DataGen: Unified Synthetic Dataset Generation via Large Language Models
作者: Yue Huang, Siyuan Wu, Chujie Gao, Dongping Chen, Qihui Zhang, Yao Wan, Tianyi Zhou, Jianfeng Gao, Chaowei Xiao, Lichao Sun, Xiangliang Zhang
分类: cs.CL
发布日期: 2024-06-27 (更新: 2025-11-17)
💡 一句话要点
DataGen:提出一种基于大语言模型的统一合成数据集生成框架,提升数据质量与可控性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 大语言模型 数据增强 基准测试 可控生成
📋 核心要点
- 现有生成框架在泛化性、可控性、多样性和真实性方面存在挑战,限制了合成数据生成的效果。
- DataGen通过属性引导生成、群体检查、代码验证和检索增强等模块,提升数据多样性、准确性和可控性。
- 实验表明,DataGen生成的数据质量优于现有方法,并成功应用于LLM基准测试和数据增强,提升了LLM性能。
📝 摘要(中文)
本文提出DataGen,一个基于大语言模型的综合框架,旨在生成多样、准确且高度可控的数据集。DataGen具有很强的适应性,支持所有类型的文本数据集,并通过创新机制增强生成过程。为了提高数据多样性,DataGen整合了属性引导生成模块和群体检查功能。为了保证准确性,它采用了基于代码的数学评估进行标签验证,并结合检索增强生成技术进行事实验证。该框架还允许用户指定约束条件,从而能够根据特定需求定制数据生成过程。大量实验表明,DataGen生成的数据质量优异,并且DataGen中的每个模块都在增强数据质量方面发挥着关键作用。此外,DataGen还应用于两个实际场景:大语言模型基准测试和数据增强。结果表明,DataGen有效地支持动态和不断发展的基准测试,并且数据增强提高了LLM在各个领域的能力,包括面向代理的能力和推理技能。
🔬 方法详解
问题定义:现有的大语言模型在合成数据生成方面存在泛化性不足、可控性差、数据多样性有限以及难以保证生成数据的真实性等问题。这些问题限制了合成数据在实际应用中的效果,例如在模型训练和评估中,高质量的合成数据能够显著提升模型的性能和可靠性。
核心思路:DataGen的核心思路是利用大语言模型强大的生成能力,结合多种创新机制,从属性引导、群体检查、代码验证和检索增强等多个维度来提升生成数据的质量和可控性。通过用户指定的约束条件,进一步定制数据生成过程,使其能够满足特定需求。
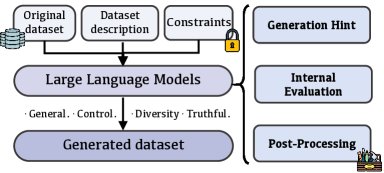
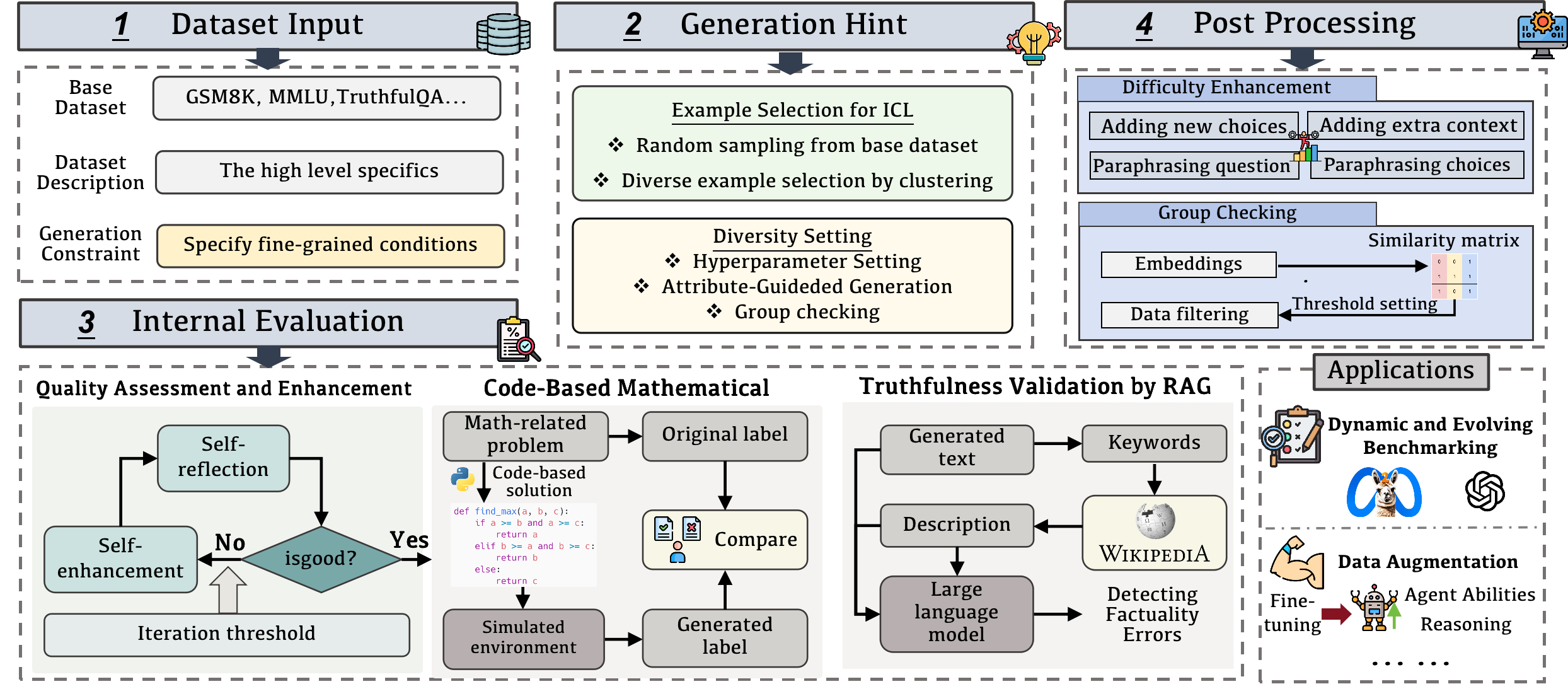
技术框架:DataGen框架主要包含以下几个核心模块:1) 属性引导生成模块:通过指定数据的属性,引导LLM生成具有特定特征的数据,从而提高数据的多样性。2) 群体检查模块:对生成的数据进行群体层面的检查,确保数据的整体分布符合预期。3) 代码验证模块:对于涉及数学计算的数据,使用代码进行验证,确保标签的准确性。4) 检索增强生成模块:通过检索相关知识,增强生成数据的真实性和可靠性。整个流程以用户指定的约束条件为输入,经过上述模块的处理,最终生成高质量的合成数据集。
关键创新:DataGen的关键创新在于其综合利用多种技术手段,从多个维度提升合成数据的质量和可控性。与现有方法相比,DataGen不仅关注数据的多样性,更注重数据的准确性和真实性,并且能够根据用户需求进行定制化生成。这种综合性的方法使得DataGen能够生成更符合实际应用需求的高质量合成数据。
关键设计:DataGen的关键设计包括:1) 属性引导生成:通过prompt工程,引导LLM生成具有特定属性的数据。2) 群体检查:使用统计方法对生成数据的分布进行检查,例如均值、方差等。3) 代码验证:使用Python等编程语言编写代码,对涉及数学计算的数据进行验证。4) 检索增强生成:使用检索模型从知识库中检索相关信息,并将其融入到生成过程中。
🖼️ 关键图片
📊 实验亮点
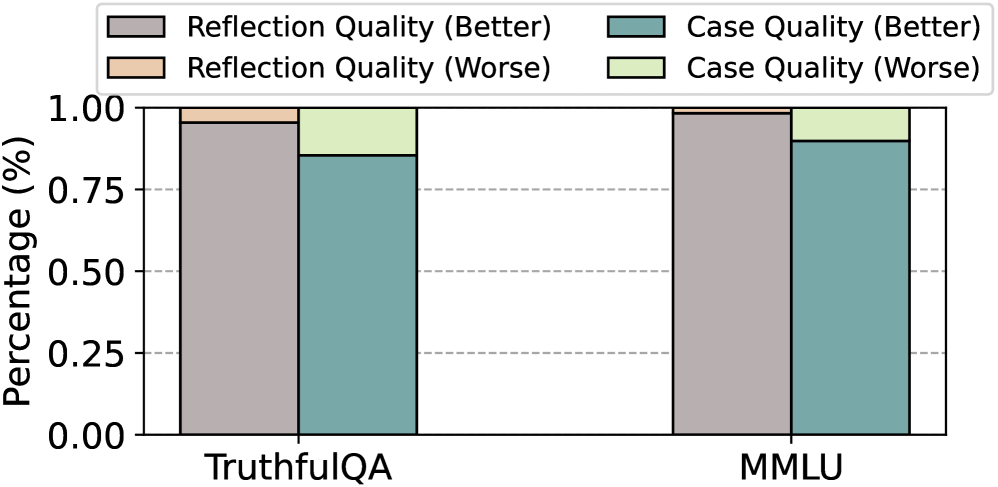
