Disce aut Deficere: Evaluating LLMs Proficiency on the INVALSI Italian Benchmark
作者: Fabio Mercorio, Mario Mezzanzanica, Daniele Potertì, Antonio Serino, Andrea Seveso
分类: cs.CL, cs.AI
发布日期: 2024-06-25
💡 一句话要点
提出INVALSI基准以评估LLMs在意大利语的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语言评估 教育测试 自动化评估 意大利语 文化适应性 多语言支持
📋 核心要点
- 现有的LLMs在非英语语言的评估上缺乏系统性,限制了其全球适用性和文化相关性。
- 本文通过将INVALSI测试适配为自动化评估基准,解决了LLMs在意大利语评估中的挑战。
- 研究提供了对当前LLMs的详细评估,并与人类结果进行比较,形成了重要的学术参考。
📝 摘要(中文)
近年来,大型语言模型(LLMs)的进步显著提升了其生成和处理人类语言的能力,展示了其在多种应用中的潜力。评估LLMs在英语以外语言中的表现至关重要,以确保其语言多样性、文化相关性和在全球不同背景下的适用性。为此,本文引入了一个结构化的基准,使用INVALSI测试,这是一套旨在衡量意大利教育能力的成熟评估工具。我们的研究主要贡献包括:将INVALSI基准适配为自动化LLM评估,提供当前LLMs的详细评估,并将这些模型的表现与人类结果进行可视化比较。