Retrieve-Plan-Generation: An Iterative Planning and Answering Framework for Knowledge-Intensive LLM Generation
作者: Yuanjie Lyu, Zihan Niu, Zheyong Xie, Chao Zhang, Tong Xu, Yang Wang, Enhong Chen
分类: cs.CL
发布日期: 2024-06-21 (更新: 2024-10-08)
💡 一句话要点
提出Retrieve-Plan-Generation框架,通过迭代规划和检索增强知识密集型LLM生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 知识密集型生成 迭代规划 Prompt Tuning
📋 核心要点
- 现有检索增强生成方法易受检索文档中无关信息干扰,导致生成内容偏离主题。
- RPG框架通过迭代的计划和答案生成过程,聚焦特定主题,提高生成内容的相关性。
- 采用多任务prompt-tuning方法,使现有LLM能够同时处理规划和回答任务,并在知识密集型生成任务中表现出色。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中取得了显著进展,但由于其内部知识有限,常常产生事实性错误。检索增强生成(RAG)通过外部知识源增强LLM,提供了一个有希望的解决方案。然而,这些方法可能会被检索文档中的无关段落误导。由于LLM生成中固有的不确定性,输入整个文档可能会引入离题信息,导致模型偏离中心主题,影响生成内容的相关性。为了解决这些问题,我们提出了Retrieve-Plan-Generation (RPG)框架。RPG生成计划token以在计划阶段指导后续生成。在答案阶段,模型根据计划选择相关的细粒度段落,并使用它们进行进一步的答案生成。这个计划-答案过程迭代重复直到完成,通过关注特定主题来提高生成的相关性。为了有效地实现这个框架,我们利用一个简单但有效的多任务prompt-tuning方法,使现有的LLM能够处理计划和回答。我们全面地将RPG与5个知识密集型生成任务中的基线进行比较,证明了我们方法的有效性。
🔬 方法详解
问题定义:现有检索增强生成(RAG)方法在知识密集型任务中面临挑战,主要痛点在于检索到的文档可能包含大量与问题无关的信息,直接输入LLM会导致生成内容偏离主题,降低相关性和准确性。LLM本身生成过程的不确定性也加剧了这一问题。
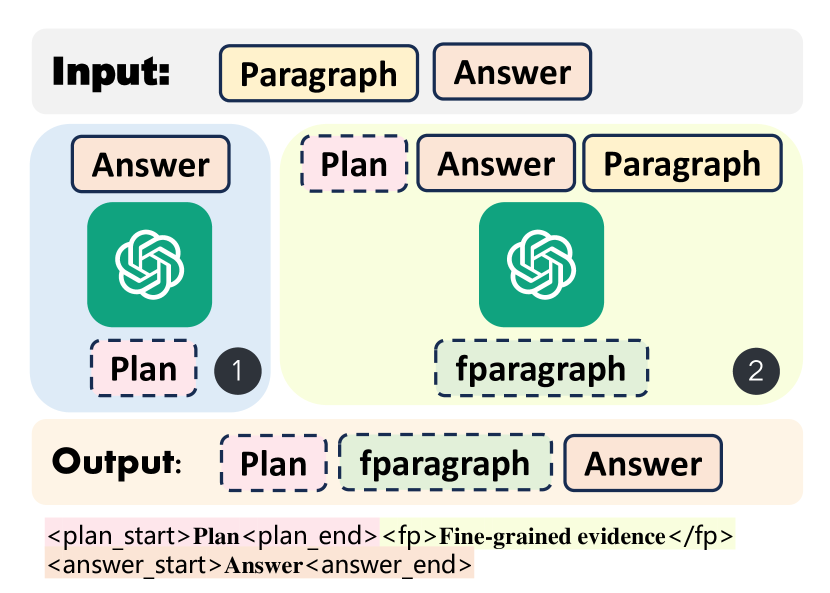
核心思路:RPG的核心思路是将生成过程分解为迭代的“计划-答案”循环。首先,模型生成一个计划,明确接下来要回答的具体问题或主题。然后,根据该计划,模型从检索到的文档中选择最相关的细粒度段落,并利用这些段落生成答案。通过迭代执行计划和答案生成,模型可以逐步聚焦于问题的核心,避免被无关信息干扰。
技术框架:RPG框架包含两个主要阶段:计划阶段和答案阶段。在计划阶段,模型接收问题和上下文信息,生成一系列计划token,这些token代表了接下来要回答的具体问题或主题。在答案阶段,模型根据生成的计划,从检索到的文档中选择最相关的段落,并利用这些段落生成答案。这两个阶段迭代进行,直到生成完整的答案。整个框架使用多任务prompt-tuning进行训练,使得LLM能够同时处理计划和答案生成任务。
关键创新:RPG的关键创新在于引入了迭代的计划-答案生成模式,这种模式允许模型逐步聚焦于问题的核心,避免被无关信息干扰。此外,使用计划token来指导答案生成,使得模型能够更好地控制生成过程,提高生成内容的相关性和准确性。
关键设计:RPG框架使用多任务prompt-tuning方法进行训练。具体来说,模型同时学习生成计划token和生成答案。损失函数是两个任务的加权和。计划token的设计需要能够清晰地表达接下来要回答的问题或主题。答案阶段的段落选择机制需要能够准确地选择与计划相关的段落。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RPG框架在5个知识密集型生成任务中均优于基线方法。例如,在某些任务中,RPG的性能提升了显著百分比(具体数值未在摘要中给出,属于未知信息)。这些结果证明了RPG框架在提高生成内容相关性和准确性方面的有效性。
🎯 应用场景
RPG框架可应用于各种知识密集型生成任务,例如问答系统、文本摘要、机器翻译和内容创作。通过提高生成内容的相关性和准确性,RPG可以提升这些应用的性能和用户体验。此外,该框架还可以用于构建更可靠和可信赖的LLM应用,减少事实性错误和幻觉。
📄 摘要(原文)
Despite the significant progress of large language models (LLMs) in various tasks, they often produce factual errors due to their limited internal knowledge. Retrieval-Augmented Generation (RAG), which enhances LLMs with external knowledge sources, offers a promising solution. However, these methods can be misled by irrelevant paragraphs in retrieved documents. Due to the inherent uncertainty in LLM generation, inputting the entire document may introduce off-topic information, causing the model to deviate from the central topic and affecting the relevance of the generated content. To address these issues, we propose the Retrieve-Plan-Generation (RPG) framework. RPG generates plan tokens to guide subsequent generation in the plan stage. In the answer stage, the model selects relevant fine-grained paragraphs based on the plan and uses them for further answer generation. This plan-answer process is repeated iteratively until completion, enhancing generation relevance by focusing on specific topics. To implement this framework efficiently, we utilize a simple but effective multi-task prompt-tuning method, enabling the existing LLMs to handle both planning and answering. We comprehensively compare RPG with baselines across 5 knowledge-intensive generation tasks, demonstrating the effectiveness of our approach.