Banishing LLM Hallucinations Requires Rethinking Generalization
作者: Johnny Li, Saksham Consul, Eda Zhou, James Wong, Naila Farooqui, Yuxin Ye, Nithyashree Manohar, Zhuxiaona Wei, Tian Wu, Ben Echols, Sharon Zhou, Gregory Diamos
分类: cs.CL, cs.AI
发布日期: 2024-06-25 (更新: 2025-09-03)
备注: I want to revisit some of the experiments in this paper, specifically figure 5
💡 一句话要点
重新思考泛化能力以消除大语言模型幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉 知识增强 混合记忆专家 动态检索 泛化能力 Lamini-1
📋 核心要点
- 现有方法难以解释LLM在实践中产生幻觉的根本原因,尤其是在知识增强的情况下。
- 论文提出通过大规模混合记忆专家(MoME)存储事实,并动态检索,以减少LLM的幻觉。
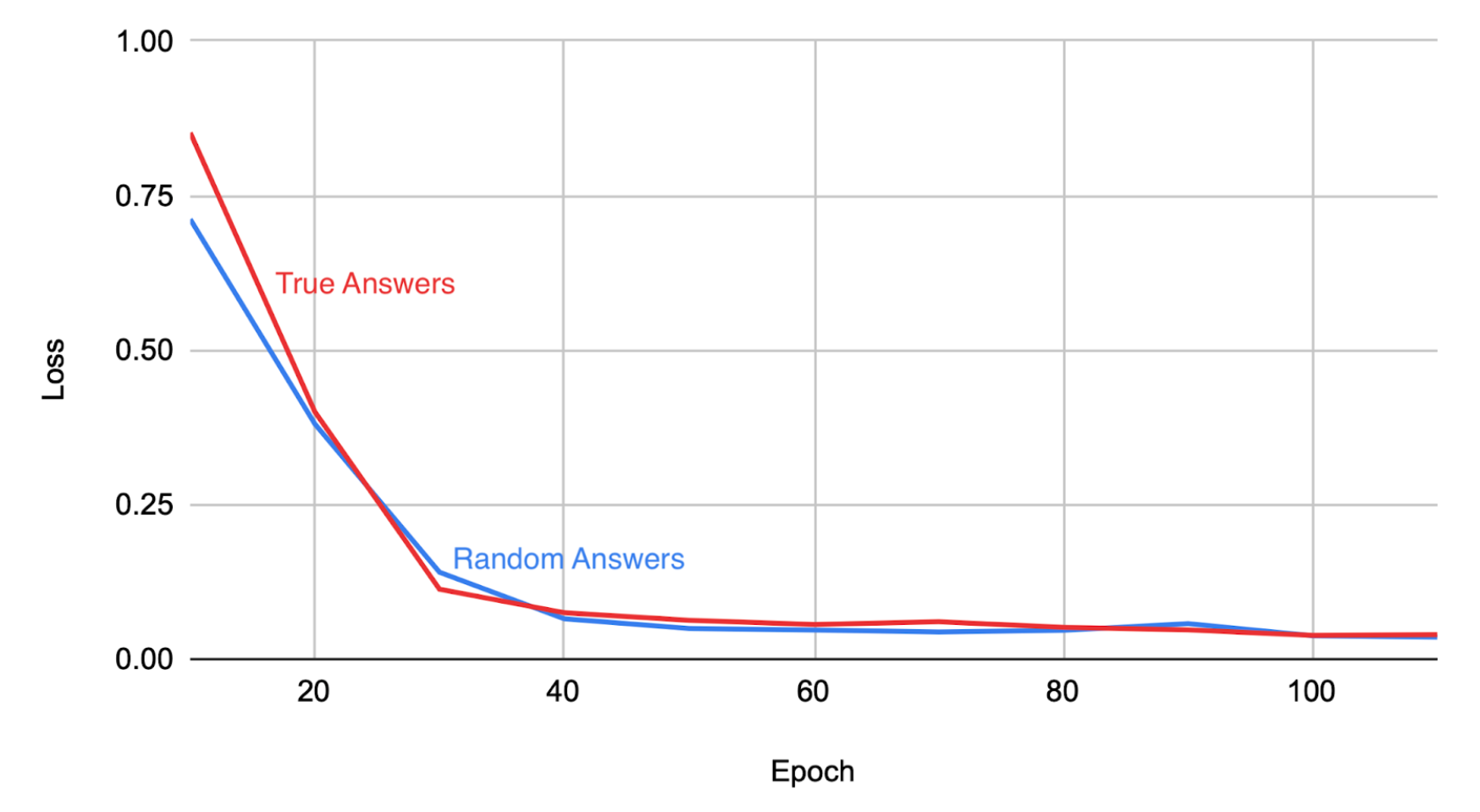
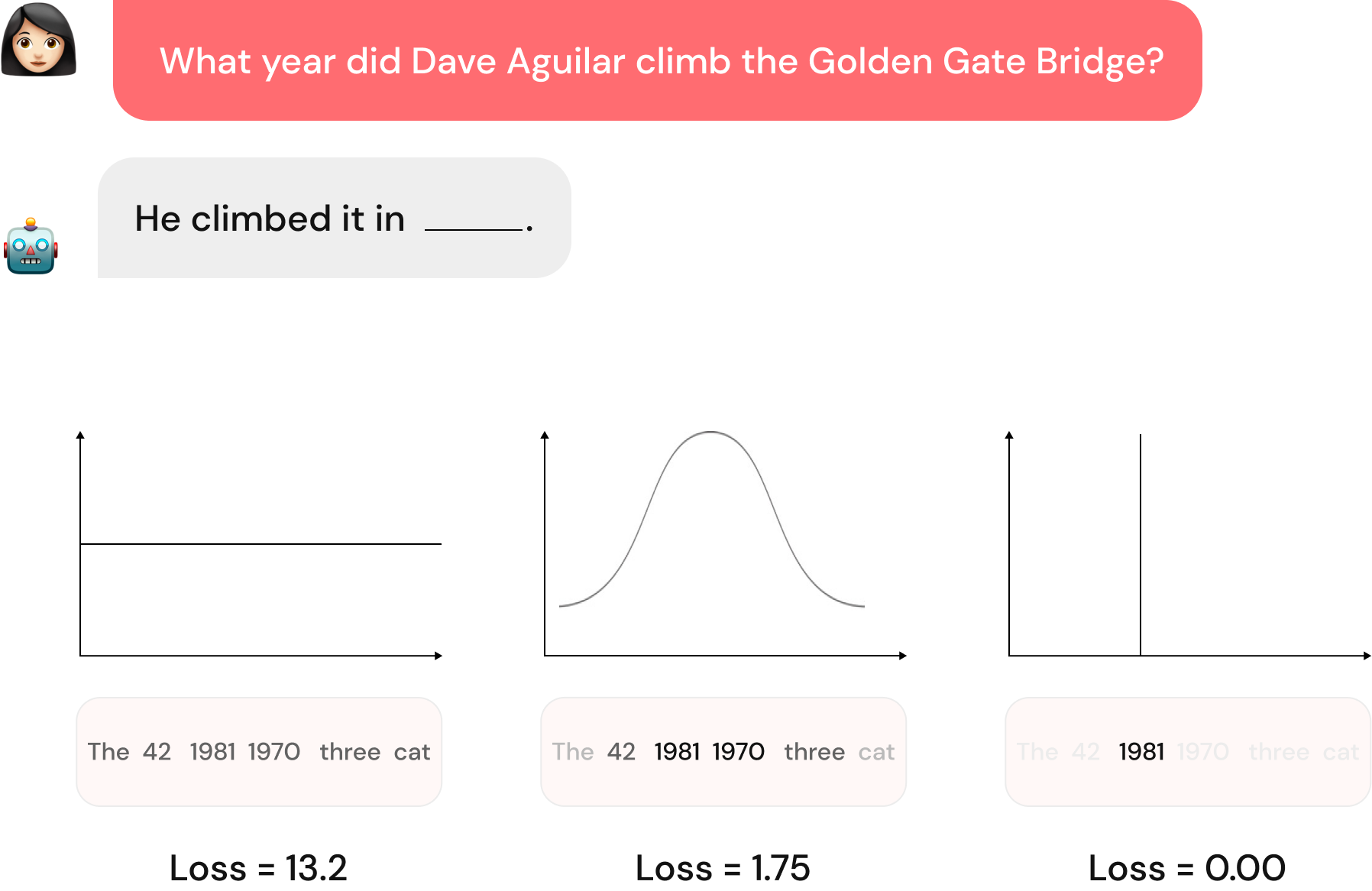
- 实验表明,即使LLM能够记忆大量随机数据,仍然会产生幻觉,Lamini-1模型旨在消除幻觉。
📝 摘要(中文)
尽管大型语言模型(LLM)具有强大的聊天、编码和推理能力,但它们经常产生幻觉。传统观点认为,幻觉是创造性和事实性之间平衡的结果,可以通过将LLM与外部知识源相结合来缓解,但无法消除。通过广泛的系统实验,我们表明这些传统方法无法解释LLM在实践中产生幻觉的原因。具体来说,我们表明,使用大规模混合记忆专家(MoME)增强的LLM可以轻松记忆大型随机数数据集。我们通过理论构建证实了这些实验结果,表明当训练损失高于阈值时(就像在互联网规模数据上训练时通常发生的那样),训练用于预测下一个token的简单神经网络会产生幻觉。我们通过与用于缓解幻觉的传统检索方法进行比较来解释我们的发现。