Scaling Laws for Fact Memorization of Large Language Models
作者: Xingyu Lu, Xiaonan Li, Qinyuan Cheng, Kai Ding, Xuanjing Huang, Xipeng Qiu
分类: cs.CL
发布日期: 2024-06-22
💡 一句话要点
揭示大语言模型事实记忆的规模定律,探索其记忆容量与特性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 事实记忆 规模定律 知识表示 知识增强
📋 核心要点
- 大语言模型的事实知识记忆能力对于生成可靠的回复至关重要,但现有研究对LLM事实记忆行为的探索不足。
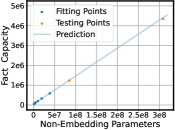
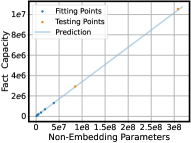
- 本文通过分析LLM在事实知识记忆方面的规模定律,揭示了模型大小、训练轮数与事实记忆容量之间的关系。
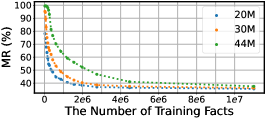
- 研究发现LLM在记忆冗余事实时存在困难,且更倾向于记忆高频和困难的事实,这为后续的事实知识增强提供了方向。
📝 摘要(中文)
本文旨在探索大语言模型(LLM)事实知识记忆的规模定律,分析LLM记忆不同类型事实的行为。研究发现,LLM的事实知识容量与模型大小呈线性关系,与训练轮数呈负指数关系。根据构建的规模定律估计,记忆整个Wikidata的事实需要训练一个具有1000B非嵌入参数的LLM,并进行100轮训练,这表明在一般的预训练设置下,使用LLM记忆所有公共事实几乎是不可能的。同时,研究发现LLM可以泛化到未见过的事实知识,并且其规模定律与一般预训练相似。此外,还分析了LLM事实记忆的兼容性和偏好。在兼容性方面,LLM难以统一记忆冗余事实。只有当相关事实具有相同的方向和结构时,LLM才能兼容地记忆它们,这表明LLM记忆冗余事实的效率较低。在偏好方面,LLM更倾向于记忆更频繁和更困难的事实,并且后续事实可以覆盖先前事实的记忆,这显著阻碍了低频事实的记忆。这些发现揭示了LLM事实知识学习的能力和特征,为LLM事实知识增强提供了方向。
🔬 方法详解
问题定义:现有大语言模型的事实知识记忆能力是其生成可靠回复的关键,但我们对LLM如何记忆事实,以及其记忆容量的限制仍然缺乏深入了解。现有方法难以有效评估和预测LLM的事实记忆能力,也未能充分理解不同类型事实对LLM记忆的影响。
核心思路:本文的核心思路是通过建立LLM事实记忆的规模定律,来量化模型大小、训练轮数与事实记忆容量之间的关系。通过分析不同类型事实的记忆行为,揭示LLM在记忆事实时的兼容性和偏好,从而为LLM的事实知识增强提供指导。
技术框架:本文的研究框架主要包括以下几个阶段:1) 构建事实知识数据集,用于评估LLM的事实记忆能力。2) 通过实验分析LLM在不同模型大小和训练轮数下的事实记忆表现。3) 基于实验结果,建立LLM事实记忆的规模定律,量化模型大小和训练轮数对事实记忆容量的影响。4) 分析LLM在记忆不同类型事实时的兼容性和偏好。
关键创新:本文最重要的技术创新在于建立了LLM事实记忆的规模定律,这为预测LLM的事实记忆能力提供了理论基础。此外,本文还深入分析了LLM在记忆不同类型事实时的兼容性和偏好,揭示了LLM事实记忆的内在机制。与现有方法相比,本文更加关注LLM事实记忆的量化分析和内在机制的探索。
关键设计:本文的关键设计包括:1) 使用Wikidata作为事实知识来源,构建大规模的事实知识数据集。2) 通过控制模型大小和训练轮数等变量,进行大量的实验,以获取可靠的实验数据。3) 使用线性回归和负指数回归等方法,建立LLM事实记忆的规模定律。4) 设计特定的实验,分析LLM在记忆冗余事实时的兼容性,以及在记忆不同频率和难度事实时的偏好。
🖼️ 关键图片
📊 实验亮点
研究发现LLM的事实知识容量与模型大小呈线性关系,与训练轮数呈负指数关系。根据规模定律估计,记忆整个Wikidata的事实需要训练一个具有1000B非嵌入参数的LLM,并进行100轮训练。此外,LLM在记忆冗余事实时存在困难,且更倾向于记忆高频和困难的事实。
🎯 应用场景
该研究成果可应用于提升大语言模型的知识水平和可靠性,例如,通过规模定律预测模型所需参数量和训练轮数,从而更有效地训练具备足够事实知识的LLM。此外,对LLM记忆偏好的理解有助于设计更有效的知识注入方法,提升模型在特定领域的知识掌握程度。该研究对知识密集型任务,如问答系统、知识图谱构建等具有重要意义。
📄 摘要(原文)
Fact knowledge memorization is crucial for Large Language Models (LLM) to generate factual and reliable responses. However, the behaviors of LLM fact memorization remain under-explored. In this paper, we analyze the scaling laws for LLM's fact knowledge and LLMs' behaviors of memorizing different types of facts. We find that LLMs' fact knowledge capacity has a linear and negative exponential law relationship with model size and training epochs, respectively. Estimated by the built scaling law, memorizing the whole Wikidata's facts requires training an LLM with 1000B non-embed parameters for 100 epochs, suggesting that using LLMs to memorize all public facts is almost implausible for a general pre-training setting. Meanwhile, we find that LLMs can generalize on unseen fact knowledge and its scaling law is similar to general pre-training. Additionally, we analyze the compatibility and preference of LLMs' fact memorization. For compatibility, we find LLMs struggle with memorizing redundant facts in a unified way. Only when correlated facts have the same direction and structure, the LLM can compatibly memorize them. This shows the inefficiency of LLM memorization for redundant facts. For preference, the LLM pays more attention to memorizing more frequent and difficult facts, and the subsequent facts can overwrite prior facts' memorization, which significantly hinders low-frequency facts memorization. Our findings reveal the capacity and characteristics of LLMs' fact knowledge learning, which provide directions for LLMs' fact knowledge augmentation.