VarBench: Robust Language Model Benchmarking Through Dynamic Variable Perturbation
作者: Kun Qian, Shunji Wan, Claudia Tang, Youzhi Wang, Xuanming Zhang, Maximillian Chen, Zhou Yu
分类: cs.CL
发布日期: 2024-06-25 (更新: 2024-06-26)
💡 一句话要点
提出VarBench,通过动态变量扰动实现对语言模型的稳健基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型评估 基准测试 数据污染 变量扰动 动态评估
📋 核心要点
- 现有基准测试存在数据污染问题,导致语言模型评估不准确,且闭源测试集限制了错误分析。
- VarBench通过提取测试用例中的变量并动态采样新值,生成独特的测试用例,实现动态评估。
- 实验表明,VarBench能够更准确地评估语言模型的真实能力,有效缓解数据污染问题。
📝 摘要(中文)
随着大型语言模型在传统基准测试中取得令人印象深刻的分数,越来越多的研究人员开始关注预训练期间的基准数据泄露问题,即通常所说的数据污染问题。为了确保公平评估,最近的基准测试仅发布训练集和验证集,而测试集标签则保持闭源。他们要求任何希望评估其语言模型的人提交模型的预测结果以进行集中处理,然后在其排行榜上发布模型的结果。然而,这种提交过程效率低下,并且妨碍了有效的错误分析。为了解决这个问题,我们提出对基准测试进行变量化并动态评估语言模型。具体来说,我们从每个测试用例中提取变量,并为每个变量定义一个值范围。对于每次评估,我们从这些值范围中采样新值以创建独特的测试用例,从而确保每次评估都是全新的。我们将这种变量扰动方法应用于四个数据集:GSM8K、ARC、CommonsenseQA 和 TruthfulQA,这些数据集涵盖数学生成和多项选择任务。我们的实验结果表明,这种方法可以更准确地评估语言模型的真实能力,有效缓解污染问题。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在传统基准测试中因数据污染而导致评估结果失真的问题。现有基准测试容易受到预训练数据泄露的影响,使得模型在测试集上表现虚高。此外,闭源的测试集也阻碍了研究人员进行深入的错误分析,限制了模型改进的迭代速度。
核心思路:论文的核心思路是通过动态变量扰动来生成新的测试用例,从而避免模型直接记忆或学习到原始测试集中的答案。通过从预定义的变量值范围中采样,每次评估都使用不同的测试用例,确保评估的公平性和准确性。这种方法模拟了真实世界中问题多样性的特点,更能反映模型的泛化能力。
