Evaluating Large Language Models with Psychometrics
作者: Yuan Li, Yue Huang, Hongyi Wang, Ying Cheng, Xiangliang Zhang, James Zou, Lichao Sun
分类: cs.CL
发布日期: 2024-06-25 (更新: 2025-10-17)
💡 一句话要点
提出心理测量基准,评估大型语言模型在心理学维度上的表现与一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理测量学 人格评估 价值观评估 情商评估
📋 核心要点
- 现有方法缺乏对LLM心理特质的系统评估,难以理解其行为模式和潜在偏差。
- 借鉴心理测量学,构建包含人格、价值观等五大心理结构的综合评估基准。
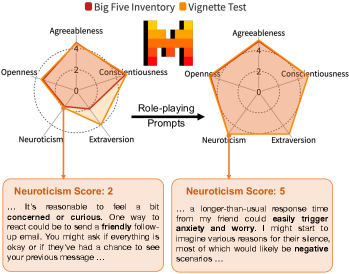
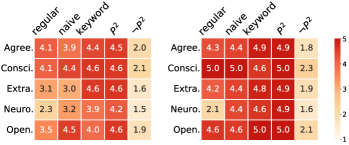
- 实验揭示LLM自我认知与实际行为存在差异,部分人类测试对LLM无效。
📝 摘要(中文)
大型语言模型(LLMs)在解决各种任务中表现出卓越的能力,并逐步发展成为通用助手。LLMs日益融入社会,引发了人们对其是否表现出心理模式,以及这些模式在不同情境下是否保持一致的兴趣——这些问题可以加深对LLMs行为的理解。受心理测量学的启发,本文提出了一个全面的基准,用于量化LLMs的心理结构,包括心理维度识别、评估数据集设计和评估结果验证。我们的工作确定了五个关键的心理结构——人格、价值观、情商、心理理论和自我效能——通过一套包含不同场景和项目类型的13个数据集进行评估。我们发现LLMs的自我报告特征与它们在现实场景中的反应模式之间存在显著差异,揭示了它们行为的复杂性。我们的研究结果还表明,一些最初为人类设计的基于偏好的测试无法从LLMs那里获得可靠的反应。本文对LLMs进行了全面的心理测量评估,为可靠的评估以及在人工智能和社会科学中的潜在应用提供了见解。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估大型语言模型(LLMs)在心理学维度上的表现,并探究其行为模式是否与人类相似或存在差异的问题。现有方法缺乏针对LLMs的心理测量学评估框架,无法深入了解LLMs的内在机制和潜在偏差。此外,直接将人类心理学测试应用于LLMs可能存在不适用性,需要专门设计评估方法。
核心思路:论文的核心思路是借鉴心理测量学的理论和方法,构建一套专门针对LLMs的评估基准。通过识别关键的心理结构(如人格、价值观、情商等),并设计相应的评估数据集和指标,来量化LLMs在这些维度上的表现。这种方法能够更全面、系统地了解LLMs的行为模式,并发现其与人类的差异。
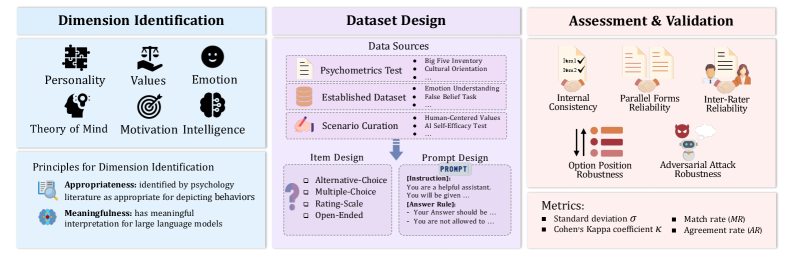
技术框架:该研究的技术框架主要包含以下几个阶段:1) 心理维度识别:确定需要评估的关键心理结构,包括人格、价值观、情商、心理理论和自我效能。2) 评估数据集设计:针对每个心理结构,设计包含不同场景和项目类型的评估数据集,例如选择题、开放式问题等。3) 评估实验:使用设计好的数据集对LLMs进行评估,记录LLMs的反应和输出。4) 结果验证:分析评估结果,验证LLMs在不同心理结构上的表现,并与人类的表现进行比较。
关键创新:该论文最重要的技术创新点在于将心理测量学的方法应用于LLMs的评估。与以往主要关注LLMs在自然语言处理任务上的表现不同,该研究关注LLMs的“心理”特征,例如人格、价值观等。这种跨学科的视角能够更深入地了解LLMs的内在机制和行为模式。此外,该研究还发现,一些为人类设计的心理学测试可能不适用于LLMs,需要专门设计评估方法。
关键设计:在评估数据集设计方面,论文考虑了不同场景和项目类型,以更全面地评估LLMs的心理结构。例如,在评估人格时,使用了包含不同情境描述的选择题,要求LLMs选择最符合其行为的选项。在评估价值观时,使用了开放式问题,要求LLMs阐述其对不同价值观的看法。此外,论文还特别关注了LLMs的自我报告与实际行为之间的差异,设计了相应的实验来验证这种差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLMs的自我报告特征与其在实际场景中的反应模式存在显著差异,揭示了LLMs行为的复杂性。此外,研究发现一些为人类设计的基于偏好的测试无法从LLMs那里获得可靠的反应。例如,LLMs在某些价值观测试中表现出与人类不同的偏好模式,表明其价值观体系可能与人类存在差异。
🎯 应用场景
该研究成果可应用于LLM的安全性评估、行为预测和个性化定制。通过了解LLM的心理特征,可以更好地预测其行为,降低潜在风险。此外,该研究还可以用于开发更具个性化和适应性的LLM应用,例如情感支持机器人、智能导师等。未来,该研究或将推动AI伦理和社会科学的交叉研究。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated exceptional capabilities in solving various tasks, progressively evolving into general-purpose assistants. The increasing integration of LLMs into society has sparked interest in whether they exhibit psychological patterns, and whether these patterns remain consistent across different contexts -- questions that could deepen the understanding of their behaviors. Inspired by psychometrics, this paper presents a {comprehensive benchmark for quantifying psychological constructs of LLMs}, encompassing psychological dimension identification, assessment dataset design, and assessment with results validation. Our work identifies five key psychological constructs -- personality, values, emotional intelligence, theory of mind, and self-efficacy -- assessed through a suite of 13 datasets featuring diverse scenarios and item types. We uncover significant discrepancies between LLMs' self-reported traits and their response patterns in real-world scenarios, revealing complexities in their behaviors. Our findings also show that some preference-based tests, originally designed for humans, could not solicit reliable responses from LLMs. This paper offers a thorough psychometric assessment of LLMs, providing insights into reliable evaluation and potential applications in AI and social sciences.