Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
作者: Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lefèvre
分类: cs.CL, cs.AI, cs.HC
发布日期: 2024-06-26
备注: Updated version of a paper originally submitted at SIGDIAL 2023
💡 一句话要点
提出基于角色扮演的零样本提示方法,提升大语言模型在开放域人机对话中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放域对话 大语言模型 零样本学习 角色扮演 人机交互
📋 核心要点
- 现有开放域对话智能体通常采用问答形式,缺乏真实对话的互动性,且微调成本高昂,语言支持有限。
- 本文提出角色扮演零样本提示方法,通过设计特定的提示语,引导大语言模型扮演特定角色,从而实现更自然的对话。
- 实验表明,该方法结合Vicuna模型,在法语对话任务中,性能可与微调模型媲美甚至超越,验证了其有效性。
📝 摘要(中文)
本文提出了一种利用角色扮演零样本提示的高效且经济的开放域对话智能体创建方法,该方法基于能够遵循指令的多语言大语言模型。我们设计了一个提示系统,结合指令遵循模型Vicuna,生成的对话智能体在法语的两个不同任务中,其表现能够媲美甚至超越微调模型的人工评估结果。该方法为开放域对话提供了一种无需大量数据微调,即可快速构建高质量对话系统的有效途径。
🔬 方法详解
问题定义:现有开放域对话系统主要依赖于问答形式,缺乏真实对话的流畅性和互动性。为了提升对话能力,通常需要在大规模数据集上进行微调,但这不仅成本高昂,而且通常只支持少数几种语言。因此,如何以更经济高效的方式提升大语言模型在开放域对话中的表现是一个关键问题。