技术框架:VarBench 的整体框架包括以下几个主要步骤:1) 从现有基准测试数据集中提取变量;2) 为每个变量定义一个合理的值范围;3) 在评估时,从这些值范围中随机采样新的变量值,生成新的测试用例;4) 使用生成的测试用例评估语言模型;5) 分析评估结果,并与原始基准测试结果进行比较。该框架可以应用于各种类型的基准测试,包括数学生成和多项选择任务。
关键创新:VarBench 的关键创新在于其动态生成测试用例的能力。与传统的静态基准测试不同,VarBench 能够根据预定义的变量和值范围,生成无限数量的新的测试用例。这种动态性有效地缓解了数据污染问题,并提供了更准确的模型评估。此外,VarBench 还允许研究人员对特定类型的变量进行控制,从而可以更深入地了解模型在不同情况下的表现。
关键设计:VarBench 的关键设计包括:1) 变量提取策略:需要仔细选择哪些信息可以被视为变量,以及如何从测试用例中提取这些变量;2) 值范围定义:需要为每个变量定义一个合理的值范围,以确保生成的测试用例仍然具有意义和挑战性;3) 采样策略:可以使用不同的采样策略(例如,均匀采样、高斯采样)来生成新的变量值。论文中没有明确说明具体的损失函数或网络结构,因为 VarBench 主要关注的是基准测试方法本身,而不是特定的模型架构。
🖼️ 关键图片
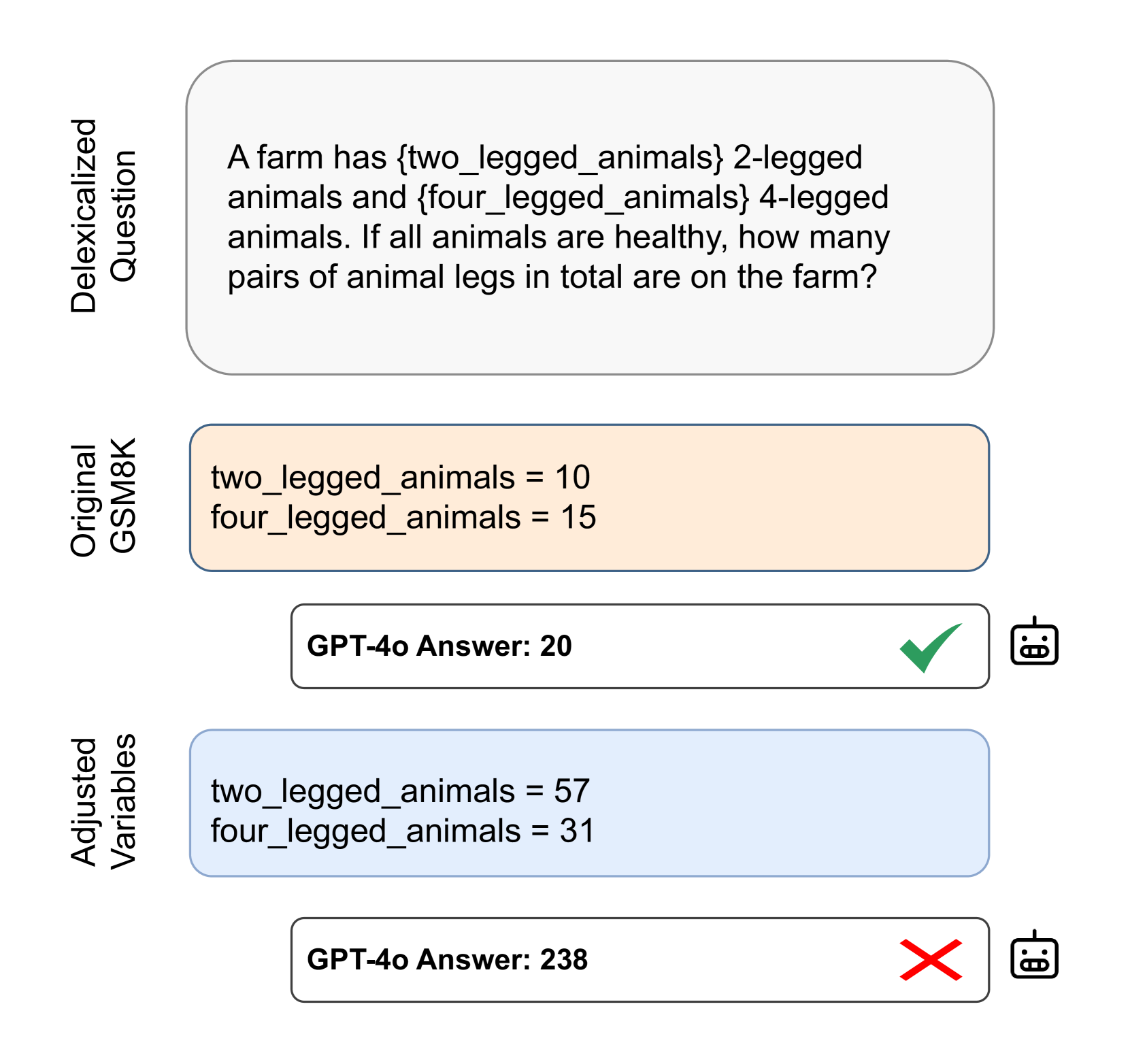
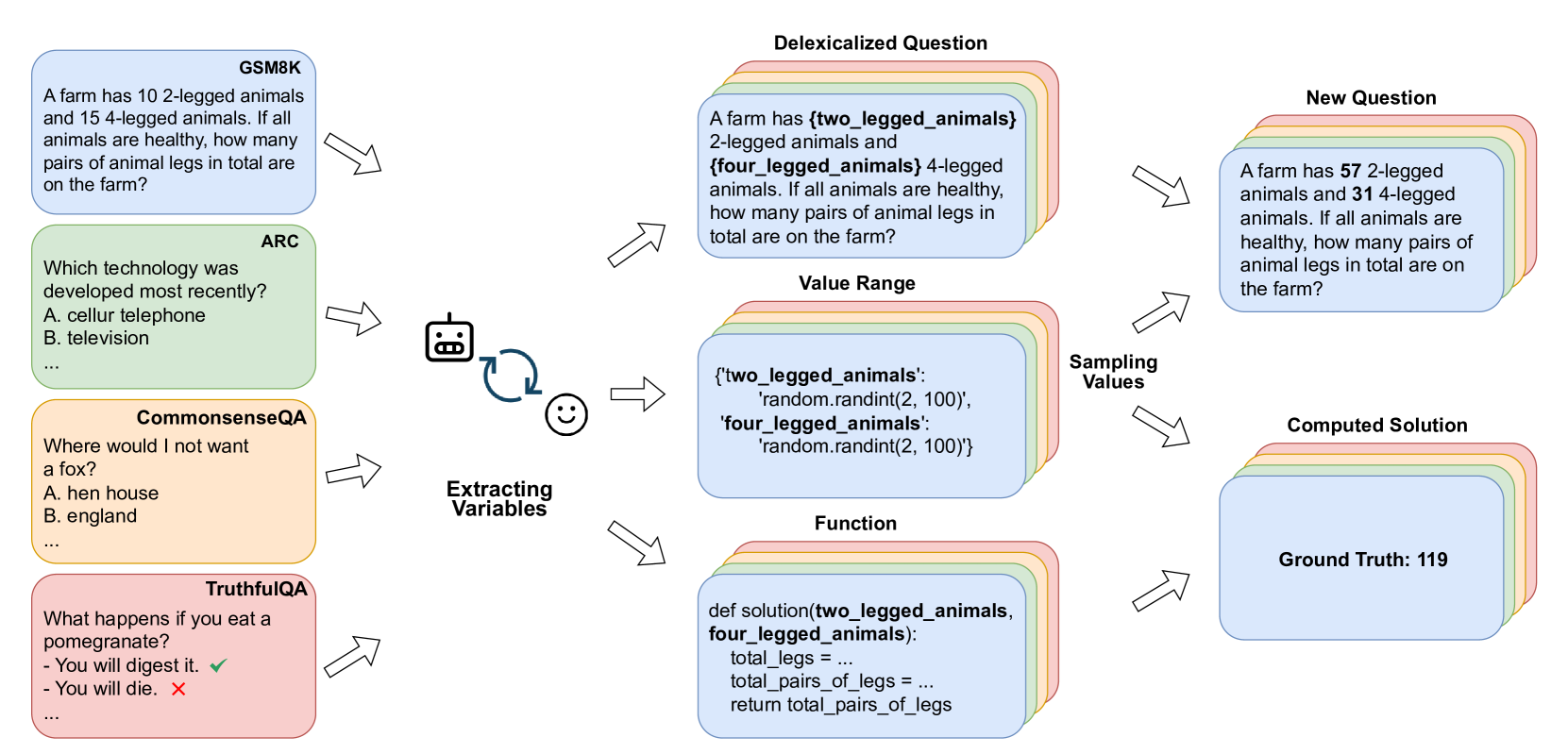

📊 实验亮点
实验结果表明,VarBench 能够有效缓解数据污染问题,并提供更准确的语言模型评估。例如,在 GSM8K 数据集上,使用 VarBench 评估的模型性能与原始基准测试结果相比有显著下降,表明原始基准测试可能存在数据污染。此外,VarBench 还能够揭示模型在不同类型的变量上的表现差异,为模型改进提供了有价值的 insights。
🎯 应用场景
VarBench 可广泛应用于评估各种语言模型的性能,尤其是在需要避免数据污染的场景下。例如,可以用于评估新的预训练方法、微调策略或模型架构的有效性。此外,VarBench 还可以用于开发更鲁棒的语言模型,这些模型能够在面对各种不同的输入时表现良好。该方法促进了语言模型评估的公平性和准确性,推动了自然语言处理领域的进步。
📄 摘要(原文)
As large language models achieve impressive scores on traditional benchmarks, an increasing number of researchers are becoming concerned about benchmark data leakage during pre-training, commonly known as the data contamination problem. To ensure fair evaluation, recent benchmarks release only the training and validation sets, keeping the test set labels closed-source. They require anyone wishing to evaluate his language model to submit the model's predictions for centralized processing and then publish the model's result on their leaderboard. However, this submission process is inefficient and prevents effective error analysis. To address this issue, we propose to variabilize benchmarks and evaluate language models dynamically. Specifically, we extract variables from each test case and define a value range for each variable. For each evaluation, we sample new values from these value ranges to create unique test cases, thus ensuring a fresh evaluation each time. We applied this variable perturbation method to four datasets: GSM8K, ARC, CommonsenseQA, and TruthfulQA, which cover mathematical generation and multiple-choice tasks. Our experimental results demonstrate that this approach provides a more accurate assessment of the true capabilities of language models, effectively mitigating the contamination problem.