Unsupervised Extraction of Dialogue Policies from Conversations
作者: Makesh Narsimhan Sreedhar, Traian Rebedea, Christopher Parisien
分类: cs.CL
发布日期: 2024-06-21
💡 一句话要点
提出一种基于图结构的无监督对话策略提取方法,提升任务型对话系统开发效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话策略提取 无监督学习 大型语言模型 图结构 任务型对话系统
📋 核心要点
- 现有对话策略开发依赖专家知识,成本高昂,缺乏从大量对话数据中自动提取策略的有效方法。
- 利用大型语言模型将对话转换为规范形式,构建图结构的对话流网络,通过图遍历算法提取对话策略。
- 该方法提供更强的可控性和可解释性,为对话设计者提供生产力工具,改进对话策略开发流程。
📝 摘要(中文)
对话策略在开发任务型对话系统中起着至关重要的作用,然而其开发和维护具有挑战性,通常需要对话建模专家的付出大量努力。虽然在许多情况下,有大量的对话数据可用于手头的任务,但人们缺乏能够从此数据中提取对话策略的有效解决方案。在本文中,我们通过首先说明大型语言模型(LLM)如何通过将对话转换为由规范形式组成的统一中间表示,从而有助于从数据集中提取对话策略,从而解决了这一差距。然后,我们提出了一种新颖的生成对话策略的方法,该方法利用可控且可解释的基于图的方法。通过将对话中的规范形式组合成一个流网络,我们发现运行图遍历算法有助于提取对话流。这些流比通过提示 LLM 提取的流更好地表示了底层交互。我们的技术侧重于让对话设计者拥有更大的控制权,提供一种提高对话策略开发过程的生产力工具。
🔬 方法详解
问题定义:论文旨在解决任务型对话系统中对话策略自动提取的问题。现有方法主要依赖人工设计或有监督学习,前者成本高昂且难以维护,后者需要大量标注数据。因此,如何从无标注的对话数据中自动提取有效的对话策略成为一个关键挑战。现有方法,例如直接prompt LLM,提取的对话流质量不高,可控性差。
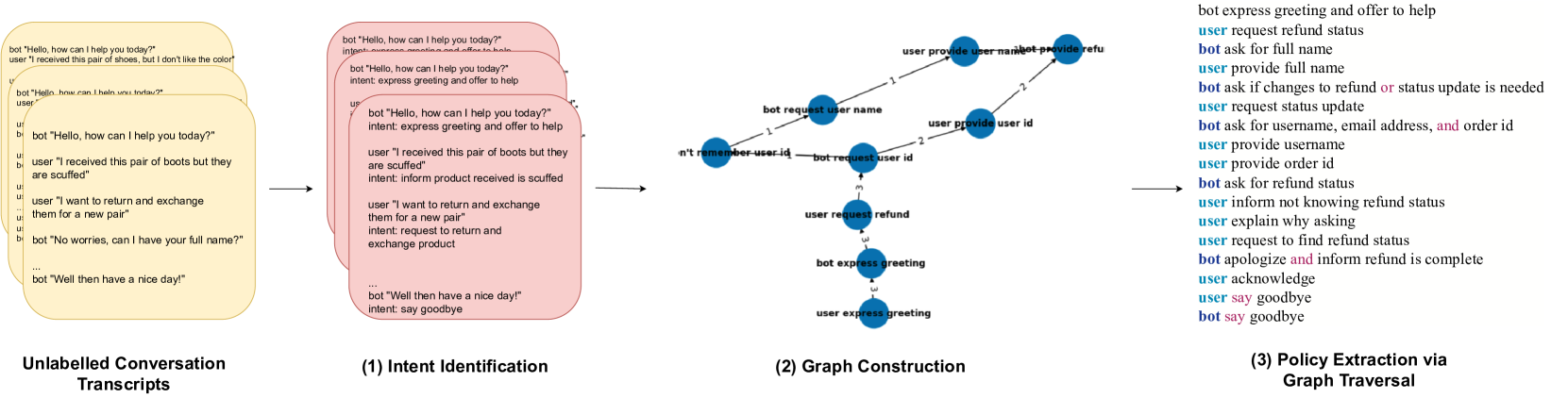
核心思路:论文的核心思路是利用大型语言模型(LLM)将对话转换为统一的中间表示(规范形式),然后将这些规范形式构建成一个图结构的对话流网络。通过图遍历算法,可以有效地提取对话策略。这种方法的核心在于将对话策略的学习问题转化为图结构上的路径搜索问题,从而利用图算法的优势。
技术框架:该方法主要包含以下几个阶段:1) 对话转换:使用LLM将原始对话数据转换为规范形式,例如将用户意图和系统行为表示为统一的语义表示。2) 图构建:将转换后的规范形式构建成一个有向图,节点表示对话状态,边表示状态之间的转移。边的权重可以根据状态转移的频率进行设置。3) 策略提取:在构建好的图上运行图遍历算法(例如深度优先搜索或广度优先搜索),提取对话流。这些对话流代表了潜在的对话策略。4) 策略优化:对提取的对话策略进行优化,例如通过规则或机器学习方法进行平滑和泛化。
关键创新:该方法最重要的创新点在于将对话策略提取问题转化为图结构上的路径搜索问题。与直接使用LLM生成对话策略相比,该方法具有更强的可控性和可解释性。通过图结构,可以更好地理解对话状态之间的转移关系,并提取更有效的对话策略。此外,该方法是无监督的,不需要人工标注数据。
关键设计:关键设计包括:1) 规范形式的设计:规范形式需要能够准确地表示用户意图和系统行为。2) 图结构的构建:图的节点和边的定义需要能够反映对话状态之间的转移关系。3) 图遍历算法的选择:不同的图遍历算法可能会提取不同的对话策略。4) 策略优化方法:需要选择合适的策略优化方法来提高对话策略的性能。
🖼️ 关键图片


📊 实验亮点
论文提出了一种基于图结构的无监督对话策略提取方法,该方法能够有效地从对话数据中提取对话策略。实验结果表明,该方法提取的对话策略比直接使用LLM生成的对话策略具有更好的性能。该方法还具有更强的可控性和可解释性,为对话设计者提供了更大的灵活性。
🎯 应用场景
该研究成果可应用于各种任务型对话系统,例如订票系统、客服机器人、智能助手等。通过自动提取对话策略,可以降低对话系统的开发成本,提高开发效率,并使对话系统能够更好地适应用户的需求。该方法还可以用于分析现有的对话数据,从而更好地理解用户的行为模式和对话策略。
📄 摘要(原文)
Dialogue policies play a crucial role in developing task-oriented dialogue systems, yet their development and maintenance are challenging and typically require substantial effort from experts in dialogue modeling. While in many situations, large amounts of conversational data are available for the task at hand, people lack an effective solution able to extract dialogue policies from this data. In this paper, we address this gap by first illustrating how Large Language Models (LLMs) can be instrumental in extracting dialogue policies from datasets, through the conversion of conversations into a unified intermediate representation consisting of canonical forms. We then propose a novel method for generating dialogue policies utilizing a controllable and interpretable graph-based methodology. By combining canonical forms across conversations into a flow network, we find that running graph traversal algorithms helps in extracting dialogue flows. These flows are a better representation of the underlying interactions than flows extracted by prompting LLMs. Our technique focuses on giving conversation designers greater control, offering a productivity tool to improve the process of developing dialogue policies.