A Tale of Trust and Accuracy: Base vs. Instruct LLMs in RAG Systems
作者: Florin Cuconasu, Giovanni Trappolini, Nicola Tonellotto, Fabrizio Silvestri
分类: cs.CL, cs.IR
发布日期: 2024-06-21
💡 一句话要点
RAG系统中Base LLM性能优于Instruct LLM,平均提升20%
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 Base LLM Instruct LLM 问答系统 知识库 性能评估
📋 核心要点
- 现有RAG系统过度依赖Instruct LLM,但其在RAG任务中的有效性缺乏充分验证。
- 该研究对比Base LLM和Instruct LLM在RAG任务中的表现,挑战了Instruct LLM的优越性假设。
- 实验结果表明,Base LLM在RAG任务中平均优于Instruct LLM 20%,引发对RAG系统设计的反思。
📝 摘要(中文)
检索增强生成(RAG)是人工智能领域的一项重大进展,它结合了检索阶段和生成阶段,后者通常由大型语言模型(LLM)驱动。目前RAG的常见做法是使用“instructed” LLM,这些模型经过监督训练进行微调,以增强其遵循指令的能力,并使用最先进的技术与人类偏好对齐。与普遍的看法相反,我们的研究表明,在我们的实验设置下,base模型在RAG任务中的表现平均优于其instructed模型20%。这一发现挑战了关于instructed LLM在RAG应用中优越性的普遍假设。进一步的调查揭示了一种更为细致的情况,质疑了RAG的基本方面,并表明需要对该主题进行更广泛的讨论。
🔬 方法详解
问题定义:论文旨在解决RAG系统中LLM选型问题,即在RAG流程中使用Instruct LLM是否总是最优选择。现有方法通常默认Instruct LLM更适合RAG,但缺乏充分的实验验证,可能导致性能瓶颈。
核心思路:论文的核心思路是通过对比实验,直接评估Base LLM和Instruct LLM在RAG任务中的性能差异。通过实验数据来验证或推翻Instruct LLM在RAG中的优越性假设,从而为RAG系统设计提供更合理的LLM选型依据。