核心思路:本文的核心思路是利用角色扮演的零样本提示。通过精心设计的提示语,引导大语言模型扮演特定的角色,从而激发模型在特定领域或风格下的对话能力。这种方法无需额外的微调数据,即可使模型表现出更自然、更具个性化的对话风格。
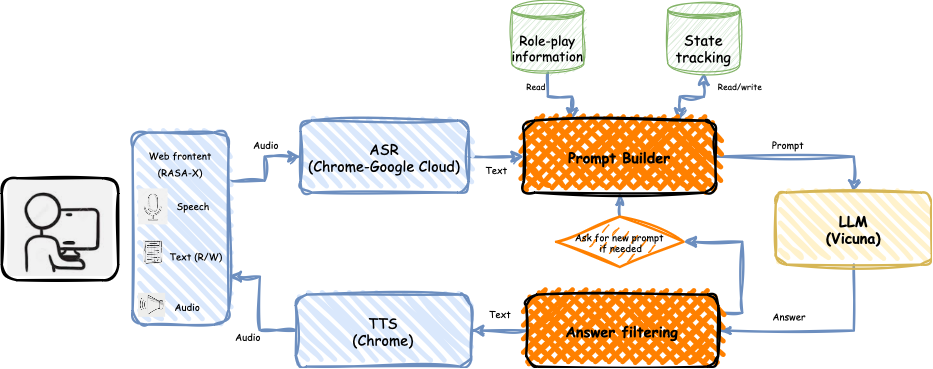
技术框架:该方法主要包含两个核心组件:一是指令遵循的大语言模型,例如Vicuna;二是角色扮演提示系统。首先,定义对话场景和角色,并设计相应的提示语,例如“你是一个友善的客服机器人,负责回答用户关于产品的问题”。然后,将提示语与用户输入拼接,输入到大语言模型中,生成回复。整个过程无需任何训练数据。
关键创新:该方法最重要的创新点在于将角色扮演的概念引入到零样本提示中。与传统的提示方法相比,角色扮演提示能够更有效地引导模型生成符合特定场景和风格的回复,从而显著提升对话的质量和自然度。这种方法无需微调,即可实现媲美甚至超越微调模型的效果。
关键设计:关键设计在于提示语的设计。提示语需要清晰地定义角色、场景和任务,并提供足够的上下文信息,以便模型能够准确理解用户的意图并生成合适的回复。此外,还需要根据不同的角色和场景,调整提示语的措辞和风格,以获得最佳的对话效果。论文中可能包含一些提示语设计的具体示例,但具体细节未知。
🖼️ 关键图片

📊 实验亮点
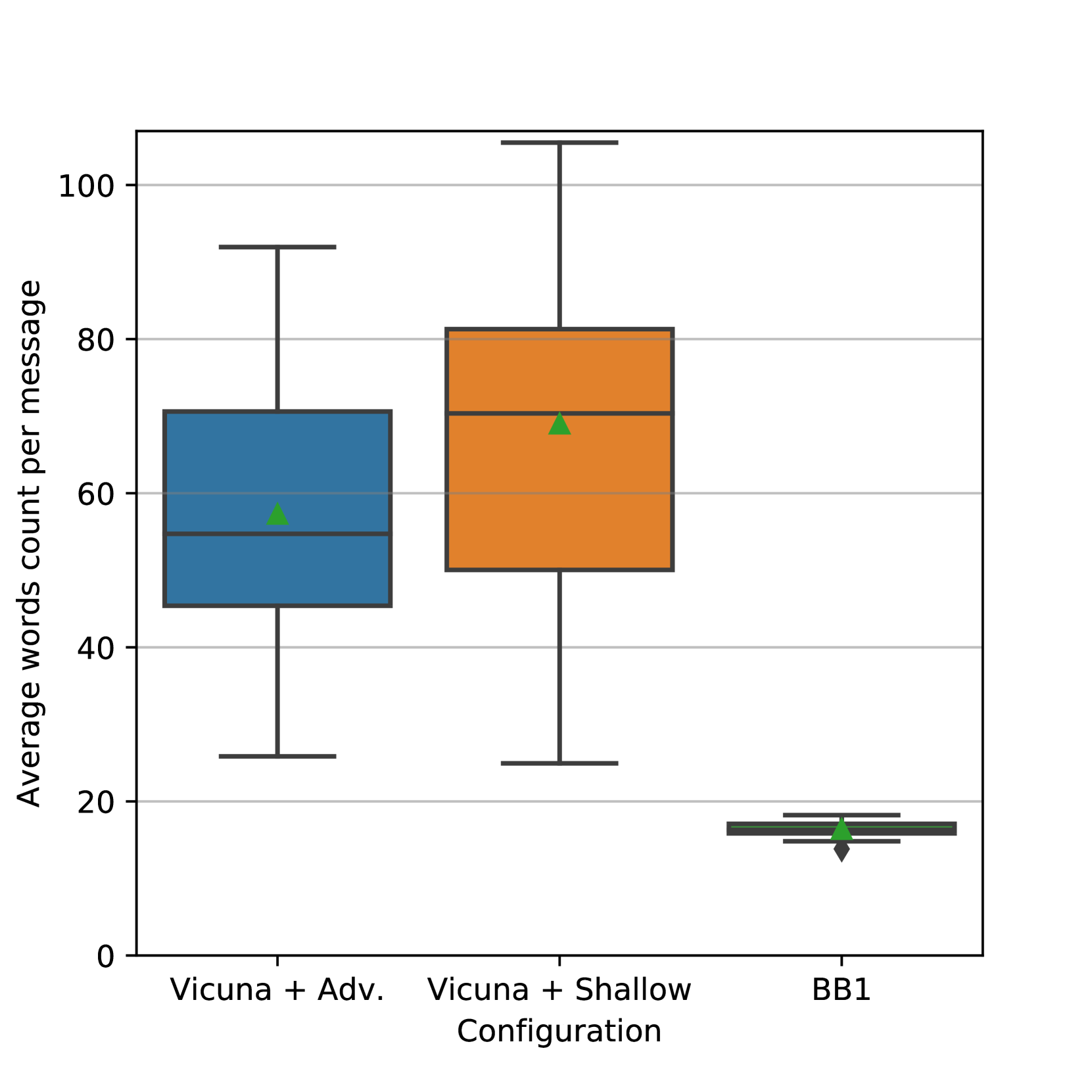
实验结果表明,基于角色扮演零样本提示的Vicuna模型在法语对话任务中,其表现能够媲美甚至超越微调模型的人工评估结果。这表明该方法在无需大量数据微调的情况下,即可有效提升大语言模型在开放域对话中的表现,具有重要的实际意义。
🎯 应用场景
该研究成果可广泛应用于智能客服、虚拟助手、教育辅导等领域。通过角色扮演零样本提示,可以快速构建各种具有特定风格和专业知识的对话智能体,降低开发成本,提升用户体验。未来,该方法有望应用于更多语言和领域,实现更智能、更个性化的人机交互。
📄 摘要(原文)
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.