Beyond the Turn-Based Game: Enabling Real-Time Conversations with Duplex Models
作者: Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, Zhiyuan Liu
分类: cs.CL
发布日期: 2024-06-22 (更新: 2026-01-13)
💡 一句话要点
提出双工模型,实现LLM实时对话交互,提升用户满意度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双工模型 实时对话 人机交互 大型语言模型 时分复用 微调 用户满意度
📋 核心要点
- 传统LLM对话系统采用回合制交互,用户需等待模型生成完毕才能发言,限制了实时性和自然度。
- 提出双工模型,通过时分复用策略,使LLM在生成回复的同时监听用户输入,实现伪同步处理。
- 构建包含交替时间片和反馈类型的微调数据集,实验证明双工模型能保持性能并提升用户满意度。
📝 摘要(中文)
随着大型语言模型(LLM)日益普及,人们对模拟真人对话的实时交互需求不断增长。传统的基于LLM的回合制聊天系统在模型生成回复时,用户无法进行口头交互。为了克服这些限制,本文将现有LLM改造为“双工模型”,使其在生成输出的同时能够“倾听”用户的声音,并动态调整自身以提供即时反馈,例如响应中断。具体而言,我们将对话的查询和回复分割成多个时间片,然后采用时分复用(TDM)编码-解码策略来伪同步处理这些片段。此外,为了使LLM能够熟练地处理实时对话,我们构建了一个微调数据集,其中包含查询和回复交替的时间片,以及涵盖即时交互中的典型反馈类型。实验表明,尽管对话的查询和回复被分割成不完整的片段进行处理,但LLM通过在我们数据集上进行少量微调,可以保持其在标准基准上的原始性能。自动和人工评估表明,与原始LLM相比,双工模型使人机交互更加自然和人性化,并大大提高了用户满意度。我们将发布双工模型和数据集。
🔬 方法详解
问题定义:现有基于大型语言模型的对话系统通常采用回合制交互模式,即用户提出问题后,需要等待模型完全生成回复后才能进行下一步交互。这种模式缺乏实时性,无法模拟人类对话中常见的打断、补充等自然交互行为,影响用户体验。
核心思路:本文的核心思路是将大型语言模型改造为“双工模型”,使其具备同时“听”和“说”的能力。具体来说,模型在生成回复的同时,能够监听用户的输入,并根据用户的反馈动态调整回复内容。这种设计旨在模拟人类对话中的实时交互,提升对话的自然度和流畅性。
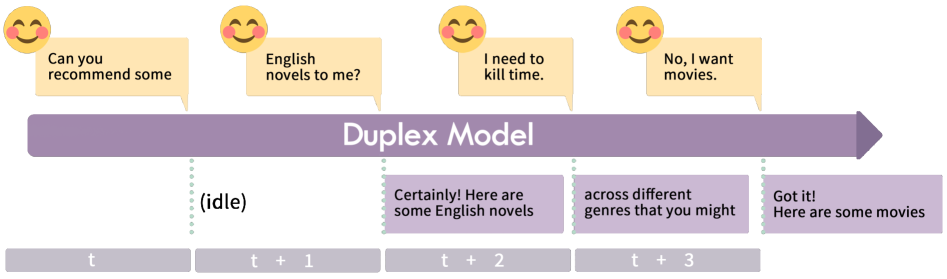
技术框架:该方法采用时分复用(TDM)的编码-解码策略。对话的查询和回复被分割成多个时间片,模型交替处理这些时间片,从而实现伪同步处理。整体流程可以概括为:1. 将用户输入和模型输出分割成时间片;2. 使用TDM策略对时间片进行编码和解码;3. 模型在解码生成回复的同时,监听用户输入的时间片;4. 根据用户输入动态调整回复内容。
关键创新:该方法最重要的创新点在于将大型语言模型改造为双工模型,使其具备实时交互能力。与传统的回合制对话系统相比,双工模型能够更好地模拟人类对话的自然性和流畅性。此外,该方法还提出了基于时分复用的编码-解码策略,以及用于微调双工模型的包含交替时间片和反馈类型的训练数据集。
关键设计:为了训练双工模型,作者构建了一个包含交替时间片和反馈类型的微调数据集。该数据集涵盖了即时交互中的典型反馈类型,例如打断、补充、修正等。此外,作者还可能使用了特定的损失函数来优化模型的实时交互能力,例如鼓励模型快速响应用户输入,并根据用户反馈动态调整回复内容。具体的网络结构可能基于现有的Transformer架构,并进行了一些修改以适应双工交互的需求。
🖼️ 关键图片


📊 实验亮点
实验结果表明,双工模型在标准基准上保持了原始LLM的性能,同时在人机交互的自然性和用户满意度方面取得了显著提升。自动评估和人工评估均表明,与原始LLM相比,双工模型能够生成更自然、更流畅的回复,并更好地响应用户反馈,从而大大提高了用户满意度。具体性能数据未知,但结论是正向的。
🎯 应用场景
该研究成果可应用于智能客服、虚拟助手、在线教育等领域,提升人机交互的自然性和效率。例如,在智能客服中,双工模型能够实时响应用户问题,提供更个性化的服务;在虚拟助手中,双工模型可以与用户进行更自然的对话,完成各种任务;在在线教育中,双工模型可以实时解答学生疑问,提供更有效的学习支持。未来,该技术有望应用于更广泛的人机交互场景,例如智能家居、智能驾驶等。
📄 摘要(原文)
As large language models (LLMs) increasingly permeate daily lives, there is a growing demand for real-time interactions that mirror human conversations. Traditional turn-based chat systems driven by LLMs prevent users from verbally interacting with the system while it is generating responses. To overcome these limitations, we adapt existing LLMs to \textit{duplex models} so that these LLMs can listen for users while generating output and dynamically adjust themselves to provide users with instant feedback. % such as in response to interruptions. Specifically, we divide the queries and responses of conversations into several time slices and then adopt a time-division-multiplexing (TDM) encoding-decoding strategy to pseudo-simultaneously process these slices. Furthermore, to make LLMs proficient enough to handle real-time conversations, we build a fine-tuning dataset consisting of alternating time slices of queries and responses as well as covering typical feedback types in instantaneous interactions. Our experiments show that although the queries and responses of conversations are segmented into incomplete slices for processing, LLMs can preserve their original performance on standard benchmarks with a few fine-tuning steps on our dataset. Automatic and human evaluation indicate that duplex models make user-AI interactions more natural and human-like, and greatly improve user satisfaction compared to vanilla LLMs. Our duplex model and dataset will be released.