FactFinders at CheckThat! 2024: Refining Check-worthy Statement Detection with LLMs through Data Pruning
作者: Yufeng Li, Rrubaa Panchendrarajan, Arkaitz Zubiaga
分类: cs.CL
发布日期: 2024-06-26
💡 一句话要点
通过数据剪枝优化LLM,提升政治文本中待核实陈述的检测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 大型语言模型 数据剪枝 政治文本分析 check-worthiness estimation
📋 核心要点
- 现有方法在识别政治文本中值得核实的陈述方面存在挑战,尤其是在有效利用开源LLM方面。
- 论文提出一种两步数据剪枝方法,旨在自动识别高质量训练数据,从而提升LLM在check-worthiness estimation任务中的性能。
- 实验结果表明,该方法仅使用约44%的训练数据即可达到具有竞争力的性能,并在CheckThat! 2024英语任务中排名第一。
📝 摘要(中文)
社交媒体和互联网上信息的快速传播给事实核查带来了重大挑战,尤其是在识别值得事实核查的声明方面,即从大量句子中过滤出需要事实核查的声明。这一挑战强调了确定声明优先级的必要性,特别是哪些声明值得进行事实核查。尽管近年来该领域取得了进展,但大型语言模型(LLM)的应用,如GPT,直到最近才引起研究的关注。然而,许多开源LLM仍未得到充分探索。因此,本研究调查了八个著名的开源LLM,通过微调和提示工程来识别政治文本中值得核实的陈述。此外,我们提出了一种两步数据剪枝方法,以自动识别高质量的训练数据实例,从而实现有效的学习。通过在CheckThat! 2024的英语数据集上进行的评估,证明了我们方法的有效性。此外,通过数据剪枝进行的实验表明,仅使用约44%的训练数据即可实现具有竞争力的性能。我们的团队在英语的check-worthiness estimation任务中排名第一。
🔬 方法详解
问题定义:论文旨在解决政治文本中check-worthy statement detection问题,即判断一个陈述是否值得进行事实核查。现有方法,特别是对开源LLM的利用不足,导致性能提升受限,且训练数据质量参差不齐,影响模型效果。
核心思路:论文的核心思路是通过数据剪枝,筛选出高质量的训练数据,从而提高LLM在check-worthiness estimation任务中的性能。通过减少噪声数据的影响,使模型能够更有效地学习关键特征。
技术框架:论文采用两步数据剪枝框架。第一步,使用LLM对训练数据进行初步筛选,去除明显不相关的样本。第二步,基于模型的预测置信度,进一步筛选出置信度较高的样本,保留高质量数据。然后,使用筛选后的数据对开源LLM进行微调,用于check-worthiness estimation。
关键创新:论文的关键创新在于提出的两步数据剪枝方法,该方法能够自动识别并保留高质量的训练数据,从而显著提升LLM的性能。与传统方法相比,该方法无需人工标注,降低了成本,并提高了效率。
关键设计:数据剪枝的第一步使用LLM进行初步筛选,具体实现方式未知。第二步基于模型预测置信度进行筛选,可能涉及设定阈值,只保留置信度高于阈值的样本。微调过程中,可能使用了交叉熵损失函数,并调整了学习率等超参数。具体的网络结构和参数设置未知。
🖼️ 关键图片


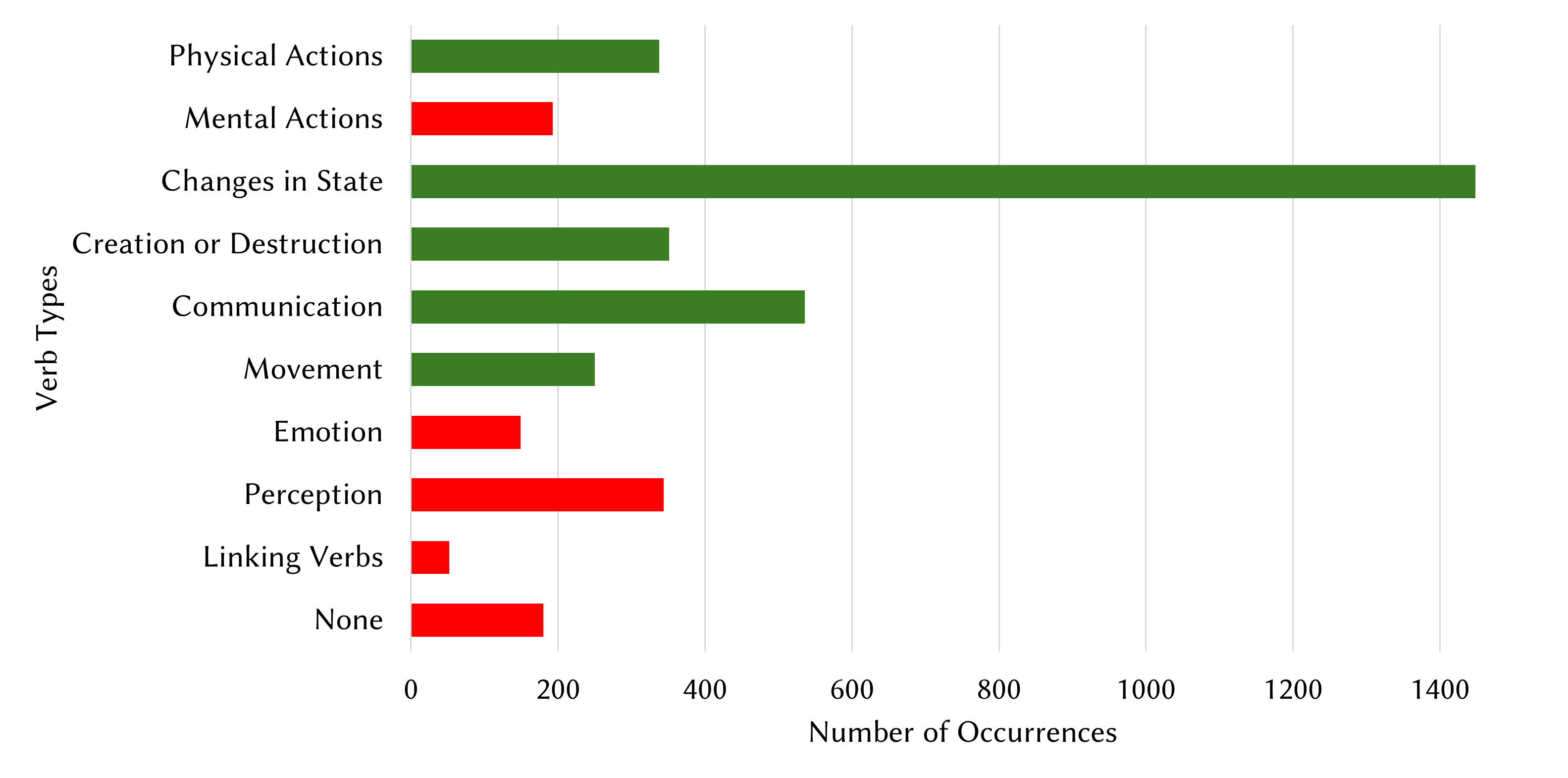
📊 实验亮点
