OutlierTune: Efficient Channel-Wise Quantization for Large Language Models
作者: Jinguang Wang, Yuexi Yin, Haifeng Sun, Qi Qi, Jingyu Wang, Zirui Zhuang, Tingting Yang, Jianxin Liao
分类: cs.CL
发布日期: 2024-06-27
💡 一句话要点
OutlierTune:面向大语言模型的高效通道量化方法,提升INT6量化精度与效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 后训练量化 激活值量化 INT6量化 硬件效率 模型压缩 推理加速
📋 核心要点
- 现有激活值量化方法(如逐token或逐张量量化)难以同时保证大语言模型的精度和硬件效率。
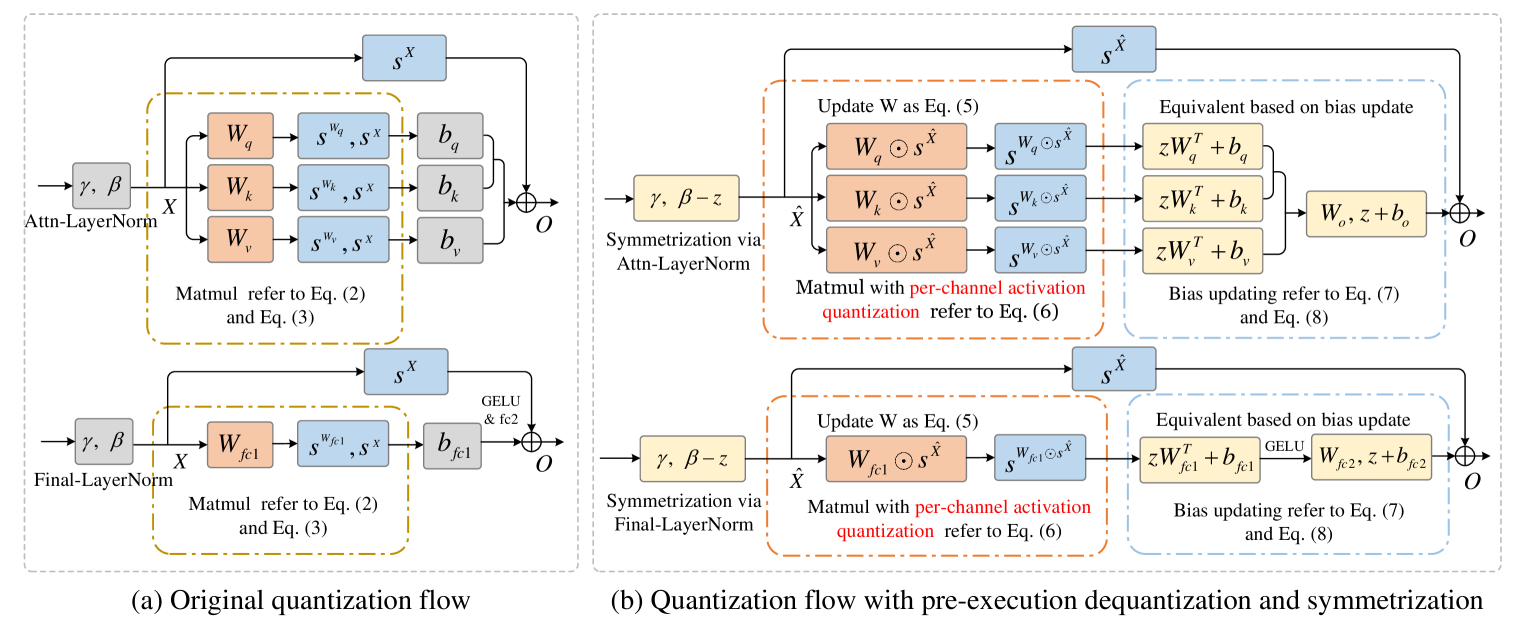
- OutlierTune通过预执行反量化更新模型权重,避免了逐通道量化的额外计算开销,并采用对称化减少量化差异。
- 实验表明,OutlierTune在多个任务上优于现有方法,并能将INT6量化提升到与FP16相同的水平,同时加速并减少内存占用。
📝 摘要(中文)
由于结构化异常值的存在,量化大语言模型(LLM)的激活值一直是一个巨大的挑战。现有方法大多侧重于激活值的逐token或逐张量量化,难以兼顾精度和硬件效率。为了解决这个问题,我们提出OutlierTune,一种高效的逐通道后训练量化(PTQ)方法,用于量化LLM的激活值。OutlierTune包含两个组成部分:预执行反量化和对称化。预执行反量化通过激活缩放因子更新模型权重,避免了逐通道激活量化带来的内部缩放和昂贵的额外计算开销。对称化通过确保不同激活通道之间平衡的数值范围,进一步减少了权重更新引起的量化差异。OutlierTune易于实现且具有硬件效率,在推理过程中几乎不引入额外的计算开销。大量实验表明,所提出的框架在多个不同任务上优于现有方法。该框架展示了更好的泛化能力,将指令调优LLM(如OPT-IML)的Int6量化提升到与半精度(FP16)相同的水平。此外,我们已经证明,所提出的框架比FP16实现快1.48倍,同时减少了大约2倍的内存使用。
🔬 方法详解
问题定义:大语言模型激活值的量化面临精度和效率的挑战。现有方法如逐token或逐tensor量化,无法有效处理激活值中的结构化异常值,导致量化精度下降,同时引入额外的计算开销,影响硬件效率。
核心思路:OutlierTune的核心思路是通过预先将激活值的缩放因子融入到模型权重中,从而避免在推理过程中进行昂贵的逐通道缩放操作。此外,通过对称化处理,平衡不同通道的数值范围,减少量化误差。
技术框架:OutlierTune主要包含两个阶段:预执行反量化和对称化。首先,预执行反量化阶段将激活值的缩放因子预先应用到模型权重上,消除推理时的额外计算负担。然后,对称化阶段调整激活值的范围,使其在零点附近对称,从而减少量化误差。整个过程是后训练量化(PTQ),不需要重新训练模型。
关键创新:OutlierTune的关键创新在于预执行反量化,它将激活值的量化操作提前到权重更新阶段,避免了推理时的逐通道缩放,显著提高了硬件效率。此外,对称化处理进一步提升了量化精度。与现有方法相比,OutlierTune在保证精度的同时,显著降低了计算开销。
关键设计:OutlierTune的关键设计在于如何有效地将激活值的缩放因子融入到模型权重中,以及如何进行对称化处理以减少量化误差。具体来说,缩放因子通过简单的矩阵乘法更新权重。对称化处理则通过调整激活值的范围来实现,确保其在零点附近对称。
🖼️ 关键图片


📊 实验亮点
OutlierTune在多个任务上取得了显著的性能提升。实验结果表明,该方法能够将指令调优LLM(如OPT-IML)的Int6量化提升到与FP16相同的水平。此外,OutlierTune比FP16实现快1.48倍,同时减少了大约2倍的内存使用,展示了其在效率和精度上的优势。
