DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment
作者: Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, He Huang, Boris Ginsburg, Yu-Chiang Frank Wang, Hung-yi Lee
分类: eess.AS, cs.CL
发布日期: 2024-06-27
备注: Accepted to Interspeech 2024
💡 一句话要点
提出描述性语音-文本对齐方法DeSTA,增强语音语言模型对语音非语言特征的理解和泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音语言模型 语音-文本对齐 语音字幕生成 描述性语音 零样本学习
📋 核心要点
- 现有的语音语言模型(SLM)难以充分理解语音中的非语言特征,限制了其泛化能力。
- DeSTA方法通过语音字幕生成对齐语音和文本模态,使SLM能够理解和生成描述性语言。
- 实验表明,DeSTA显著提升了SLM在Dynamic-SUPERB上的性能,并展现出零样本指令遵循能力。
📝 摘要(中文)
本文提出了一种描述性语音-文本对齐方法(DeSTA),该方法利用语音字幕生成来弥合语音和文本模态之间的差距,使语音语言模型(SLM)能够解释和生成全面的自然语言描述,从而促进理解语音中的语言和非语言特征的能力。通过所提出的方法增强,我们的模型在Dynamic-SUPERB基准测试中表现出卓越的性能,尤其是在推广到未见过的任务中。此外,我们发现对齐后的模型表现出零样本指令遵循能力,而无需显式的语音指令微调。这些发现突出了通过结合丰富的描述性语音字幕来重塑指令遵循SLM的潜力。
🔬 方法详解
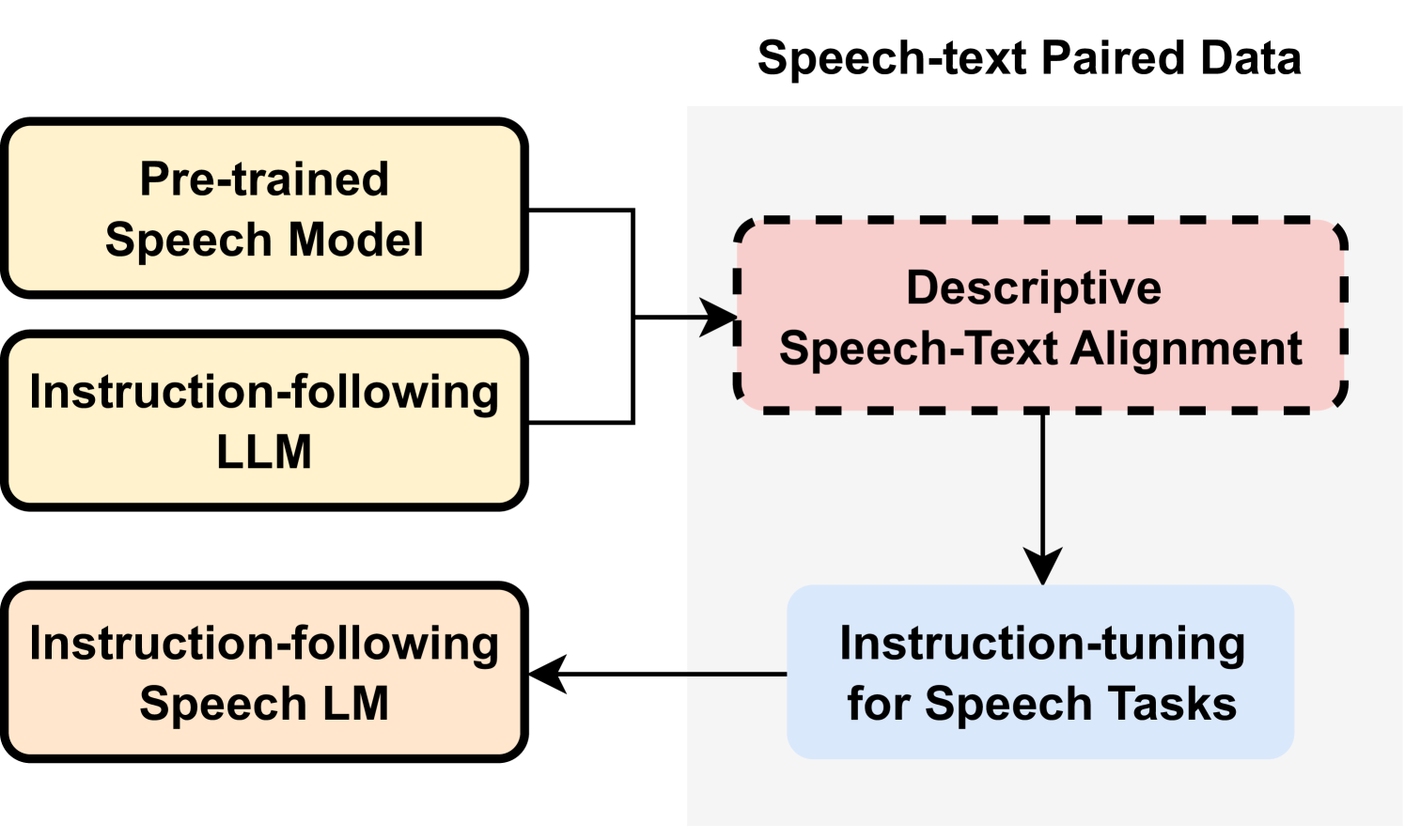
问题定义:现有的语音语言模型(SLM)通常依赖于预训练的语音模型来扩展大型语言模型(LLM)的能力。然而,这些模型在理解语音中的非语言特征(如情感、语调等)方面存在不足,导致在未见过的任务上的泛化能力受限。因此,需要一种方法来弥合语音和文本模态之间的差距,使SLM能够更好地理解和利用语音中的信息。
核心思路:DeSTA的核心思路是利用语音字幕生成技术,将语音转换为描述性的文本。通过这种方式,语音中的语言和非语言特征都被编码到文本描述中,从而使SLM能够同时理解语音和文本信息。这种对齐方式使得SLM能够更好地理解语音的含义,并生成更准确、更丰富的自然语言描述。
技术框架:DeSTA方法主要包含以下几个步骤:1) 使用预训练的语音识别模型(如Whisper)生成语音的文本转录。2) 使用语音字幕生成模型(如预训练的LLM)生成语音的描述性字幕。3) 将语音特征和描述性字幕输入到SLM中进行训练。4) SLM学习将语音特征与描述性字幕对齐,从而提高其理解语音和生成自然语言描述的能力。
关键创新:DeSTA的关键创新在于使用描述性语音字幕来对齐语音和文本模态。与传统的语音识别方法不同,描述性字幕不仅包含语音的文本内容,还包含语音中的非语言特征。这种对齐方式使得SLM能够更好地理解语音的含义,并生成更准确、更丰富的自然语言描述。此外,DeSTA方法还能够提高SLM在未见过的任务上的泛化能力。
