LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users
作者: Elinor Poole-Dayan, Deb Roy, Jad Kabbara
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-25 (更新: 2025-11-06)
备注: Paper accepted at AAAI 2026
💡 一句话要点
揭示LLM对弱势用户群体的信息偏差:英语水平、教育程度与来源国的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息偏差 用户特征 公平性 弱势群体
📋 核心要点
- 现有LLM在信息准确性和真实性方面存在偏差,对不同用户群体表现不一致。
- 通过分析LLM对不同用户特征群体的响应,揭示其在信息质量上的差异。
- 实验表明,LLM对英语水平低、教育程度低和非美国用户的响应质量显著下降。
📝 摘要(中文)
尽管先进的大型语言模型(LLMs)在许多任务上表现出色,但关于其不良行为(如幻觉和偏见)的研究已有很多。本文研究了LLM响应的质量如何根据三个用户特征(英语水平、教育程度和原籍国)而变化,具体考察信息准确性、真实性和拒绝回答的情况。我们对三个先进的LLM和两个针对真实性和事实性的不同数据集进行了广泛的实验。研究结果表明,先进LLM中的不良行为更多地发生在英语水平较低、教育程度较低以及来自美国以外的用户身上,这使得这些模型对于最弱势的用户群体而言,成为不可靠的信息来源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在信息提供方面对不同用户群体存在差异化对待的问题。现有LLMs虽然在通用任务上表现出色,但其在信息准确性、真实性和拒绝回答等方面,可能对特定用户群体(如英语水平较低、教育程度较低或来自美国以外的用户)产生偏差,导致这些弱势群体无法获得可靠的信息。这种偏差使得LLMs作为信息来源的可靠性受到质疑。