实验结果表明,通过数据剪枝,仅使用约44%的训练数据即可达到具有竞争力的性能,并在CheckThat! 2024英语的check-worthiness estimation任务中排名第一。这表明该方法能够有效提高LLM的性能,并降低训练成本。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,用于自动识别和筛选需要进行事实核查的陈述,从而提高信息质量,减少虚假信息的传播。该方法还可扩展到其他文本分类任务中,具有广泛的应用前景。
📄 摘要(原文)
The rapid dissemination of information through social media and the Internet has posed a significant challenge for fact-checking, among others in identifying check-worthy claims that fact-checkers should pay attention to, i.e. filtering claims needing fact-checking from a large pool of sentences. This challenge has stressed the need to focus on determining the priority of claims, specifically which claims are worth to be fact-checked. Despite advancements in this area in recent years, the application of large language models (LLMs), such as GPT, has only recently drawn attention in studies. However, many open-source LLMs remain underexplored. Therefore, this study investigates the application of eight prominent open-source LLMs with fine-tuning and prompt engineering to identify check-worthy statements from political transcriptions. Further, we propose a two-step data pruning approach to automatically identify high-quality training data instances for effective learning. The efficiency of our approach is demonstrated through evaluations on the English language dataset as part of the check-worthiness estimation task of CheckThat! 2024. Further, the experiments conducted with data pruning demonstrate that competitive performance can be achieved with only about 44\% of the training data. Our team ranked first in the check-worthiness estimation task in the English language.