关键设计:DeSTA方法的关键设计包括:1) 使用高质量的语音字幕生成模型,以确保生成的字幕能够准确地描述语音的内容和特征。2) 设计合适的损失函数,以鼓励SLM将语音特征与描述性字幕对齐。3) 使用大规模的语音和文本数据集进行训练,以提高SLM的泛化能力。具体的参数设置和网络结构取决于所使用的语音识别模型、语音字幕生成模型和SLM。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DeSTA方法在Dynamic-SUPERB基准测试中取得了显著的性能提升,尤其是在推广到未见过的任务中。此外,DeSTA还使SLM展现出零样本指令遵循能力,而无需显式的语音指令微调。这些结果表明,DeSTA方法能够有效地提高SLM对语音的理解能力和泛化能力。
🎯 应用场景
DeSTA方法具有广泛的应用前景,例如:智能语音助手、语音情感识别、语音翻译、语音内容理解等。通过提高SLM对语音的理解能力,DeSTA可以使这些应用更加智能、更加人性化。此外,DeSTA还可以用于开发新的语音交互应用,例如:基于语音的教育、医疗等服务。
📄 摘要(原文)
Recent speech language models (SLMs) typically incorporate pre-trained speech models to extend the capabilities from large language models (LLMs). In this paper, we propose a Descriptive Speech-Text Alignment approach that leverages speech captioning to bridge the gap between speech and text modalities, enabling SLMs to interpret and generate comprehensive natural language descriptions, thereby facilitating the capability to understand both linguistic and non-linguistic features in speech. Enhanced with the proposed approach, our model demonstrates superior performance on the Dynamic-SUPERB benchmark, particularly in generalizing to unseen tasks. Moreover, we discover that the aligned model exhibits a zero-shot instruction-following capability without explicit speech instruction tuning. These findings highlight the potential to reshape instruction-following SLMs by incorporating rich, descriptive speech captions.