Do LLMs dream of elephants (when told not to)? Latent concept association and associative memory in transformers
作者: Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, Bryon Aragam
分类: cs.CL, cs.LG, stat.ML
发布日期: 2024-06-26 (更新: 2024-11-27)
备注: NeurIPS 2024
💡 一句话要点
研究发现LLM具有联想记忆特性,易受上下文操纵,并从理论上分析了Transformer的记忆机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 联想记忆 Transformer 自注意力机制 事实检索 上下文学习
📋 核心要点
- 大型语言模型能够存储和检索事实,但这种能力易受上下文影响,即使事实本身没有改变。
- 该研究提出LLM可能具有联想记忆的特性,上下文中的token作为线索触发事实检索,类似于联想记忆模型。
- 通过理论分析和实验验证,证明Transformer利用自注意力和值矩阵实现联想记忆功能。
📝 摘要(中文)
大型语言模型(LLM)具备存储和回忆事实的能力。通过对开源模型的实验,我们观察到这种检索事实的能力很容易受到上下文改变的操纵,即使不改变其事实意义。这些发现表明,LLM的行为可能类似于联想记忆模型,其中上下文中的某些token充当检索事实的线索。我们通过研究Transformer(LLM的构建块)如何完成此类记忆任务,从数学上探索了这一特性。我们研究了一个简单的潜在概念关联问题,使用单层Transformer,并在理论上和经验上证明,Transformer使用自注意力收集信息,并使用值矩阵进行联想记忆。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)中事实检索能力易受上下文操纵的现象。现有方法缺乏对这种现象的深入理解,未能解释LLM如何利用上下文信息进行联想记忆,以及Transformer架构在其中的作用。
核心思路:论文的核心思路是将LLM的行为类比为联想记忆模型,认为上下文中的token充当线索,触发对相关事实的检索。通过研究Transformer架构,特别是自注意力和值矩阵,来揭示LLM实现联想记忆的机制。
技术框架:论文采用单层Transformer模型来研究潜在概念关联问题。该模型接收包含上下文信息的输入,通过自注意力机制提取相关特征,并利用值矩阵存储和检索关联的事实。研究人员通过理论分析和实验验证,证明了该模型能够实现联想记忆功能。
关键创新:论文的关键创新在于从联想记忆的角度解释LLM的事实检索行为,并从理论上分析了Transformer架构在实现联想记忆中的作用。该研究揭示了自注意力和值矩阵在信息收集和记忆存储中的重要性。
关键设计:论文使用单层Transformer模型,重点关注自注意力机制和值矩阵。研究人员设计了特定的实验场景,例如潜在概念关联问题,来评估模型的联想记忆能力。通过调整上下文信息,观察模型的事实检索行为,并分析自注意力权重和值矩阵的变化。
🖼️ 关键图片

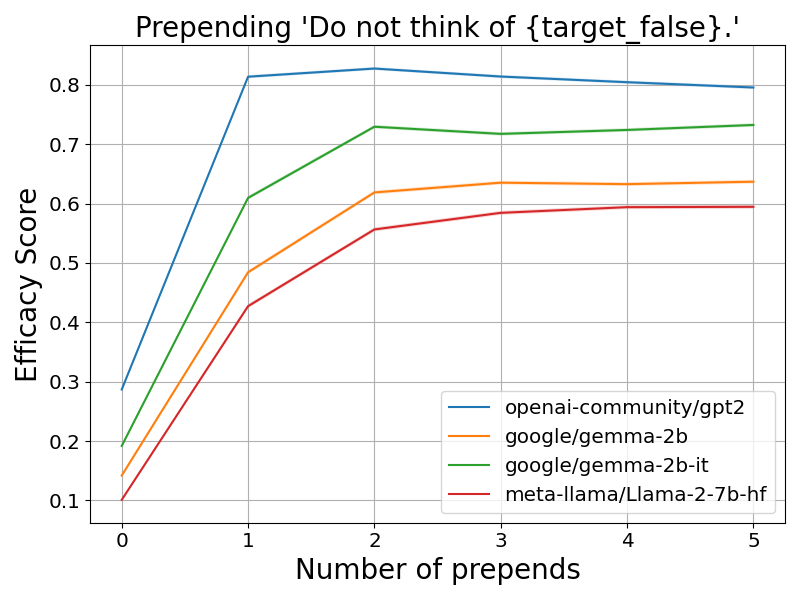
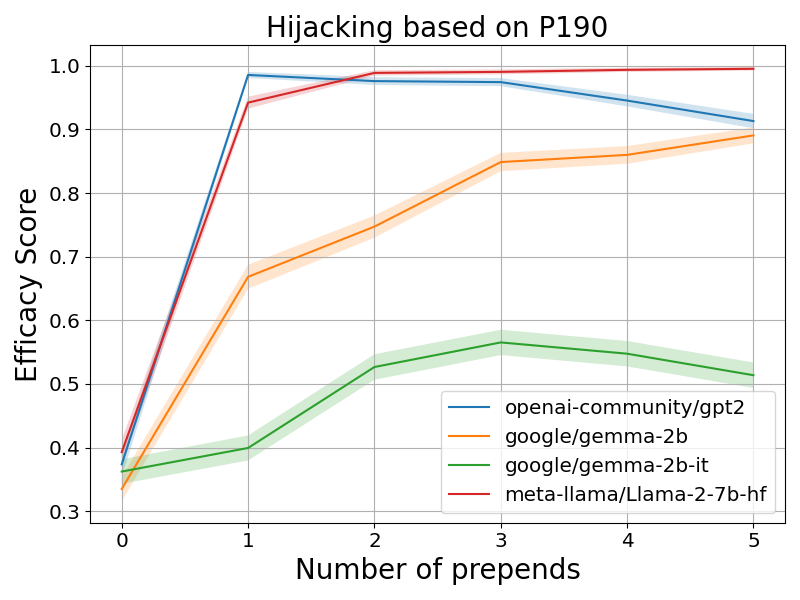
📊 实验亮点
研究通过实验证明,即使不改变事实的含义,仅仅改变上下文信息就能显著影响LLM的事实检索结果。理论分析表明,Transformer利用自注意力机制从上下文中提取相关信息,并使用值矩阵存储和检索关联的事实,从而实现联想记忆功能。
🎯 应用场景
该研究成果可应用于提升LLM的鲁棒性和可控性,例如,通过优化上下文设计,减少模型对无关信息的依赖,提高事实检索的准确性。此外,该研究有助于开发更高效的知识存储和检索机制,为构建更智能的AI系统提供理论基础。
📄 摘要(原文)
Large Language Models (LLMs) have the capacity to store and recall facts. Through experimentation with open-source models, we observe that this ability to retrieve facts can be easily manipulated by changing contexts, even without altering their factual meanings. These findings highlight that LLMs might behave like an associative memory model where certain tokens in the contexts serve as clues to retrieving facts. We mathematically explore this property by studying how transformers, the building blocks of LLMs, can complete such memory tasks. We study a simple latent concept association problem with a one-layer transformer and we show theoretically and empirically that the transformer gathers information using self-attention and uses the value matrix for associative memory.