Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
作者: Melanie Walsh, Anna Preus, Maria Antoniak
分类: cs.CL
发布日期: 2024-06-27 (更新: 2024-10-10)
备注: 2024 EMNLP Findings
💡 一句话要点
评估大型语言模型诗歌形式识别能力,揭示模型对诗歌特征的理解程度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 诗歌评估 诗歌形式识别 基准数据集 自然语言处理
📋 核心要点
- 现有大型语言模型在诗歌生成方面表现出色,但对其诗歌理解能力,特别是诗歌形式的识别能力,缺乏系统评估。
- 该论文提出了一种评估方法,通过构建包含多种诗歌形式的基准数据集,考察模型对韵律、格律等诗歌特征的识别能力。
- 实验结果表明,模型在识别固定诗歌形式方面表现良好,但在识别非固定形式时面临挑战,预训练数据的影响尚不明确。
📝 摘要(中文)
大型语言模型(LLMs)现在可以生成和识别诗歌。但是,LLMs 究竟对诗歌了解多少?本文开发了一项任务,用于评估 LLMs 在识别英语诗歌的一个方面——诗歌形式——的能力,诗歌形式涵盖了许多不同的诗歌特征,包括韵律、格律以及单词或诗句的重复。通过使用超过 4.1k 首人工专家标注诗歌的基准数据集,我们表明,最先进的 LLMs 可以以惊人的高精度成功识别常见和不常见的固定诗歌形式——例如十四行诗、六韵诗和潘图姆诗。然而,性能因诗歌形式而异;这些模型难以识别非固定诗歌形式,尤其是那些基于主题或视觉特征的诗歌形式。此外,我们还测量了基准数据集中有多少诗歌出现在流行的预训练数据集中或被 GPT-4 记忆,发现预训练的存在和记忆可能会提高此任务的性能,但结果尚无定论。我们发布了一个包含 1.4k 首公共领域诗歌和形式注释的基准评估数据集、记忆实验和数据审计的结果以及代码。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)对英语诗歌形式的识别能力。现有方法缺乏对LLMs诗歌理解能力的细致评估,尤其是在诗歌形式识别方面,而诗歌形式蕴含了丰富的诗歌特征,如韵律、格律等。因此,如何设计一个有效的评估框架,衡量LLMs对不同诗歌形式的理解程度,是本文要解决的核心问题。