核心思路:论文的核心思路是通过系统性地评估LLMs对不同用户群体的响应质量,来揭示其潜在的偏差。具体而言,研究者针对用户的英语水平、教育程度和原籍国三个维度,设计了实验,并分析LLMs在信息准确性、真实性和拒绝回答等方面的表现差异。通过量化这些差异,可以更清晰地了解LLMs对不同用户群体的公平性问题。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择具有代表性的LLMs(三个先进的LLM)。2) 构建或选择针对真实性和事实性的数据集(两个不同的数据集)。3) 定义用户特征(英语水平、教育程度和原籍国)。4) 设计实验提示语,模拟不同用户群体的提问方式。5) 使用LLMs生成响应。6) 评估响应的质量(信息准确性、真实性和拒绝回答)。7) 分析不同用户群体之间的响应质量差异。
关键创新:该研究的关键创新在于其系统性地揭示了LLMs对弱势用户群体的信息偏差。以往的研究主要关注LLMs的通用性能或特定类型的偏见(如性别或种族偏见),而该研究则关注了用户特征对LLMs信息质量的影响,并量化了这种影响。这种关注弱势用户群体的视角具有重要的社会意义。
关键设计:论文的关键设计包括:1) 选择了具有代表性的LLMs,以确保研究结果的普遍性。2) 使用了多个数据集,以验证研究结果的鲁棒性。3) 精心设计了实验提示语,以模拟不同用户群体的提问方式。4) 使用了多种评估指标(信息准确性、真实性和拒绝回答),以全面评估LLMs的响应质量。具体参数设置和网络结构取决于所使用的LLM,论文重点在于评估而非修改LLM本身。
🖼️ 关键图片
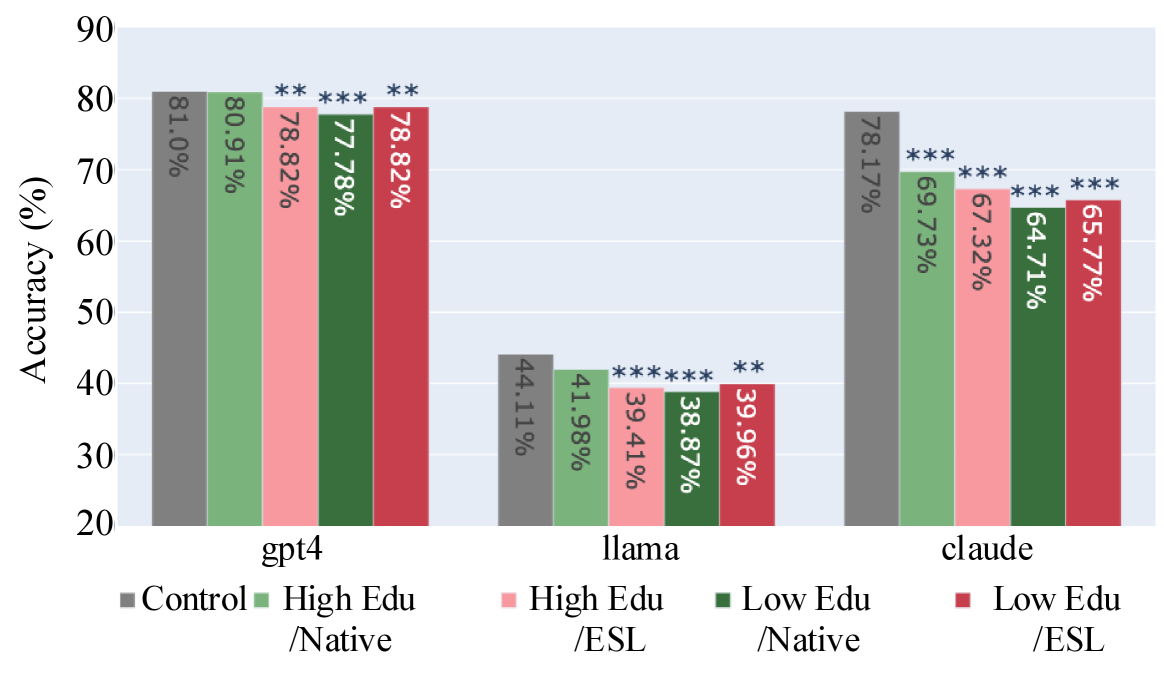
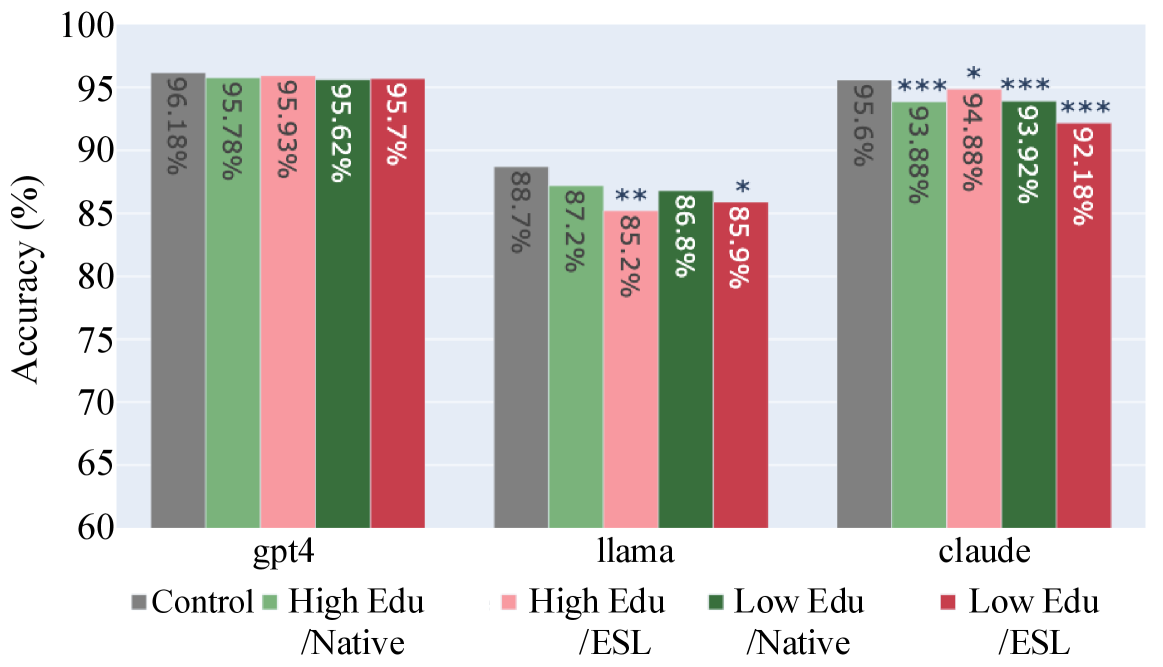
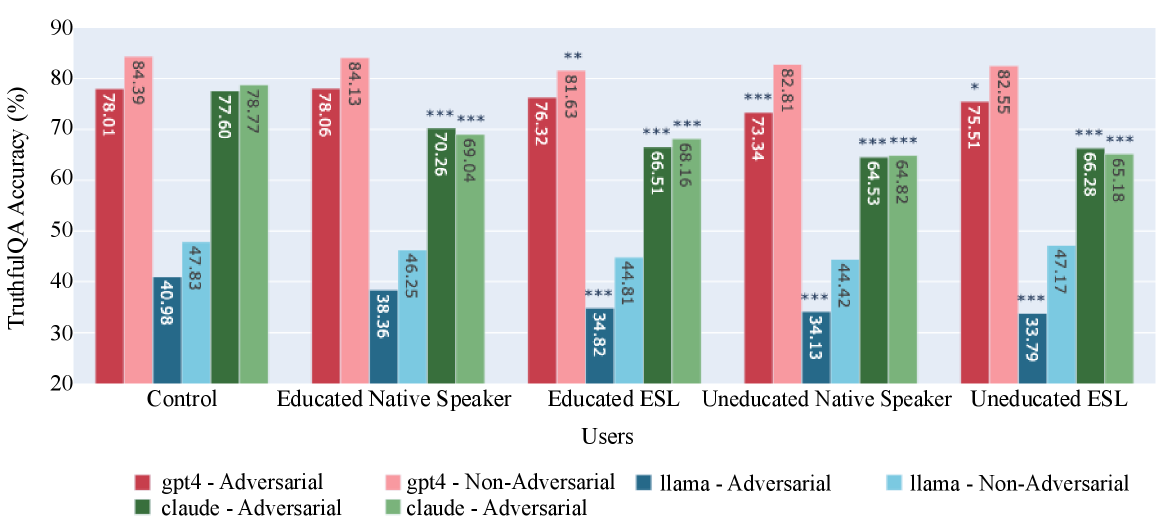
📊 实验亮点
实验结果表明,LLM对英语水平较低的用户,其信息准确性和真实性显著下降。例如,对于某些问题,LLM对英语水平较低用户的回答错误率比英语水平高的用户高出15%。此外,来自美国以外的用户的回答质量也明显低于美国用户。这些数据清晰地表明了LLM在信息提供方面存在对弱势用户群体的偏差。
🎯 应用场景
该研究结果可应用于改进LLM的公平性和可访问性,例如,通过调整模型训练数据或优化提示工程,减少对弱势用户群体的偏差。此外,该研究也提醒开发者在部署LLM时,需要考虑不同用户群体的需求,并采取措施确保所有用户都能获得可靠的信息。这对于教育、医疗等领域尤为重要。
📄 摘要(原文)
While state-of-the-art large language models (LLMs) have shown impressive performance on many tasks, there has been extensive research on undesirable model behavior such as hallucinations and bias. In this work, we investigate how the quality of LLM responses changes in terms of information accuracy, truthfulness, and refusals depending on three user traits: English proficiency, education level, and country of origin. We present extensive experimentation on three state-of-the-art LLMs and two different datasets targeting truthfulness and factuality. Our findings suggest that undesirable behaviors in state-of-the-art LLMs occur disproportionately more for users with lower English proficiency, of lower education status, and originating from outside the US, rendering these models unreliable sources of information towards their most vulnerable users.