STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
作者: Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
分类: cs.CL
发布日期: 2024-06-27
🔗 代码/项目: GITHUB
💡 一句话要点
STBench:评估大语言模型在时空分析中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 时空分析 基准数据集 知识理解 时空推理 精确计算 下游应用
📋 核心要点
- 现有评估LLM时空能力的工作不足,主要集中在记忆知识评估,忽略了推理、计算和应用能力。
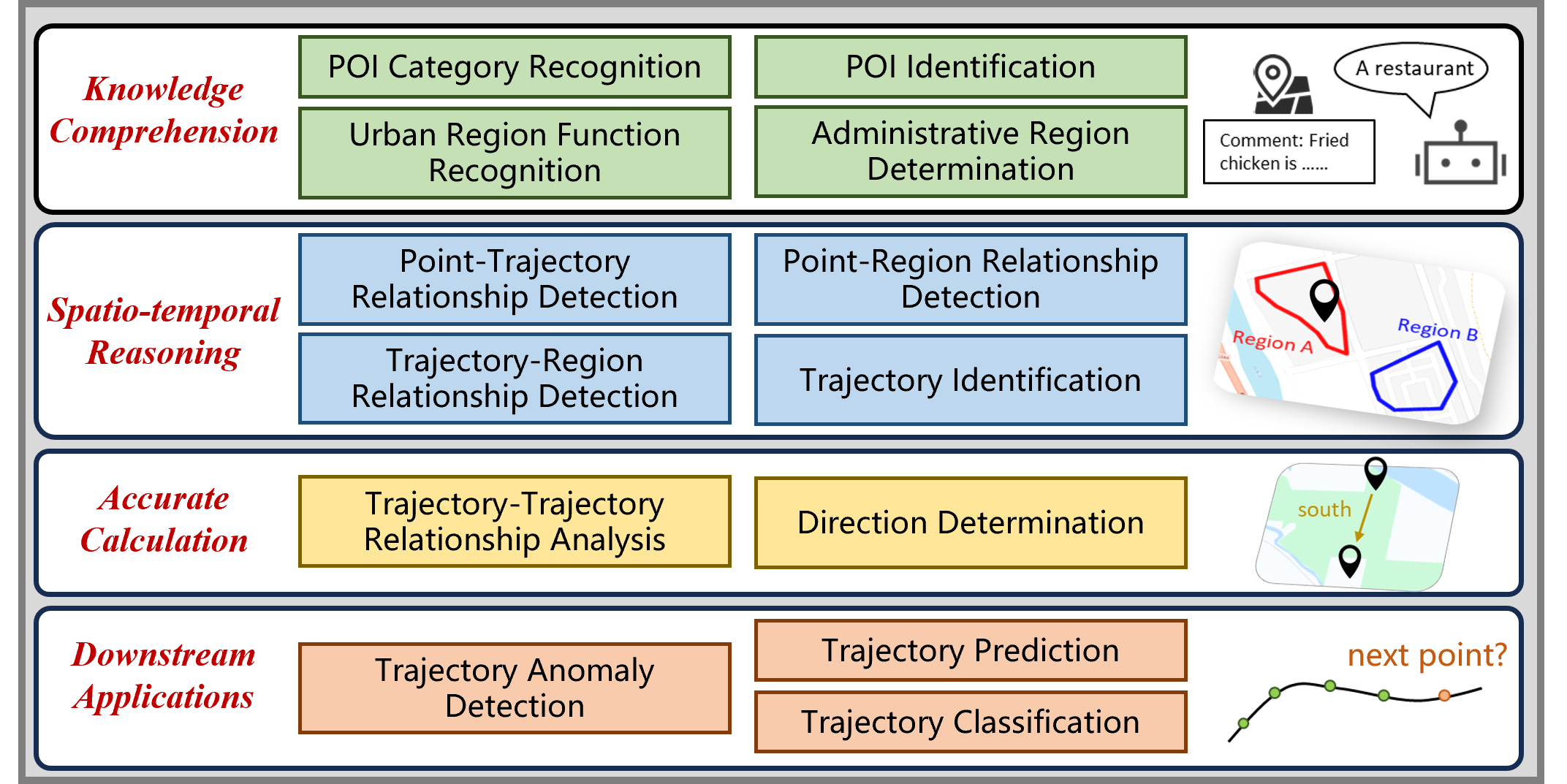
- 论文构建了STBench基准数据集,包含知识理解、时空推理、精确计算和下游应用四个维度,更全面地评估LLM。
- 实验评估了13个LLM,结果表明LLM在知识理解和时空推理方面表现出色,但其他任务仍有提升空间。
📝 摘要(中文)
大语言模型(LLMs)的快速发展有望革新时空数据挖掘的方法。然而,目前评估LLMs时空理解能力的工作存在局限性和偏差,要么未能纳入最新的语言模型,要么仅关注评估记忆的时空知识。为了弥补这一差距,本文将LLMs的时空数据能力分解为四个不同的维度:知识理解、时空推理、精确计算和下游应用。我们为每个类别策划了多个自然语言问答任务,并构建了名为STBench的基准数据集,其中包含13个不同的任务和超过60,000个问答对。此外,我们评估了13个LLMs的能力,例如GPT-4o、Gemma和Mistral。实验结果表明,现有的LLMs在知识理解和时空推理任务上表现出色,并且可以通过上下文学习、思维链提示和微调进一步增强在其他任务上的潜力。STBench的代码和数据集已在https://github.com/LwbXc/STBench上发布。
🔬 方法详解
问题定义:现有评估大语言模型(LLMs)时空理解能力的方法存在局限性,主要体现在两个方面:一是评估的LLM不够新,未能及时跟进最新的模型进展;二是评估内容过于片面,主要集中在考察LLM是否记忆了时空知识,而忽略了其进行时空推理、精确计算以及解决下游应用问题的能力。这些不足导致无法全面、准确地评估LLMs在时空数据分析方面的潜力。