核心思路:论文的核心思路是构建一个包含多种诗歌形式的基准数据集,并利用该数据集评估LLMs对不同诗歌形式的分类能力。通过分析模型在不同诗歌形式上的表现差异,可以深入了解模型对诗歌特征的理解程度。这种方法避免了直接评估模型生成诗歌的质量,而是聚焦于模型对诗歌形式的识别,从而提供更客观的评估结果。
技术框架:整体框架包括以下几个主要阶段:1) 数据集构建:收集并标注包含多种诗歌形式的诗歌数据集,包括固定形式(如十四行诗)和非固定形式。2) 模型评估:使用LLMs对数据集中的诗歌进行分类,判断其所属的诗歌形式。3) 性能分析:分析模型在不同诗歌形式上的分类准确率,并考察预训练数据对模型性能的影响。4) 结果发布:公开数据集、评估代码和实验结果,方便其他研究者进行后续研究。
关键创新:该论文的关键创新在于构建了一个专门用于评估LLMs诗歌形式识别能力的基准数据集。该数据集包含多种诗歌形式,并由人工专家进行标注,保证了数据的质量和可靠性。此外,论文还深入分析了模型在不同诗歌形式上的表现差异,揭示了模型在诗歌理解方面的优势和不足。与现有方法相比,该论文的评估方法更加客观和细致,能够更准确地反映LLMs对诗歌的理解程度。
关键设计:数据集包含超过4.1k首人工专家标注的诗歌,其中1.4k首为公共领域诗歌,并公开。评估指标主要采用分类准确率,用于衡量模型识别诗歌形式的准确程度。论文还考察了预训练数据对模型性能的影响,通过分析模型在预训练数据中出现过的诗歌和未出现过的诗歌上的表现差异,来评估记忆效应对模型性能的影响。具体的LLMs模型包括GPT-4等。
🖼️ 关键图片

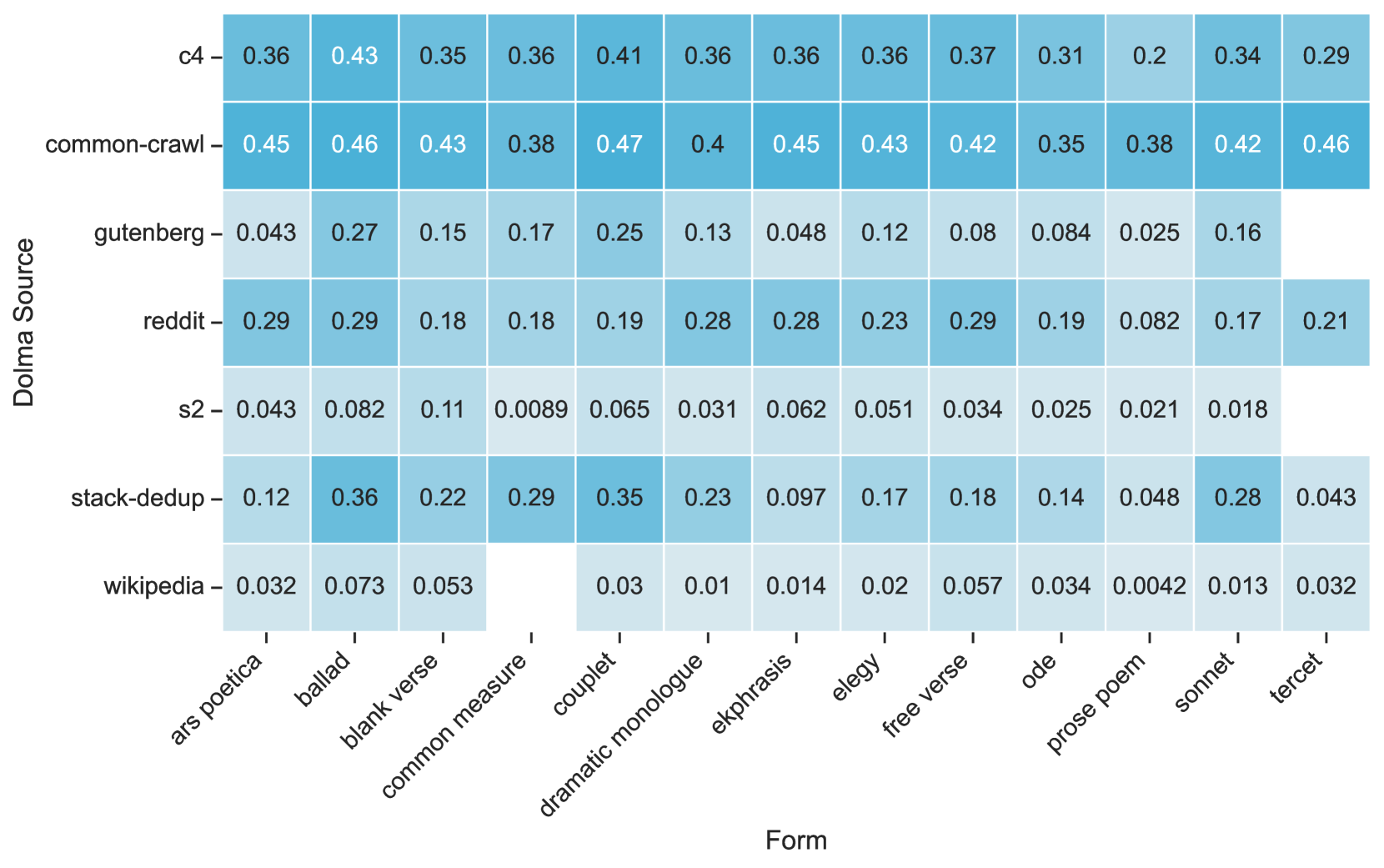
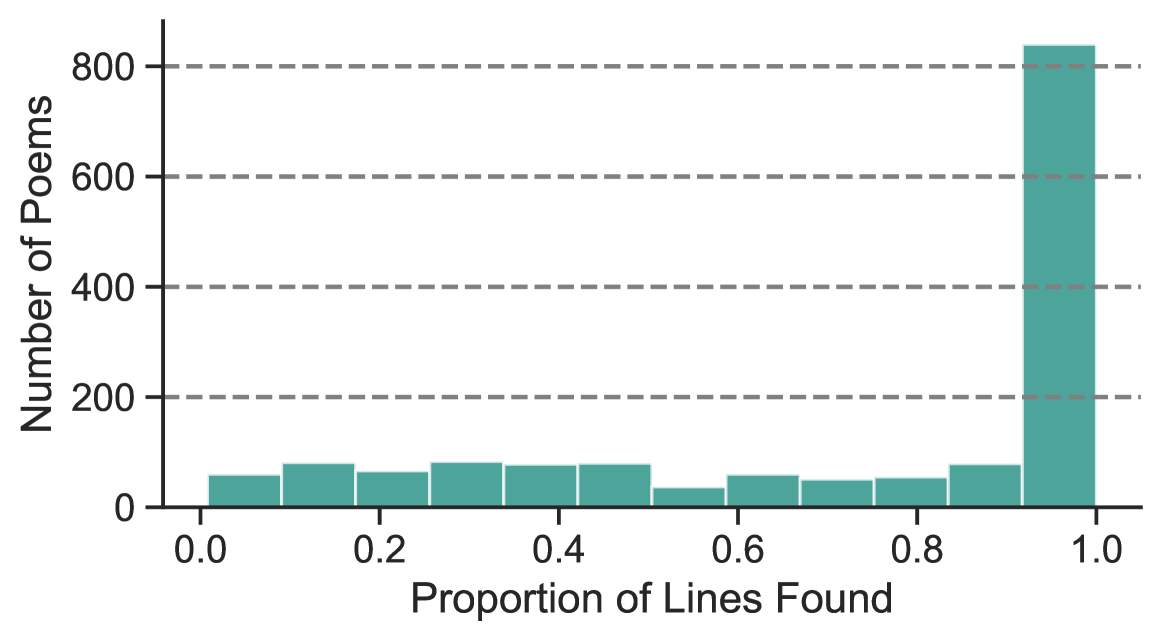
📊 实验亮点
实验结果表明,最先进的LLMs可以以较高的准确率识别固定诗歌形式,如十四行诗。然而,模型在识别非固定诗歌形式时表现较差,尤其是在基于主题或视觉特征的诗歌形式上。此外,研究发现预训练数据可能对模型性能有一定影响,但结果尚不明确。该研究发布了包含1.4k首公共领域诗歌的基准数据集,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于提升大型语言模型在诗歌生成和理解方面的能力,例如,可以利用评估结果指导模型训练,使其更好地理解和运用各种诗歌形式。此外,该研究还可以应用于诗歌教育领域,帮助学生更好地理解和欣赏诗歌。未来,该研究可以扩展到其他文学形式的评估,例如小说、戏剧等。
📄 摘要(原文)
Large language models (LLMs) can now generate and recognize poetry. But what do LLMs really know about poetry? We develop a task to evaluate how well LLMs recognize one aspect of English-language poetry--poetic form--which captures many different poetic features, including rhyme scheme, meter, and word or line repetition. By using a benchmark dataset of over 4.1k human expert-annotated poems, we show that state-of-the-art LLMs can successfully identify both common and uncommon fixed poetic forms--such as sonnets, sestinas, and pantoums--with surprisingly high accuracy. However, performance varies significantly by poetic form; the models struggle to identify unfixed poetic forms, especially those based on topic or visual features. We additionally measure how many poems from our benchmark dataset are present in popular pretraining datasets or memorized by GPT-4, finding that pretraining presence and memorization may improve performance on this task, but results are inconclusive. We release a benchmark evaluation dataset with 1.4k public domain poems and form annotations, results of memorization experiments and data audits, and code.