我们利用我们的发现设计了第一代用于消除幻觉的模型——Lamini-1,该模型将事实存储在数百万个动态检索的记忆专家的混合体中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中普遍存在的幻觉问题。现有方法,如知识增强,虽然能在一定程度上缓解幻觉,但无法彻底消除,并且无法解释LLM在具备记忆大量信息能力的情况下仍然产生幻觉的现象。现有方法的痛点在于未能从根本上理解幻觉产生的机制,以及如何有效地利用知识来避免幻觉。
核心思路:论文的核心思路是重新审视LLM的泛化能力,并认为幻觉的产生与训练损失有关。即使LLM能够记忆大量数据,只要训练损失高于某个阈值,就仍然会产生幻觉。因此,论文提出使用大规模混合记忆专家(MoME)来存储事实,并通过动态检索的方式,让LLM在生成文本时能够准确地获取相关知识,从而减少幻觉。
技术框架:论文提出的Lamini-1模型采用了一种基于MoME的架构。该架构包含数百万个记忆专家,每个专家负责存储一部分知识。在生成文本时,模型会根据输入查询动态地检索相关的记忆专家,并将检索到的知识用于生成文本。整体流程包括:输入查询 -> 检索相关记忆专家 -> 利用检索到的知识生成文本。
关键创新:论文最重要的技术创新点在于将大规模混合记忆专家(MoME)与动态检索机制相结合,用于消除LLM的幻觉。与传统的知识增强方法不同,Lamini-1不是简单地将外部知识注入LLM,而是通过动态检索的方式,让LLM能够根据不同的输入查询,选择性地获取相关的知识。这种方法能够更有效地利用知识,并减少幻觉的产生。
关键设计:Lamini-1的关键设计包括:1)MoME的规模:使用了数百万个记忆专家,以存储大量的知识;2)检索机制:采用了动态检索机制,根据输入查询选择相关的记忆专家;3)损失函数:论文可能使用了特定的损失函数来训练MoME和检索机制,以提高检索的准确性和生成文本的质量(具体细节未知)。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,即使LLM能够记忆大量随机数据,仍然会产生幻觉。Lamini-1模型旨在消除幻觉,但具体的性能数据、对比基线、提升幅度等信息在摘要中未明确给出,需要查阅论文全文以获取更详细的实验结果。
🎯 应用场景
该研究成果可应用于各种需要高度准确性的自然语言生成任务,例如:医疗诊断报告生成、法律文件撰写、金融分析报告生成等。通过减少LLM的幻觉,可以提高生成文本的可靠性和实用性,从而在这些领域发挥更大的作用。未来,该技术有望被集成到各种LLM应用中,提高LLM的整体性能。
📄 摘要(原文)
Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance between creativity and factuality, which can be mitigated, but not eliminated, by grounding the LLM in external knowledge sources. Through extensive systematic experiments, we show that these traditional approaches fail to explain why LLMs hallucinate in practice. Specifically, we show that LLMs augmented with a massive Mixture of Memory Experts (MoME) can easily memorize large datasets of random numbers. We corroborate these experimental findings with a theoretical construction showing that simple neural networks trained to predict the next token hallucinate when the training loss is above a threshold as it usually does in practice when training on internet scale data. We interpret our findings by comparing against traditional retrieval methods for mitigating hallucinations. We use our findings to design a first generation model for removing hallucinations -- Lamini-1 -- that stores facts in a massive mixture of millions of memory experts that are retrieved dynamically.