🎯 应用场景
OutlierTune可广泛应用于大语言模型的部署和推理加速,尤其是在资源受限的边缘设备上。通过降低内存占用和提高计算效率,该方法能够使大语言模型在移动设备、嵌入式系统等平台上运行,从而推动人工智能在更广泛领域的应用,例如智能助手、自然语言处理等。
📄 摘要(原文)
Quantizing the activations of large language models (LLMs) has been a significant challenge due to the presence of structured outliers. Most existing methods focus on the per-token or per-tensor quantization of activations, making it difficult to achieve both accuracy and hardware efficiency. To address this problem, we propose OutlierTune, an efficient per-channel post-training quantization (PTQ) method for the activations of LLMs. OutlierTune consists of two components: pre-execution of dequantization and symmetrization. The pre-execution of dequantization updates the model weights by the activation scaling factors, avoiding the internal scaling and costly additional computational overheads brought by the per-channel activation quantization. The symmetrization further reduces the quantization differences arising from the weight updates by ensuring the balanced numerical ranges across different activation channels. OutlierTune is easy to implement and hardware-efficient, introducing almost no additional computational overheads during the inference. Extensive experiments show that the proposed framework outperforms existing methods across multiple different tasks. Demonstrating better generalization, this framework improves the Int6 quantization of the instruction-tuning LLMs, such as OPT-IML, to the same level as half-precision (FP16). Moreover, we have shown that the proposed framework is 1.48x faster than the FP16 implementation while reducing approximately 2x memory usage.