Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
作者: Simon Münker, Kai Kugler, Achim Rettinger
分类: cs.CL, cs.AI
发布日期: 2024-06-26
备注: 10 pages, 2 tables, 1 figure
💡 一句话要点
利用零样本提示学习,解决德语推特文本的主题标注问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 提示学习 主题标注 德语推特 预训练模型
📋 核心要点
- 社交媒体和新闻分析中,文本数据过滤和标注是常见任务,但传统方法依赖大量人工,效率较低。
- 本文提出一种基于零样本提示学习的方法,利用大型预训练模型,通过文本到文本接口实现自动标注,无需训练数据。
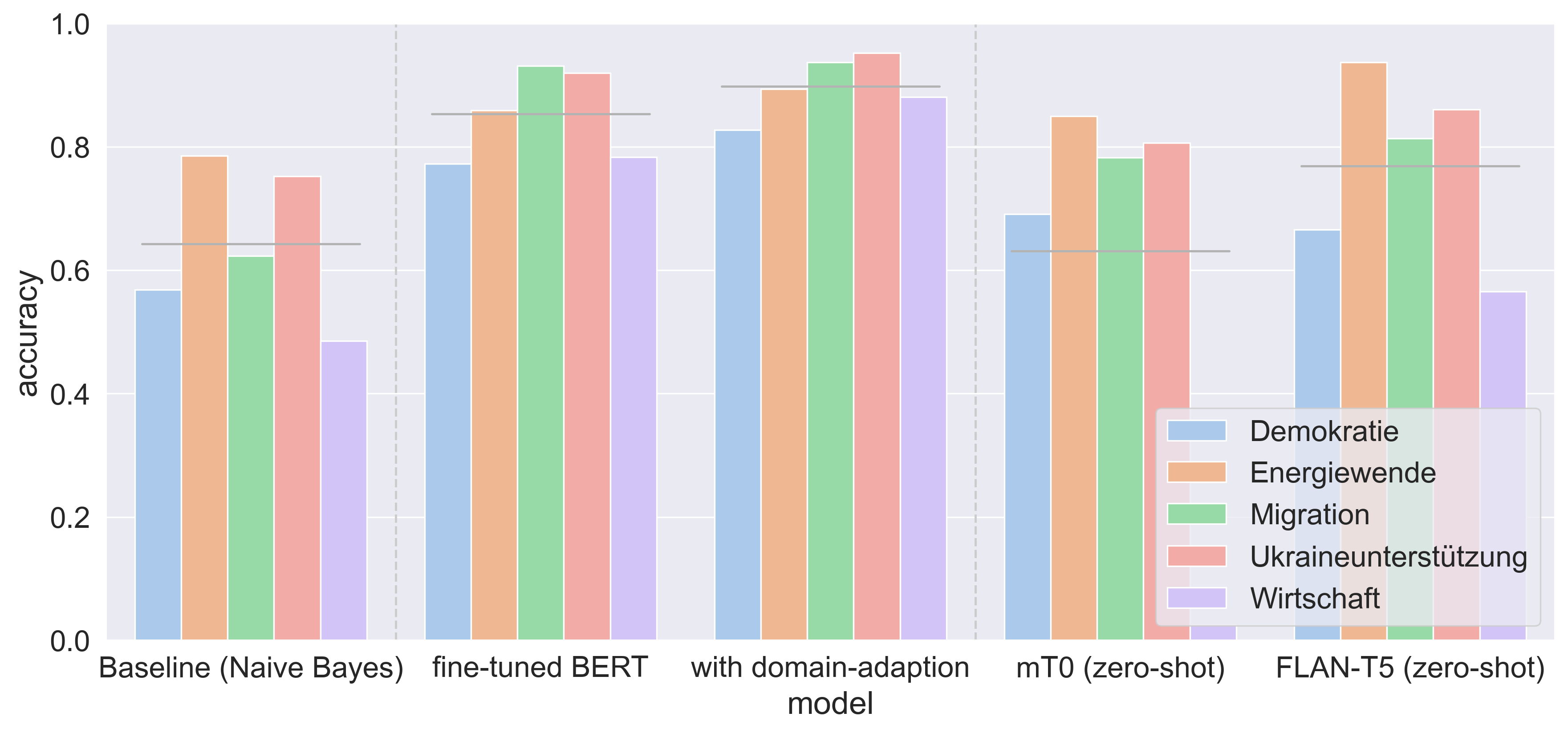
- 实验表明,该方法在德语推特数据上,性能与微调的BERT模型相当,但无需任何标注数据,降低了人工成本。
📝 摘要(中文)
本文探讨了在自然语言处理领域,特别是大型预训练模型取得成功后,如何利用文本到文本的接口,通过书面指导而非训练样本,自动完成文本数据过滤和标注任务。作者在关于欧洲社会和政治危机的德语推特数据上,对这种方法进行了实证测试。通过与人工标注以及朴素贝叶斯和基于BERT的微调/领域自适应等传统分类方法进行比较,结果表明,尽管受到本地计算资源限制,基于提示的方法在模型选择上与微调的BERT相当,且无需任何标注训练数据。研究结果强调了自然语言处理领域正在发生的范式转变,即下游任务的统一以及对预标记训练数据的需求的消除。
🔬 方法详解
问题定义:论文旨在解决德语推特数据的主题标注问题。现有方法,如朴素贝叶斯和基于BERT的微调,需要大量的标注数据进行训练,成本高昂且耗时。此外,针对特定领域(如社会政治危机)的标注数据获取更加困难。
核心思路:论文的核心思路是利用大型预训练语言模型(Foundation Models)的零样本学习能力,通过设计合适的提示(Prompt),引导模型直接生成文本的主题标签,而无需任何训练数据。这种方法依赖于预训练模型强大的语言理解和生成能力,以及提示工程的有效性。
技术框架:整体流程包括以下几个步骤:1) 数据收集:收集关于欧洲社会和政治危机的德语推特数据。2) 提示设计:设计合适的提示模板,例如“这条推文的主题是:”。3) 模型推理:使用大型预训练语言模型,输入推文和提示,生成主题标签。4) 结果评估:将模型生成的主题标签与人工标注结果以及传统分类方法的结果进行比较,评估模型的性能。
关键创新:最重要的技术创新点在于利用零样本提示学习进行主题标注,无需任何标注数据。这与传统的监督学习方法(如BERT微调)形成了鲜明对比,极大地降低了标注成本和时间。此外,该方法也避免了领域自适应的问题,可以直接应用于新的领域。
关键设计:论文的关键设计在于提示模板的选择。不同的提示模板可能会对模型的性能产生显著影响。作者可能尝试了不同的提示模板,并选择了效果最佳的模板。此外,由于本地计算资源有限,作者可能需要对模型进行选择或优化,以保证推理效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于零样本提示学习的方法在德语推特数据上的主题标注性能与微调的BERT模型相当,但无需任何标注数据。这表明大型预训练模型具有强大的零样本学习能力,可以有效地应用于文本分类任务,并降低了标注成本。
🎯 应用场景
该研究成果可广泛应用于社交媒体分析、舆情监控、新闻分类等领域。通过零样本提示学习,可以快速、低成本地对大量文本数据进行主题标注,从而帮助用户更好地理解和分析数据。未来,该方法可以扩展到其他语言和领域,并与其他技术(如主动学习)相结合,进一步提高标注效率和准确性。
📄 摘要(原文)
Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.