Retrieval-style In-Context Learning for Few-shot Hierarchical Text Classification
作者: Huiyao Chen, Yu Zhao, Zulong Chen, Mengjia Wang, Liangyue Li, Meishan Zhang, Min Zhang
分类: cs.CL
发布日期: 2024-06-25 (更新: 2024-06-29)
备注: 17 pages
💡 一句话要点
提出一种基于检索的上下文学习框架,用于解决少样本分层文本分类问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分层文本分类 少样本学习 上下文学习 检索增强 对比学习 大型语言模型 标签感知表示
📋 核心要点
- 现有ICL方法在少样本分层文本分类中,因标签集庞大和标签模糊性而效果不佳。
- 提出基于检索的ICL框架,利用检索数据库寻找相关示例,并迭代管理分层标签。
- 通过持续训练预训练语言模型,结合MLM、CLS和DCL目标,提升标签感知表示能力,实验结果SOTA。
📝 摘要(中文)
分层文本分类(HTC)是一项具有广泛应用的重要任务,而少样本HTC最近受到了越来越多的关注。尽管具有大型语言模型(LLM)的上下文学习(ICL)在少样本学习中取得了显著成功,但由于庞大的分层标签集和极其模糊的标签,它对于HTC来说效果不佳。在这项工作中,我们介绍了第一个基于ICL的LLM框架,用于少样本HTC。我们利用检索数据库来识别相关的演示,并使用迭代策略来管理多层分层标签。特别地,我们为检索数据库配备了HTC标签感知的输入文本表示,这是通过在预训练语言模型上进行持续训练来实现的,包括掩码语言建模(MLM)、分层分类(CLS,专门针对HTC)和一种新的发散对比学习(DCL,主要针对相邻的语义相似标签)目标。在三个基准数据集上的实验结果表明,我们的方法具有优越的性能,并且我们可以在少样本HTC中实现最先进的结果。
🔬 方法详解
问题定义:论文旨在解决少样本分层文本分类(Few-shot Hierarchical Text Classification, HTC)问题。现有的上下文学习(In-Context Learning, ICL)方法在处理HTC任务时,由于其标签集合的规模庞大以及标签之间存在高度的歧义性,导致性能不佳。现有方法难以有效利用少量样本进行学习,并且无法很好地处理层次结构信息。
核心思路:论文的核心思路是利用检索增强的上下文学习框架,通过检索与输入文本相关的示例来提供更有效的上下文信息,并结合迭代策略来管理分层标签。此外,通过持续训练预训练语言模型,使其能够更好地感知HTC任务的特点,从而提升分类性能。
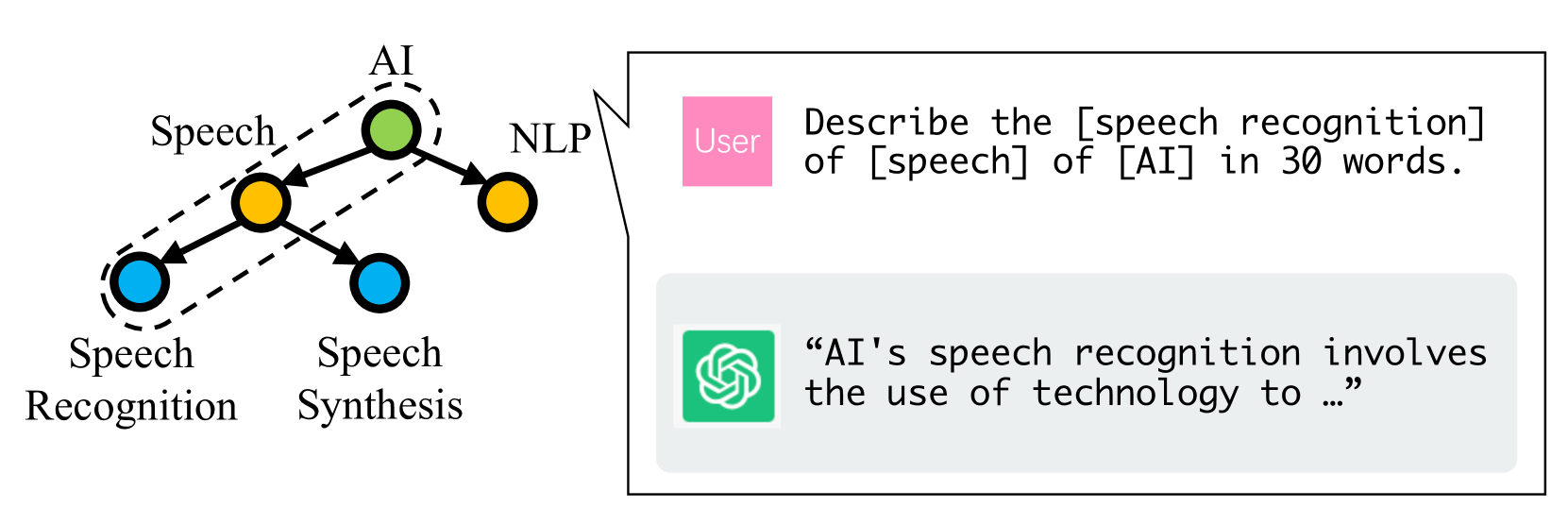
技术框架:整体框架包含以下几个主要模块:1) 检索数据库:存储带有HTC标签感知表示的文本;2) 检索模块:根据输入文本检索相关的示例;3) 上下文构建模块:将检索到的示例与输入文本组合成上下文;4) LLM推理模块:利用大型语言模型进行分层文本分类;5) 迭代策略模块:用于管理多层分层标签,逐步确定文本所属的类别。
关键创新:论文的关键创新在于:1) 提出了基于检索的上下文学习框架,能够有效地利用少量样本进行学习;2) 引入了HTC标签感知的文本表示方法,通过持续训练预训练语言模型,使其能够更好地感知HTC任务的特点;3) 设计了一种新的发散对比学习(DCL)目标,用于区分相邻的语义相似标签。