技术框架:论文采用标准的RAG流程,包含检索和生成两个阶段。首先,使用检索模块从知识库中检索相关文档;然后,将检索到的文档和用户query输入到LLM中,生成最终答案。实验对比了不同类型的LLM(Base LLM和Instruct LLM)在相同RAG流程下的性能表现。
关键创新:该研究的关键创新在于挑战了RAG领域长期存在的假设,即Instruct LLM更适合RAG任务。通过实验证明,在特定设置下,Base LLM的性能甚至优于Instruct LLM,这颠覆了传统的认知,为RAG系统设计提供了新的视角。
关键设计:论文的关键设计在于构建了可控的实验环境,确保Base LLM和Instruct LLM在相同的RAG流程下进行公平比较。具体的技术细节包括:选择合适的评估指标(例如准确率、召回率等),控制检索模块的性能,以及使用相同的prompt模板来引导LLM生成答案。此外,论文还可能对不同类型的Instruct LLM进行了对比,以进一步分析其性能差异。
🖼️ 关键图片

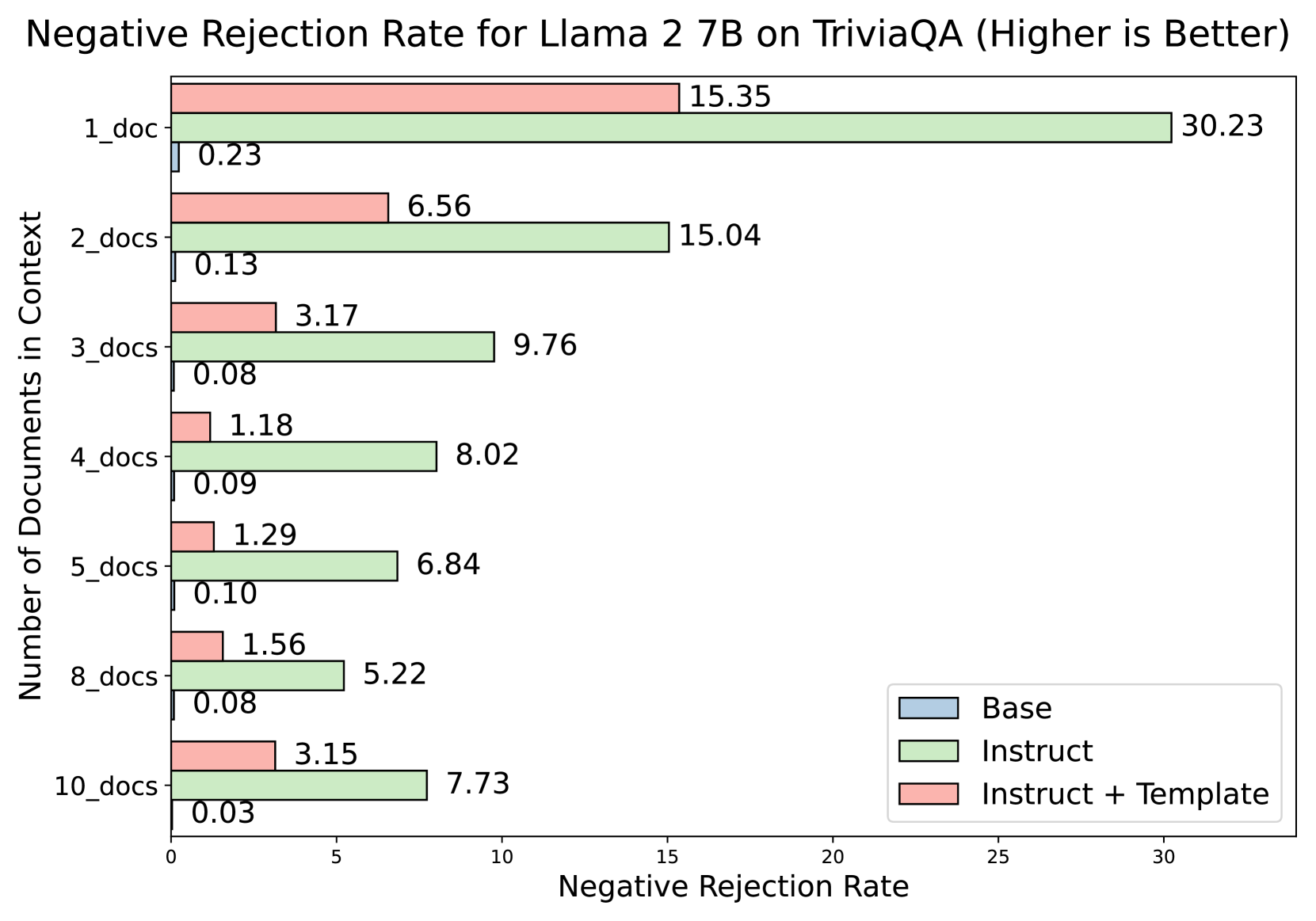
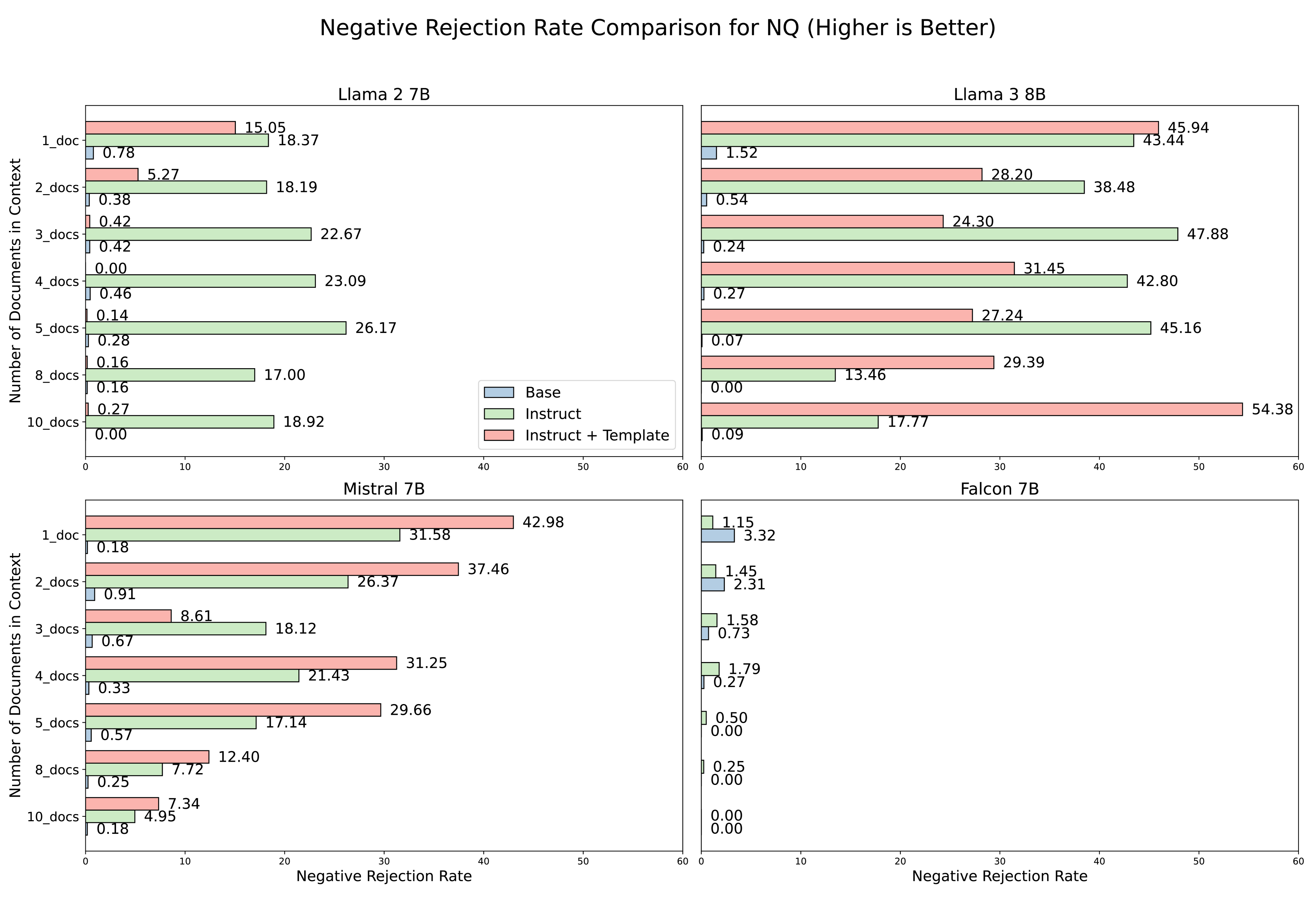
📊 实验亮点
实验结果表明,在特定的RAG任务设置下,Base LLM的性能平均优于Instruct LLM 20%。这一发现挑战了Instruct LLM在RAG应用中的普遍优越性假设。该研究还可能分析了不同类型的Instruct LLM的性能差异,并探讨了影响LLM性能的关键因素。
🎯 应用场景
该研究成果可应用于各种需要检索增强生成技术的场景,例如问答系统、文档摘要、知识库构建等。通过选择合适的LLM类型(Base或Instruct),可以优化RAG系统的性能,提高生成答案的准确性和相关性。该研究还为RAG系统的未来发展方向提供了新的思路,例如探索更有效的LLM微调方法,或设计更智能的RAG流程。
📄 摘要(原文)
Retrieval Augmented Generation (RAG) represents a significant advancement in artificial intelligence combining a retrieval phase with a generative phase, with the latter typically being powered by large language models (LLMs). The current common practices in RAG involve using "instructed" LLMs, which are fine-tuned with supervised training to enhance their ability to follow instructions and are aligned with human preferences using state-of-the-art techniques. Contrary to popular belief, our study demonstrates that base models outperform their instructed counterparts in RAG tasks by 20% on average under our experimental settings. This finding challenges the prevailing assumptions about the superiority of instructed LLMs in RAG applications. Further investigations reveal a more nuanced situation, questioning fundamental aspects of RAG and suggesting the need for broader discussions on the topic; or, as Fromm would have it, "Seldom is a glance at the statistics enough to understand the meaning of the figures".