PAFT: A Parallel Training Paradigm for Effective LLM Fine-Tuning
作者: Shiva Kumar Pentyala, Zhichao Wang, Bin Bi, Kiran Ramnath, Xiang-Bo Mao, Regunathan Radhakrishnan, Sitaram Asur, Na, Cheng
分类: cs.CL
发布日期: 2024-06-25
💡 一句话要点
PAFT:一种高效LLM微调的并行训练范式,解决对齐税问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 并行训练 偏好对齐 参数融合 稀疏化 对齐税
📋 核心要点
- 现有LLM微调方法采用串行SFT和偏好对齐,导致性能下降的“对齐税”问题。
- PAFT并行执行SFT和偏好对齐,然后通过参数融合将两个模型合并,避免串行训练的性能损失。
- 实验表明,PAFT方法在HuggingFace Open LLM排行榜上获得第一名,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中表现出卓越的能力。LLM通常经过监督微调(SFT),然后进行偏好对齐,以便在下游应用中使用。然而,这种顺序训练流程会导致对齐税,从而降低LLM的性能。本文介绍了一种新的并行训练范式PAFT,用于有效的LLM微调,它使用相同的预训练模型在各自的数据集上独立执行SFT和偏好对齐(例如,DPO和ORPO等)。然后,通过参数融合将SFT产生的模型和偏好对齐产生的模型合并为最终模型,以用于下游应用。这项工作揭示了重要的发现,即像DPO这样的偏好对齐自然会导致稀疏模型,而SFT会导致自然稠密模型,需要对其进行稀疏化才能进行有效的模型合并。本文介绍了一种有效的干扰解决机制,通过稀疏化delta参数来减少冗余。通过这种新的训练范式获得的LLM在HuggingFace Open LLM排行榜上获得了第一名。全面的评估表明了并行训练范式的有效性。
🔬 方法详解
问题定义:现有的大型语言模型微调方法通常采用串行的监督微调(SFT)和偏好对齐(例如DPO)流程。这种串行的训练方式会导致“对齐税”问题,即在偏好对齐过程中,模型会牺牲一部分在SFT阶段学到的知识,从而降低整体性能。因此,如何避免或减少“对齐税”是本文要解决的关键问题。
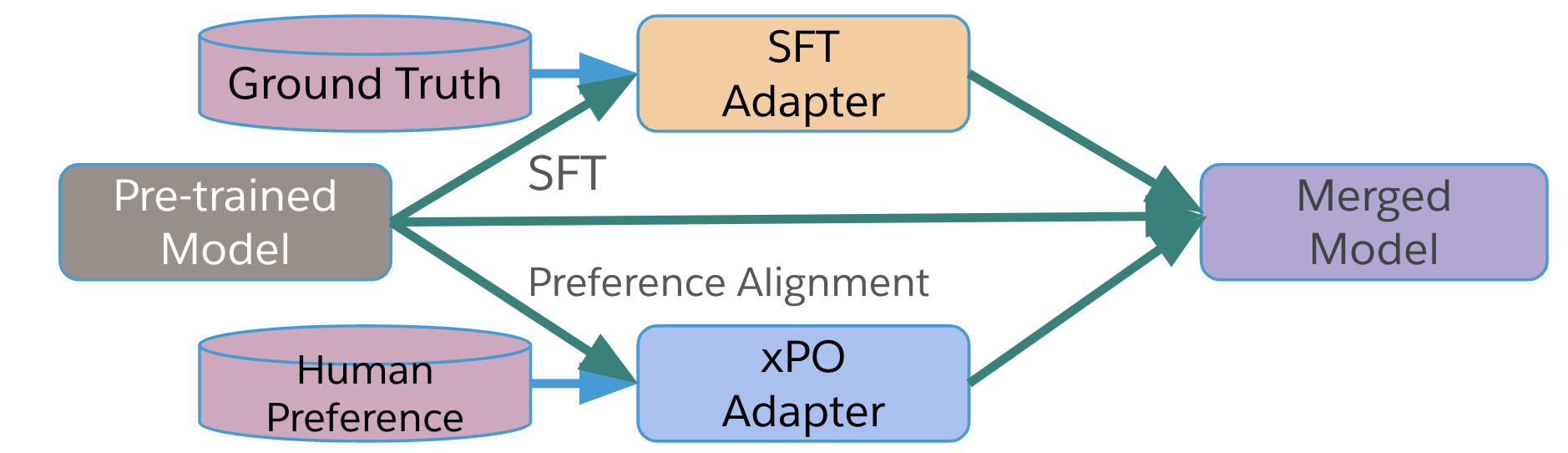
核心思路:PAFT的核心思路是并行地进行SFT和偏好对齐,而不是串行地进行。通过并行训练,SFT和偏好对齐可以独立地优化模型,避免了相互干扰。然后,通过参数融合的方式将两个独立训练的模型合并成一个最终模型。这样既保留了SFT阶段学到的知识,又实现了偏好对齐的目标。
技术框架:PAFT的整体框架包括三个主要步骤:1) 使用预训练模型,分别在SFT数据集和偏好对齐数据集上进行独立的训练,得到两个模型。2) 对SFT模型和偏好对齐模型进行分析,发现SFT模型是稠密的,而偏好对齐模型是稀疏的。3) 对SFT模型的参数进行稀疏化,并使用参数融合技术将两个模型合并成一个最终模型。
关键创新:PAFT的关键创新在于提出了并行训练的范式,以及针对SFT和偏好对齐模型特性进行参数稀疏化和融合的方法。通过并行训练,避免了串行训练中的“对齐税”问题。通过参数稀疏化,减少了模型冗余,提高了融合效果。
关键设计:在参数融合方面,论文提出了一种有效的干扰解决机制,通过稀疏化delta参数来减少冗余。具体来说,首先计算SFT模型和偏好对齐模型之间的参数差异(delta参数),然后对delta参数进行稀疏化处理,最后将稀疏化后的delta参数加回到SFT模型中,得到最终模型。具体的稀疏化策略和融合权重等参数设置在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
PAFT方法在HuggingFace Open LLM Leaderboard上取得了第一名的成绩,证明了其有效性。具体的性能提升数据(例如,在特定任务上的准确率、召回率等)需要在论文中查找。该方法通过并行训练和参数融合,显著提高了LLM的微调效果,优于传统的串行训练方法。
🎯 应用场景
PAFT方法可广泛应用于各种需要对大型语言模型进行微调的场景,例如对话系统、文本生成、问答系统等。通过并行训练,可以显著提高微调效率和模型性能,从而加速LLM在实际应用中的落地。该方法尤其适用于需要同时考虑模型通用性和特定任务偏好的场景。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable abilities in diverse natural language processing (NLP) tasks. The LLMs generally undergo supervised fine-tuning (SFT) followed by preference alignment to be usable in downstream applications. However, this sequential training pipeline leads to alignment tax that degrades the LLM performance. This paper introduces PAFT, a new PArallel training paradigm for effective LLM Fine-Tuning, which independently performs SFT and preference alignment (e.g., DPO and ORPO, etc.) with the same pre-trained model on respective datasets. The model produced by SFT and the model from preference alignment are then merged into a final model by parameter fusing for use in downstream applications. This work reveals important findings that preference alignment like DPO naturally results in a sparse model while SFT leads to a natural dense model which needs to be sparsified for effective model merging. This paper introduces an effective interference resolution which reduces the redundancy by sparsifying the delta parameters. The LLM resulted from the new training paradigm achieved Rank #1 on the HuggingFace Open LLM Leaderboard. Comprehensive evaluation shows the effectiveness of the parallel training paradigm.