关键设计:在持续训练阶段,使用了掩码语言建模(MLM)、分层分类(CLS)和发散对比学习(DCL)三种损失函数。MLM用于增强模型的语言理解能力,CLS用于学习分层分类,DCL用于区分语义相似的标签。DCL损失函数的设计关键在于选择合适的正负样本对,特别是针对相邻的语义相似标签。迭代策略的具体实现细节(例如,迭代次数、停止条件等)以及检索模块的相似度度量方式也是关键的设计选择。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在三个基准数据集上均取得了优越的性能,并在少样本HTC任务中达到了最先进水平。相较于之前的ICL方法,性能有显著提升,证明了检索增强和标签感知表示的有效性。DCL损失函数的引入也带来了明显的性能提升,验证了区分语义相似标签的重要性。
🎯 应用场景
该研究成果可应用于多种需要分层文本分类的场景,例如:新闻文章分类、产品类别划分、医学文献分类等。通过少量样本即可快速构建高性能的分类器,降低了标注成本,具有重要的实际应用价值。未来可进一步探索如何将该方法应用于更复杂的文本分类任务,并与其他技术(如知识图谱)相结合,提升分类性能。
📄 摘要(原文)
Hierarchical text classification (HTC) is an important task with broad applications, while few-shot HTC has gained increasing interest recently. While in-context learning (ICL) with large language models (LLMs) has achieved significant success in few-shot learning, it is not as effective for HTC because of the expansive hierarchical label sets and extremely-ambiguous labels. In this work, we introduce the first ICL-based framework with LLM for few-shot HTC. We exploit a retrieval database to identify relevant demonstrations, and an iterative policy to manage multi-layer hierarchical labels. Particularly, we equip the retrieval database with HTC label-aware representations for the input texts, which is achieved by continual training on a pretrained language model with masked language modeling (MLM), layer-wise classification (CLS, specifically for HTC), and a novel divergent contrastive learning (DCL, mainly for adjacent semantically-similar labels) objective. Experimental results on three benchmark datasets demonstrate superior performance of our method, and we can achieve state-of-the-art results in few-shot HTC.