实验结果表明,DataGen生成的数据质量优于现有方法,并且在LLM基准测试和数据增强方面取得了显著效果。例如,使用DataGen进行数据增强后,LLM在智能体能力和推理能力方面均有明显提升。具体性能数据未知,但强调了DataGen在提升LLM性能方面的有效性。
🎯 应用场景
DataGen可应用于大语言模型的基准测试,通过生成动态和不断发展的测试数据集,更全面地评估LLM的性能。此外,DataGen还可用于数据增强,提升LLM在各种领域的表现,例如智能体能力和推理能力。该研究成果有助于降低对昂贵的人工标注数据的依赖,加速人工智能技术的发展。
📄 摘要(原文)
Large Language Models (LLMs) such as GPT-4 and Llama3 have significantly impacted various fields by enabling high-quality synthetic data generation and reducing dependence on expensive human-generated datasets. Despite this, challenges remain in the areas of generalization, controllability, diversity, and truthfulness within the existing generative frameworks. To address these challenges, this paper presents DataGen, a comprehensive LLM-powered framework designed to produce diverse, accurate, and highly controllable datasets. DataGen is adaptable, supporting all types of text datasets and enhancing the generative process through innovative mechanisms. To augment data diversity, DataGen incorporates an attribute-guided generation module and a group checking feature. For accuracy, it employs a code-based mathematical assessment for label verification alongside a retrieval-augmented generation technique for factual validation. The framework also allows for user-specified constraints, enabling customization of the data generation process to suit particular requirements. Extensive experiments demonstrate the superior quality of data generated by DataGen, and each module within DataGen plays a critical role in this enhancement. Additionally, DataGen is applied in two practical scenarios: benchmarking LLMs and data augmentation. The results indicate that DataGen effectively supports dynamic and evolving benchmarking and that data augmentation improves LLM capabilities in various domains, including agent-oriented abilities and reasoning skills.