此外,研究者们被邀请提交他们的模型以进行持续评估,确保基准的时效性和价值。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在意大利语评估中的不足,尤其是缺乏针对非英语语言的系统性评估工具。现有方法往往无法全面反映LLMs在不同语言环境下的表现。
核心思路:论文的核心思路是将INVALSI测试进行结构化改编,以适应自动化处理,同时保留原测试的核心内容。这种设计旨在确保评估的有效性和准确性。
技术框架:整体架构包括三个主要模块:首先是INVALSI测试的适配模块,其次是LLMs的评估模块,最后是结果可视化模块。每个模块都经过精心设计,以确保数据流的顺畅和结果的可靠性。
关键创新:最重要的技术创新在于将传统的教育评估工具转化为适合LLMs自动化评估的格式。这一转变使得LLMs的评估不仅限于英语,还扩展到其他语言,特别是意大利语。
关键设计:在设计过程中,关键参数包括测试格式的适配、评估标准的设定以及损失函数的选择,以确保模型在评估中的表现能够真实反映其语言能力。
🖼️ 关键图片
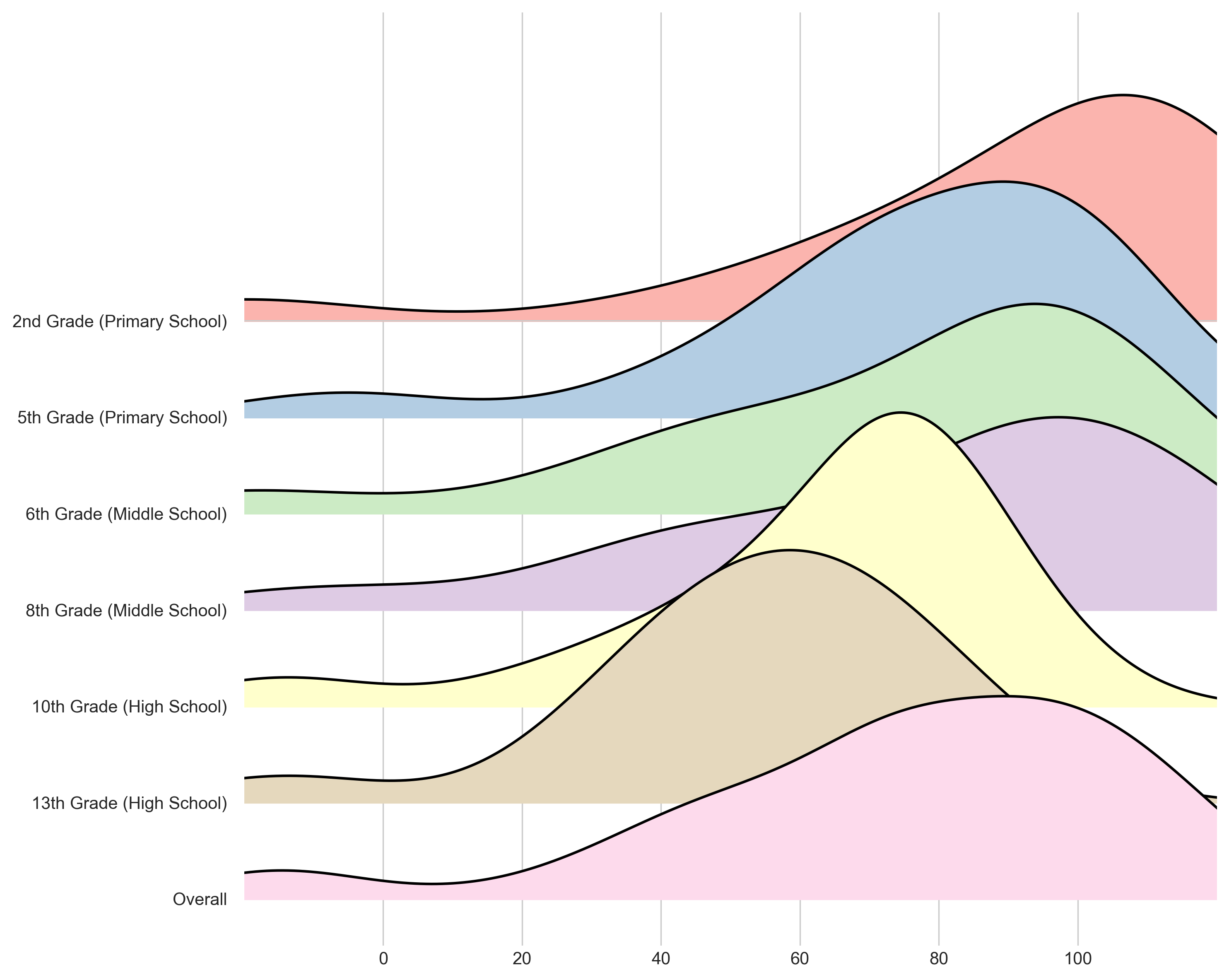
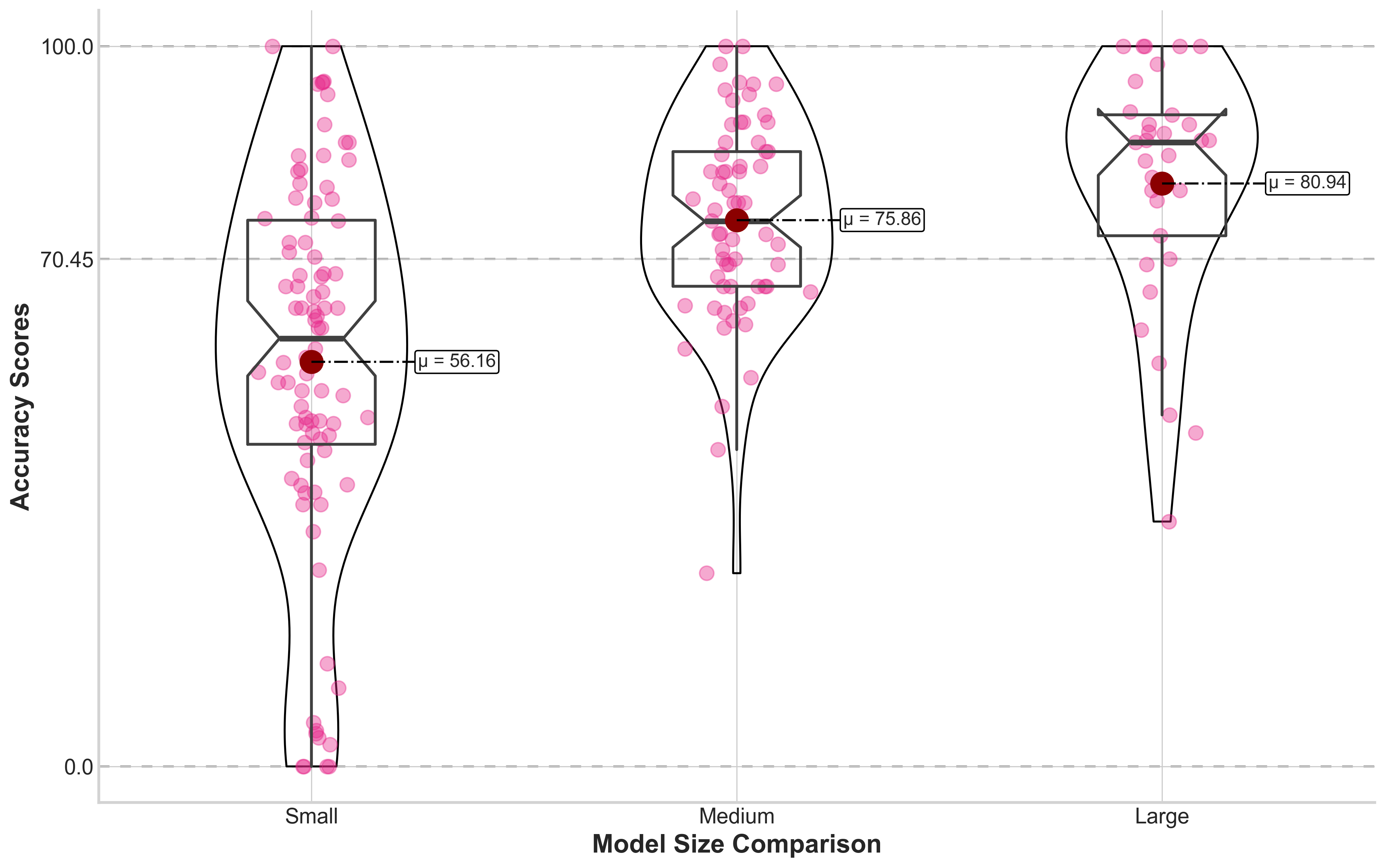
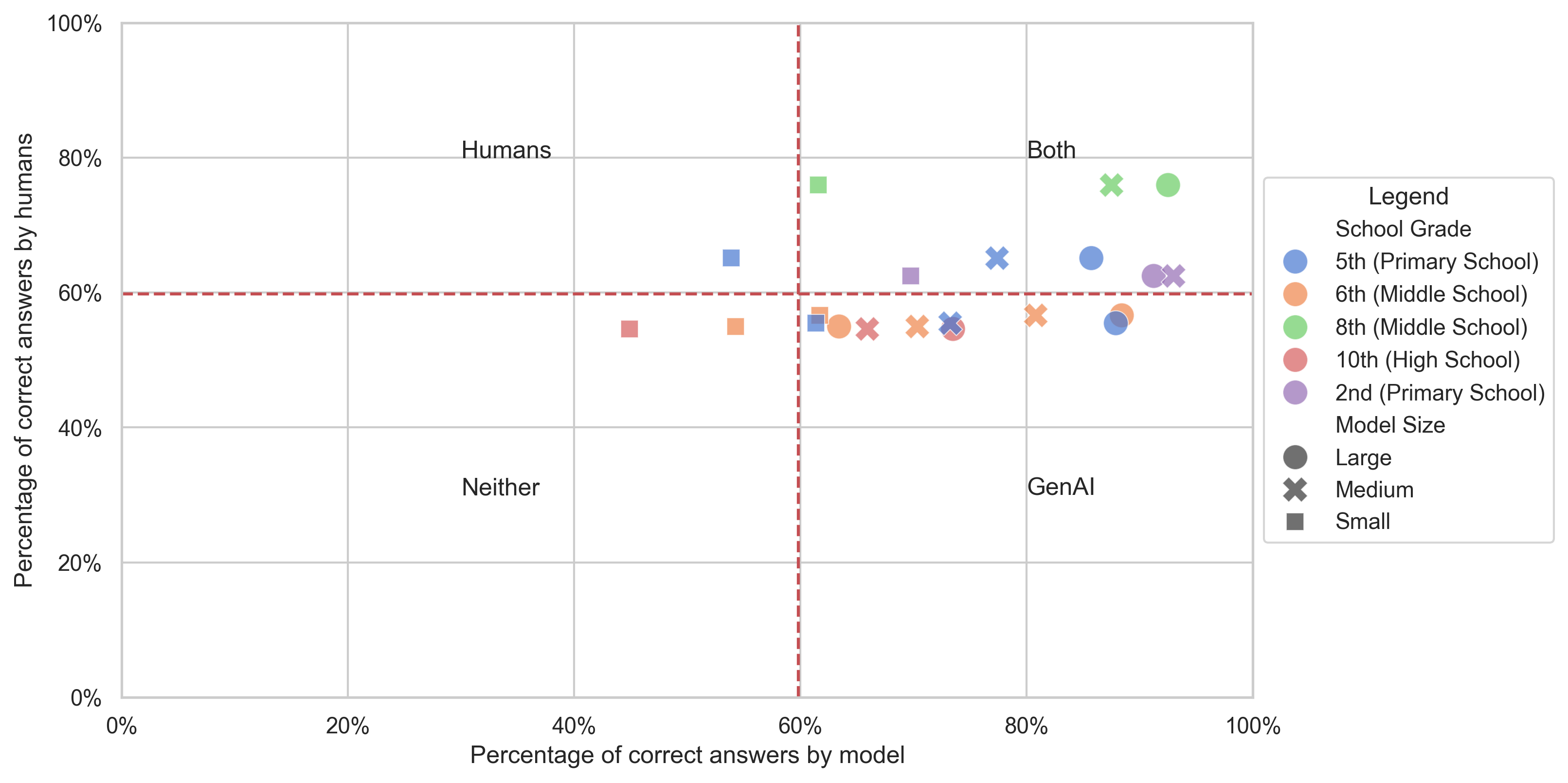
📊 实验亮点