核心思路:论文的核心思路是将LLMs的时空数据能力解构为四个关键维度:知识理解、时空推理、精确计算和下游应用。通过构建包含这四个维度的基准数据集,可以更全面地评估LLMs在时空数据分析方面的能力。这种多维度的评估方法能够更准确地反映LLMs的优势和不足,为未来的研究方向提供指导。
技术框架:STBench的整体框架围绕着四个核心维度展开:知识理解、时空推理、精确计算和下游应用。针对每个维度,论文设计了多个自然语言问答任务,并收集了大量的问答对,构建成基准数据集。该数据集包含13个不同的任务,总计超过60,000个问答对。然后,使用该数据集对多个LLMs进行评估,分析它们在各个维度上的表现。
关键创新:STBench的关键创新在于其多维度的评估体系,它不仅仅关注LLMs对时空知识的记忆能力,更关注其进行时空推理、精确计算以及解决下游应用问题的能力。这种全面的评估方法能够更准确地反映LLMs在时空数据分析方面的潜力,与现有方法只关注记忆能力有本质区别。
关键设计:STBench的关键设计在于针对每个维度精心设计的自然语言问答任务。这些任务的设计需要充分考虑该维度所考察的能力,例如,时空推理任务需要考察LLMs根据已知信息推断未知时空关系的能力,精确计算任务需要考察LLMs进行时空数据计算的能力。此外,数据集的规模也是一个关键设计,足够大的数据集才能保证评估结果的可靠性。
🖼️ 关键图片
📊 实验亮点
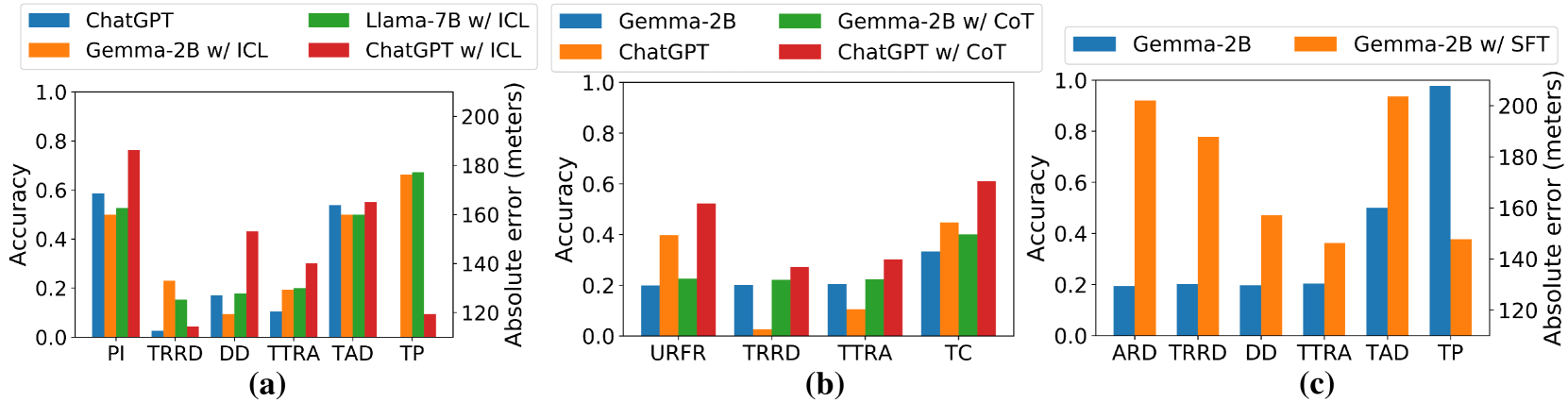
实验结果表明,现有的LLMs在知识理解和时空推理任务上表现出色,但在精确计算和下游应用方面仍有提升空间。例如,GPT-4o在知识理解任务上取得了最高的准确率,但在精确计算任务上的表现相对较弱。通过上下文学习、思维链提示和微调等技术,可以进一步提升LLMs在这些任务上的性能。
🎯 应用场景
该研究成果可应用于智慧城市、交通管理、环境监测、灾害预警等领域。通过评估和提升LLM的时空分析能力,可以帮助相关领域更好地理解和利用时空数据,从而做出更明智的决策,提高效率,降低风险。未来,该研究可以推动LLM在时空数据挖掘领域的更广泛应用。
📄 摘要(原文)
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.