,这是一个对齐教师模型与学生偏好,为知识蒸馏生成定制训练样本的框架。具体来说,我们从教师模型中提取问题草案和理由,然后使用学生在上下文学习中的表现作为代理来收集学生对这些问题和理由的偏好,最后将教师模型与学生偏好对齐。最后,我们使用对齐后的教师模型重复第一步,为目标任务上的学生模型提取定制的训练样本。在学术基准上的大量实验表明,ARTE优于现有的从强大的LLMs中提炼出的指令调整数据集。此外,我们彻底研究了ARTE的泛化能力,包括微调后的学生模型在推理能力方面的泛化,以及对齐后的教师模型在跨任务和学生生成定制训练数据方面的泛化。总之,我们的贡献在于提出了一个用于定制训练样本生成的新框架,证明了其在实验中的有效性,并研究了ARTE中学生模型和对齐后的教师模型的泛化能力。
🔬 方法详解
问题定义:论文旨在解决知识蒸馏中,教师模型生成的训练数据与学生模型需求不匹配的问题。现有方法通常侧重于从教师模型中提取多样性和高质量的训练样本,但忽略了学生模型的学习偏好,导致生成的训练数据可能对学生模型而言并非最优,影响知识传递的效率和效果。
核心思路:论文的核心思路是模仿“响应式教学”的理念,将教师模型与学生模型的偏好对齐。通过收集学生对教师模型生成内容的反馈,调整教师模型的生成策略,使其能够生成更符合学生模型学习需求的定制化训练数据。这种方法能够提高知识蒸馏的效率,并提升学生模型的性能。
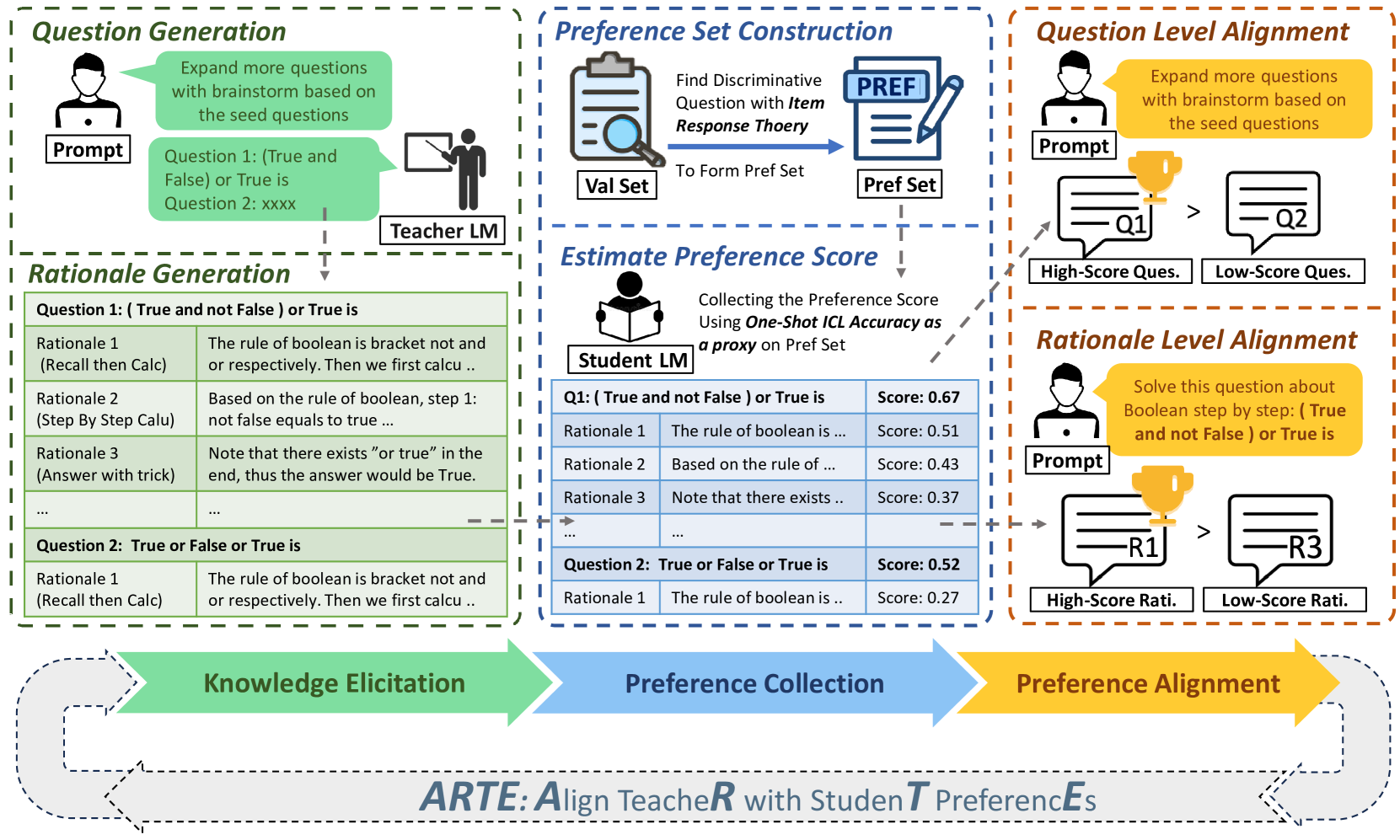
技术框架:ARTE框架包含以下三个主要阶段: 1. 问题与理由生成:教师模型生成问题草案和相应的理由。 2. 学生偏好收集:通过学生在上下文学习中的表现,收集学生对问题和理由的偏好。 3. 教师模型对齐:根据学生偏好调整教师模型,使其能够生成更符合学生需求的训练数据。然后,使用对齐后的教师模型重新生成训练数据,用于训练学生模型。
关键创新:ARTE的关键创新在于引入了学生偏好对齐机制,将教师模型与学生模型的需求联系起来。这与以往的知识蒸馏方法只关注教师模型生成数据的质量和多样性有本质区别。ARTE通过主动适应学生模型的学习特点,提高了知识传递的效率和效果。
关键设计:在学生偏好收集阶段,论文使用学生在上下文学习中的表现作为偏好的代理。具体来说,学生模型在给定上下文的情况下回答教师模型生成的问题,并根据回答的准确性来评估学生对该问题的偏好程度。这种方法避免了直接询问学生偏好的复杂性,并能够更客观地反映学生模型的学习需求。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ARTE框架在多个学术基准上优于现有的指令调整数据集。例如,在某些任务上,使用ARTE生成的训练数据训练的学生模型性能提升了显著百分比(具体数值未知)。此外,实验还验证了ARTE框架的泛化能力,包括学生模型在推理能力方面的泛化,以及对齐后的教师模型在跨任务和学生生成定制训练数据方面的泛化。
🎯 应用场景
ARTE框架可应用于各种需要知识蒸馏的场景,尤其是在边缘设备上部署轻量级语言模型时。通过定制化生成训练数据,可以显著提升学生模型的性能,使其能够在资源受限的环境中高效运行。此外,该方法还可以应用于个性化教育领域,根据学生的学习特点定制教学内容,提高学习效率。
📄 摘要(原文)
Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to "responsive teaching" in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.