Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
作者: Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
分类: cs.CL, cs.LG
发布日期: 2024-06-21
备注: Preprint
💡 一句话要点
提出基于浅层无监督多头注意力网络的类脑语言处理模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 类脑模型 多头注意力 语言处理 大脑对齐 行为对齐
📋 核心要点
- 现有大型语言模型在模拟人类语言处理方面表现出色,但其内部机制与大脑的关联性仍需深入研究。
- 该研究提出一种基于浅层无监督多头注意力网络的类脑语言处理模型,旨在揭示架构先验对大脑对齐的影响。
- 实验表明,tokenization策略和多头注意力是驱动大脑对齐的关键因素,该模型在行为对齐方面达到新的SOTA。
📝 摘要(中文)
大型语言模型(LLMs)已被证明是有效的人类语言系统模型,某些模型可以预测当前数据集中大脑活动的大部分可解释方差。即使在未经训练的模型中,由架构先验引起的表征也可以与大脑数据合理对齐。本文研究了驱动未经训练模型令人惊讶的对齐的关键架构组件。为了估计LLM与大脑的相似性,我们首先选择LLM中对语言敏感的单元,类似于神经科学家识别人脑中的语言网络的方式。然后,我们跨五个不同的脑记录数据集,对这些LLM单元的大脑对齐进行基准测试。通过隔离Transformer架构的关键组件,我们确定tokenization策略和多头注意力是驱动大脑对齐的两个主要组件。一种简单的递归形式进一步提高了对齐。我们进一步通过重现语言神经科学领域的标志性研究来证明我们模型的这种定量大脑对齐,表明局部模型单元——就像人脑中经验测量的语言体素一样——在词汇差异和句法差异之间进行更可靠的区分,并在相同的实验条件下表现出相似的反应曲线。最后,我们证明了我们模型的表征在语言建模中的效用,与同类架构相比,实现了更高的样本和参数效率。我们的模型对惊异度的估计在人类阅读时间的行为对齐方面设定了新的最先进水平。总而言之,我们提出了一个高度大脑和行为对齐的模型,该模型将人类语言系统概念化为一个未经训练的浅层特征编码器,具有结构先验,并结合一个经过训练的解码器来实现高效且高性能的语言处理。
🔬 方法详解
问题定义:现有的大型语言模型虽然在语言任务上取得了显著成果,但其内部表征与人类大脑的关联性以及哪些架构组件驱动这种关联性尚不明确。现有方法缺乏对模型架构与大脑活动之间关系的深入理解,难以解释模型的行为和预测能力。
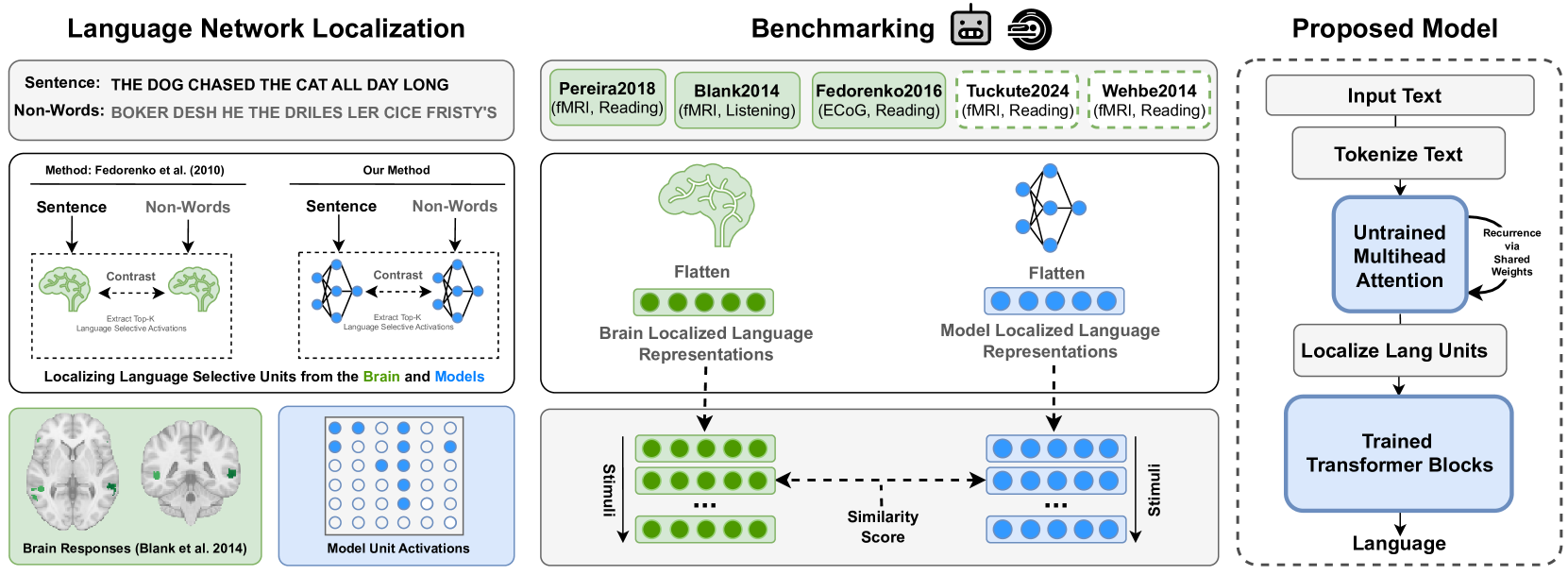
核心思路:该论文的核心思路是构建一个浅层、未经训练的多头注意力网络,并分析其与人类大脑语言处理区域的对齐程度。通过控制和消融不同的架构组件,研究人员旨在识别驱动大脑对齐的关键因素,从而更好地理解语言模型与人类语言处理之间的联系。
技术框架:该模型主要包括以下几个阶段:1) Tokenization:使用不同的tokenization策略对输入文本进行处理。2) 浅层多头注意力网络:构建一个浅层的Transformer架构,包含多头注意力机制。3) 大脑对齐评估:将模型内部表征与大脑活动数据进行比较,评估模型的脑对齐程度。4) 行为对齐评估:评估模型在预测人类阅读时间等行为指标方面的表现。
关键创新:该研究的关键创新在于:1) 强调了未经训练的浅层网络在模拟大脑语言处理方面的潜力。2) 揭示了tokenization策略和多头注意力机制在驱动大脑对齐中的重要作用。3) 通过重现神经科学研究,验证了模型的生物合理性。4) 提出了一个在行为对齐方面表现出色的模型,为理解人类语言处理提供了新的视角。
关键设计:该模型采用浅层Transformer架构,减少了训练的需要,更侧重于架构先验的影响。多头注意力机制允许模型关注输入序列的不同方面,从而更好地捕捉语言的复杂性。研究人员使用了多种tokenization策略,并评估了它们对大脑对齐的影响。此外,他们还引入了一种简单的递归形式,进一步提高了模型的性能。
🖼️ 关键图片


📊 实验亮点
该研究表明,一个浅层、未经训练的多头注意力网络可以实现与人类大脑语言处理区域的良好对齐。通过消融实验,研究人员发现tokenization策略和多头注意力机制是驱动大脑对齐的关键因素。此外,该模型在行为对齐方面取得了新的SOTA,超越了现有模型。
🎯 应用场景
该研究成果可应用于神经语言学领域,帮助研究人员更好地理解人类语言处理的神经机制。同时,该模型的设计思路可以为构建更高效、更具生物合理性的语言模型提供指导,应用于自然语言处理的各个领域,例如机器翻译、文本生成和对话系统。
📄 摘要(原文)
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.