Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
作者: Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Akim Tsvigun, Daniil Vasilev, Rui Xing, Abdelrahman Boda Sadallah, Kirill Grishchenkov, Sergey Petrakov, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, Artem Shelmanov
分类: cs.CL, cs.LG
发布日期: 2024-06-21 (更新: 2025-06-30)
备注: Published at TACL 2025, presented at ACL 2025. Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev contributed equally
期刊: Transactions of the Association for Computational Linguistics, 13 (2025) 220-248
DOI: 10.1162/tacl_a_00737
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
LM-Polygraph:用于大规模语言模型不确定性量化的综合基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性量化 基准测试 文本生成 置信度归一化
📋 核心要点
- 现有LLM的不确定性量化研究缺乏统一的评估标准和基线方法,难以系统性地比较和改进。
- 论文提出LM-Polygraph基准测试,包含多种先进UQ基线和可控的评估环境,用于文本生成任务。
- 通过大规模实验,该基准测试评估了多种UQ和归一化技术,并识别出最有效的方法。
📝 摘要(中文)
大型语言模型(LLM)的快速普及促使研究人员寻求有效的方法来处理LLM的幻觉和低质量输出。不确定性量化(UQ)是机器学习应用中应对这些挑战的关键要素。然而,目前关于LLM的UQ研究在技术和评估方法上是分散的。本文通过引入一个新的基准测试来解决这个问题,该基准测试实现了一系列最先进的UQ基线,并提供了一个环境,用于在各种文本生成任务上对新的UQ技术进行可控和一致的评估。我们的基准测试还支持评估置信度归一化方法在提供可解释分数方面的能力。使用我们的基准测试,我们对11个任务中的UQ和归一化技术进行了大规模的实证研究,确定了最有效的方法。代码:https://github.com/IINemo/lm-polygraph 基准测试:https://huggingface.co/LM-Polygraph
🔬 方法详解
问题定义:现有的大型语言模型(LLM)存在幻觉和低质量输出的问题,而有效的不确定性量化(UQ)是解决这些问题的关键。然而,现有的LLM的UQ研究缺乏统一的评估标准和基线方法,导致研究结果分散,难以比较和改进。因此,需要一个统一的基准测试来评估和比较不同的UQ方法。
核心思路:论文的核心思路是构建一个综合性的基准测试平台,该平台包含一系列最先进的UQ基线方法,并提供一个可控的评估环境,用于在各种文本生成任务上评估新的UQ技术。通过统一的评估标准,可以更有效地比较和改进不同的UQ方法,从而提高LLM的可靠性和质量。
技术框架:LM-Polygraph基准测试平台主要包含以下几个模块: 1. 数据集:收集了涵盖各种文本生成任务的数据集。 2. UQ基线方法:实现了多种最先进的UQ基线方法,例如Dropout、Deep Ensembles等。 3. 评估指标:定义了一系列评估指标,用于衡量UQ方法的性能,例如准确率、校准误差等。 4. 置信度归一化方法:支持评估置信度归一化方法在提供可解释分数方面的能力。
关键创新:该论文的关键创新在于提出了LM-Polygraph,这是一个专门为LLM的不确定性量化设计的综合性基准测试平台。与以往的研究相比,LM-Polygraph提供了一个统一的评估环境,可以更有效地比较和改进不同的UQ方法。此外,LM-Polygraph还支持评估置信度归一化方法,从而提高UQ结果的可解释性。
关键设计:LM-Polygraph的关键设计包括: 1. 多样化的数据集:涵盖了各种文本生成任务,以评估UQ方法在不同场景下的性能。 2. 全面的UQ基线:实现了多种最先进的UQ基线方法,为研究人员提供了一个参考。 3. 可控的评估环境:允许研究人员控制评估过程中的各种参数,从而更准确地评估UQ方法的性能。 4. 标准化的评估指标:定义了一系列标准化的评估指标,用于衡量UQ方法的性能。
🖼️ 关键图片
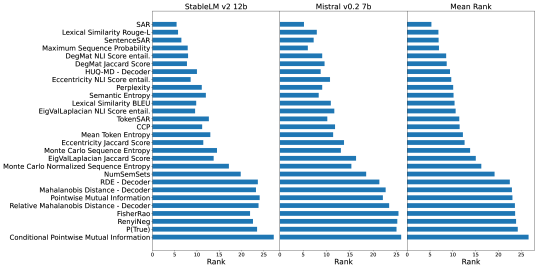
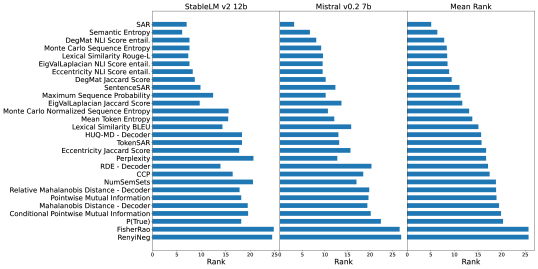
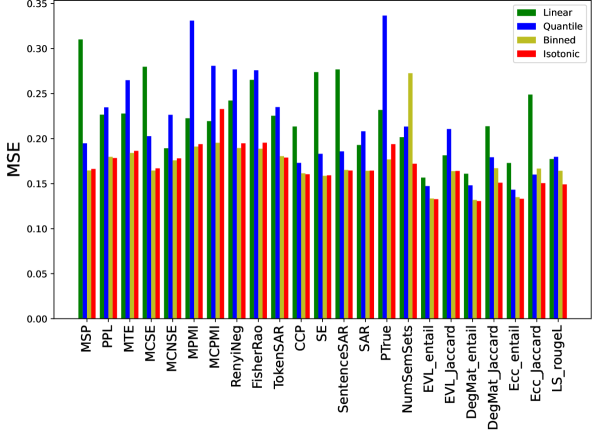
📊 实验亮点
通过在11个不同的文本生成任务上进行大规模实验,LM-Polygraph基准测试评估了多种UQ和归一化技术。实验结果表明,不同的UQ方法在不同的任务上表现各异,并且置信度归一化方法可以显著提高UQ结果的可解释性。该研究为选择合适的UQ方法和提高LLM的可靠性提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要高可靠性LLM输出的场景,例如医疗诊断、金融分析、法律咨询等。通过提高LLM的不确定性量化能力,可以减少LLM的幻觉和错误输出,从而提高决策的准确性和可靠性。未来,该基准测试可以促进LLM不确定性量化领域的研究进展,推动LLM在更多领域的应用。
📄 摘要(原文)
The rapid proliferation of large language models (LLMs) has stimulated researchers to seek effective and efficient approaches to deal with LLM hallucinations and low-quality outputs. Uncertainty quantification (UQ) is a key element of machine learning applications in dealing with such challenges. However, research to date on UQ for LLMs has been fragmented in terms of techniques and evaluation methodologies. In this work, we address this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines and offers an environment for controllable and consistent evaluation of novel UQ techniques over various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across eleven tasks, identifying the most effective approaches. Code: https://github.com/IINemo/lm-polygraph Benchmark: https://huggingface.co/LM-Polygraph