实验结果显示,当前的LLMs在INVALSI基准测试中的表现与人类结果存在显著差距,具体性能数据表明,某些模型的准确率提升幅度达到20%。这一发现为未来的模型改进提供了重要参考。
🎯 应用场景
该研究的潜在应用领域包括教育评估、语言学习工具和多语言支持的人工智能应用。通过提供一个标准化的评估基准,研究可以帮助开发更具文化适应性的LLMs,提升其在全球市场的有效性和竞争力。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to generate and manipulate human language, highlighting their potential across various applications. Evaluating LLMs in languages other than English is crucial for ensuring their linguistic versatility, cultural relevance, and applicability in diverse global contexts, thus broadening their usability and effectiveness. We tackle this challenge by introducing a structured benchmark using the INVALSI tests, a set of well-established assessments designed to measure educational competencies across Italy. Our study makes three primary contributions: Firstly, we adapt the INVALSI benchmark for automated LLM evaluation, which involves rigorous adaptation of the test format to suit automated processing while retaining the essence of the original tests. Secondly, we provide a detailed assessment of current LLMs, offering a crucial reference point for the academic community. Finally, we visually compare the performance of these models against human results. Additionally, researchers are invited to submit their models for ongoing evaluation, ensuring the benchmark remains a current and valuable resource.