RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems
作者: Robert Friel, Masha Belyi, Atindriyo Sanyal
分类: cs.CL, cs.AI
发布日期: 2024-06-25 (更新: 2025-01-16)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
RAGBench:可解释的检索增强生成系统评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG评估 基准数据集 可解释性 行业应用
📋 核心要点
- 现有RAG系统缺乏统一的评估标准和标注数据集,难以进行全面评估,阻碍了其在实际工业场景中的应用。
- RAGBench通过构建大规模、多领域、行业相关的基准数据集,并提出TRACe评估框架,实现了对RAG系统的可解释和可操作的评估。
- 实验表明,现有的基于LLM的RAG评估方法性能不足,而RAGBench结合TRACe框架能够有效提升RAG系统的评估效果。
📝 摘要(中文)
检索增强生成(RAG)已成为将领域特定知识融入大型语言模型(LLM)驱动的面向用户聊天应用程序的标准架构模式。RAG系统的特点是:(1)文档检索器,用于查询领域特定的语料库,以获取与输入查询相关的上下文信息;(2)LLM,用于基于提供的查询和上下文生成响应。然而,由于缺乏统一的评估标准和标注数据集,对RAG系统进行全面评估仍然是一个挑战。为此,我们推出了RAGBench:首个包含10万个示例的大规模RAG基准数据集。它涵盖了五个独特的行业特定领域和各种RAG任务类型。RAGBench示例来源于用户手册等行业语料库,使其与行业应用特别相关。此外,我们形式化了TRACe评估框架:一套可解释且可操作的RAG评估指标,适用于所有RAG领域。我们在https://huggingface.co/datasets/rungalileo/ragbench发布了标注数据集。RAGBench的可解释标签有助于对RAG系统进行全面评估,从而为生产应用程序的持续改进提供可操作的反馈。通过彻底的基准测试,我们发现基于LLM的RAG评估方法难以与在RAG评估任务上微调的RoBERTa模型竞争。我们确定了现有方法的不足之处,并建议采用RAGBench与TRACe来推进RAG评估系统的发展。
🔬 方法详解
问题定义:现有RAG系统的评估缺乏统一的标准和高质量的数据集,导致难以准确衡量RAG系统的性能,尤其是在特定行业领域的应用中。现有的评估方法往往依赖于人工评估或简单的指标,缺乏可解释性和可操作性,难以指导RAG系统的改进。
核心思路:RAGBench的核心思路是构建一个大规模、多领域、行业相关的基准数据集,并提出一套可解释且可操作的评估指标(TRACe),从而实现对RAG系统的全面评估。通过提供高质量的标注数据和明确的评估标准,RAGBench旨在促进RAG系统的研究和发展。
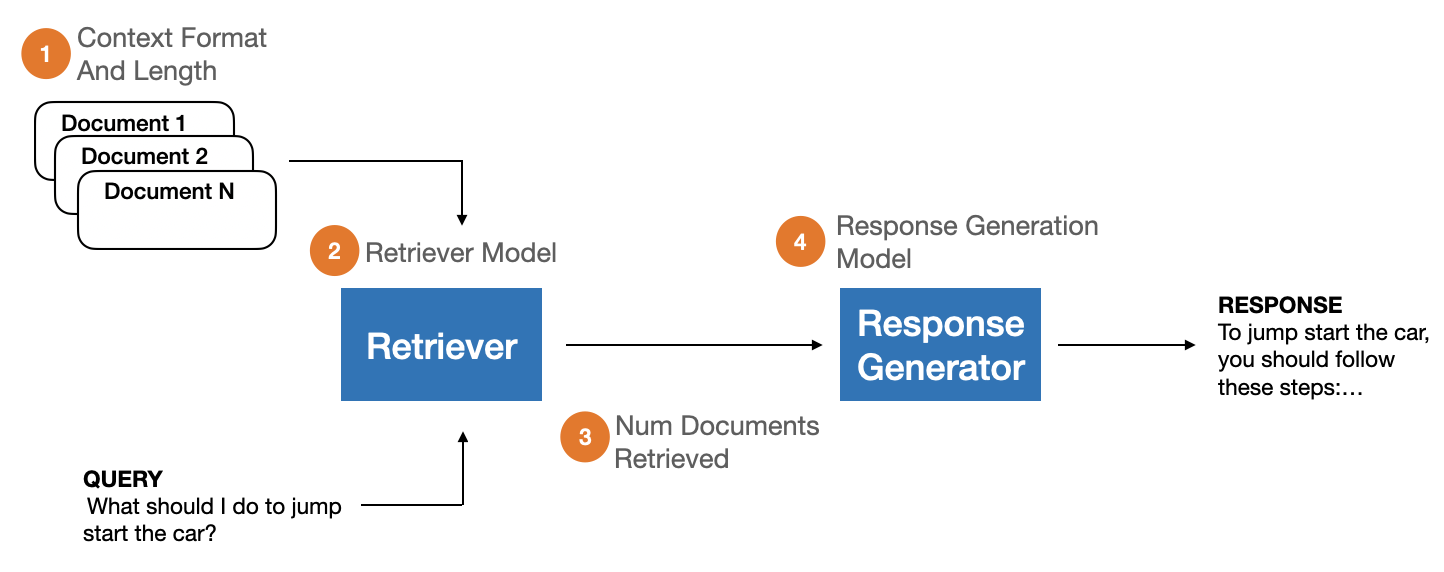
技术框架:RAGBench包含以下主要组成部分:1) 大规模数据集:包含10万个示例,覆盖五个行业特定领域,例如用户手册。2) TRACe评估框架:一套可解释且可操作的RAG评估指标,包括真实性(Truthfulness)、相关性(Relevance)、答案性(Answerability)、一致性(Consistency)和可解释性(Explainability)。3) 基准测试:对现有RAG评估方法进行基准测试,并分析其优缺点。
关键创新:RAGBench的主要创新在于其大规模、多领域、行业相关的数据集,以及TRACe评估框架。与现有的RAG评估方法相比,RAGBench提供了更全面、更可解释、更可操作的评估结果,能够更好地指导RAG系统的改进。TRACe框架的设计也考虑了RAG系统的各个关键方面,例如生成答案的真实性和相关性。
关键设计:RAGBench数据集的构建采用了多种数据收集和标注方法,以确保数据的质量和多样性。TRACe评估框架中的各项指标都经过精心设计,以反映RAG系统的不同性能方面。例如,真实性指标衡量生成答案是否与原始文档一致,相关性指标衡量检索到的文档是否与查询相关。论文中没有详细说明具体的参数设置、损失函数或网络结构,因为RAGBench主要关注数据集和评估框架的设计,而不是特定的RAG模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的基于LLM的RAG评估方法在RAGBench数据集上的表现不佳,难以与微调的RoBERTa模型竞争。这表明现有的评估方法可能存在偏差或不足,无法准确衡量RAG系统的性能。RAGBench的发布和TRACe评估框架的提出,为RAG系统的评估提供了一个更可靠和全面的解决方案。
🎯 应用场景
RAGBench可广泛应用于各种需要检索增强生成技术的领域,例如智能客服、知识问答、文档摘要、报告生成等。它可以帮助开发者评估和改进RAG系统,提高其在特定领域的性能和可靠性。通过提供可解释的评估结果,RAGBench还可以帮助用户更好地理解RAG系统的行为,从而建立信任。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has become a standard architectural pattern for incorporating domain-specific knowledge into user-facing chat applications powered by Large Language Models (LLMs). RAG systems are characterized by (1) a document retriever that queries a domain-specific corpus for context information relevant to an input query, and (2) an LLM that generates a response based on the provided query and context. However, comprehensive evaluation of RAG systems remains a challenge due to the lack of unified evaluation criteria and annotated datasets. In response, we introduce RAGBench: the first comprehensive, large-scale RAG benchmark dataset of 100k examples. It covers five unique industry-specific domains and various RAG task types. RAGBench examples are sourced from industry corpora such as user manuals, making it particularly relevant for industry applications. Further, we formalize the TRACe evaluation framework: a set of explainable and actionable RAG evaluation metrics applicable across all RAG domains. We release the labeled dataset at https://huggingface.co/datasets/rungalileo/ragbench. RAGBench explainable labels facilitate holistic evaluation of RAG systems, enabling actionable feedback for continuous improvement of production applications. Thorough extensive benchmarking, we find that LLM-based RAG evaluation methods struggle to compete with a finetuned RoBERTa model on the RAG evaluation task. We identify areas where existing approaches fall short and propose the adoption of RAGBench with TRACe towards advancing the state of RAG evaluation systems.