Safely Learning with Private Data: A Federated Learning Framework for Large Language Model
作者: JiaYing Zheng, HaiNan Zhang, LingXiang Wang, WangJie Qiu, HongWei Zheng, ZhiMing Zheng
分类: cs.CR, cs.CL
发布日期: 2024-06-21 (更新: 2024-12-22)
备注: EMNLP 2024
DOI: 10.18653/v1/2024.emnlp-main.303
💡 一句话要点
提出FL-GLM:一种面向大语言模型的安全联邦学习框架,解决隐私泄露和效率问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大语言模型 隐私保护 梯度泄露 安全通信 模型分割 分布式训练
📋 核心要点
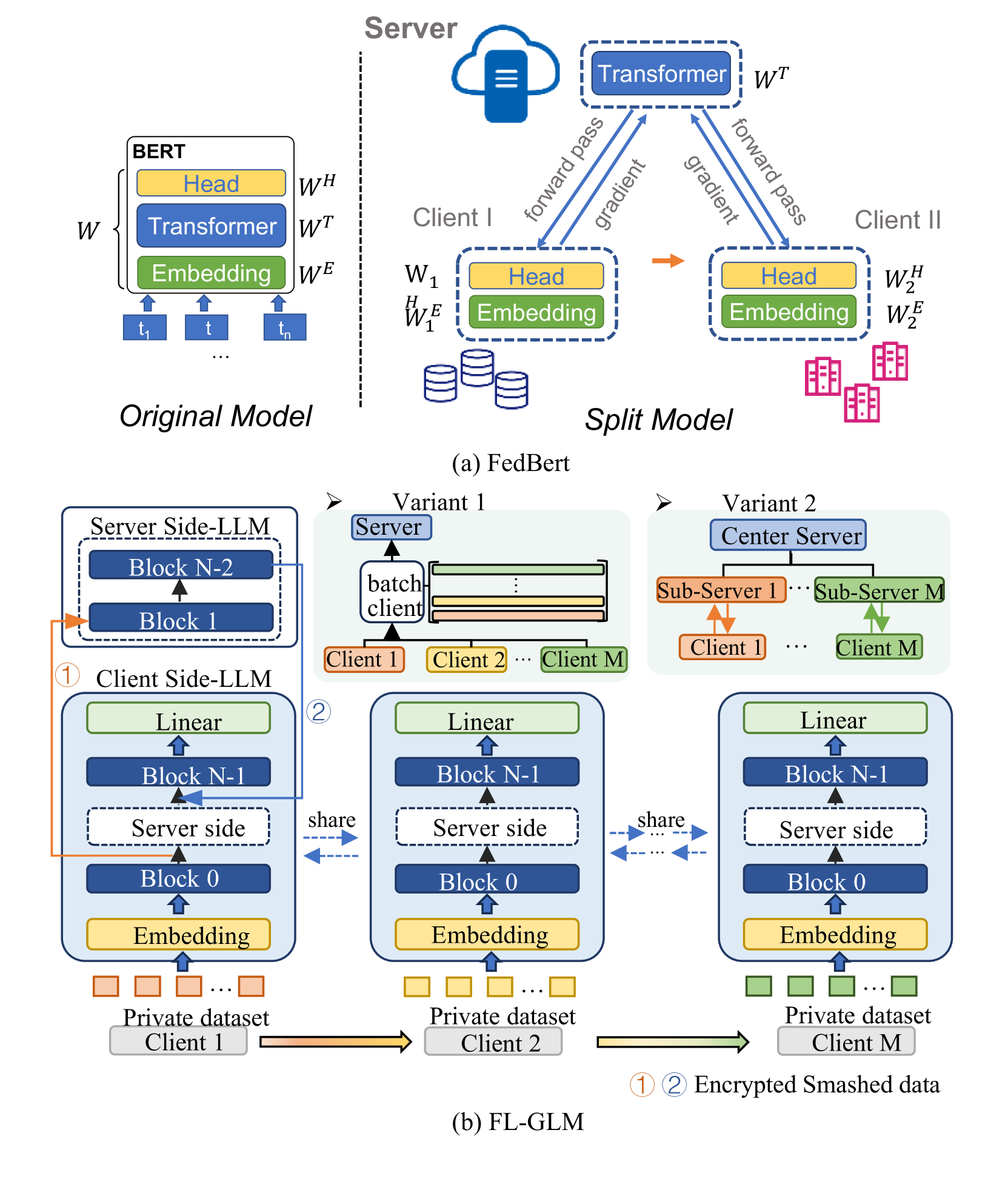
- 现有联邦学习方法(如FedAvg)计算开销大,不适用于大语言模型;拆分学习虽更适合,但存在梯度泄露和效率瓶颈。
- FL-GLM框架将输入输出块置于客户端,防止梯度攻击;采用密钥加密通信,防御对等客户端攻击;优化服务器端处理,提升并行训练效率。
- 实验结果表明,FL-GLM在NLU和生成任务上取得了与集中式ChatGLM模型相当的性能,验证了框架的有效性。
📝 摘要(中文)
私有数据比公共数据质量更高、规模更大,可以显著提升大语言模型(LLM)的性能。然而,由于隐私问题,这些数据通常分散在多个数据孤岛中,安全地利用这些数据进行LLM训练面临挑战。联邦学习(FL)是利用分布式私有数据训练模型的理想解决方案,但传统的框架(如FedAvg)因其对客户端的高计算需求而不适用于LLM。拆分学习将大部分训练参数卸载到服务器,同时在本地训练嵌入层和输出层,更适合LLM。然而,它在安全性和效率方面面临重大挑战。首先,嵌入层的梯度容易受到攻击,导致潜在的私有数据逆向工程。其次,服务器一次只能处理一个客户端的训练请求,这阻碍了并行训练,严重影响了训练效率。本文提出了一种用于LLM的联邦学习框架FL-GLM,该框架可防止服务器端和对等客户端攻击造成的数据泄露,同时提高训练效率。具体来说,我们首先将输入块和输出块放置在本地客户端,以防止来自服务器的嵌入梯度攻击。其次,我们在客户端-服务器通信期间采用密钥加密,以防止来自对等客户端的逆向工程攻击。最后,我们采用客户端批处理或服务器分层等优化方法,根据服务器的实际计算能力采用不同的加速方法。在NLU和生成任务上的实验结果表明,FL-GLM实现了与集中式chatGLM模型相当的指标,验证了我们联邦学习框架的有效性。
🔬 方法详解
问题定义:论文旨在解决在联邦学习场景下,如何安全高效地利用分散的私有数据训练大语言模型(LLM)的问题。现有方法,如FedAvg,由于LLM的巨大参数量,对客户端的计算能力要求过高。拆分学习虽然降低了客户端的计算负担,但存在嵌入层梯度泄露的风险,且服务器端串行处理客户端请求导致效率低下。
核心思路:论文的核心思路是在保证数据隐私的前提下,通过优化模型结构和通信方式,提升联邦学习训练LLM的效率。具体来说,通过将输入输出层放置在客户端,避免敏感信息的梯度泄露;通过密钥加密保护客户端间的通信;并通过服务器端的优化策略,实现客户端的并行训练。
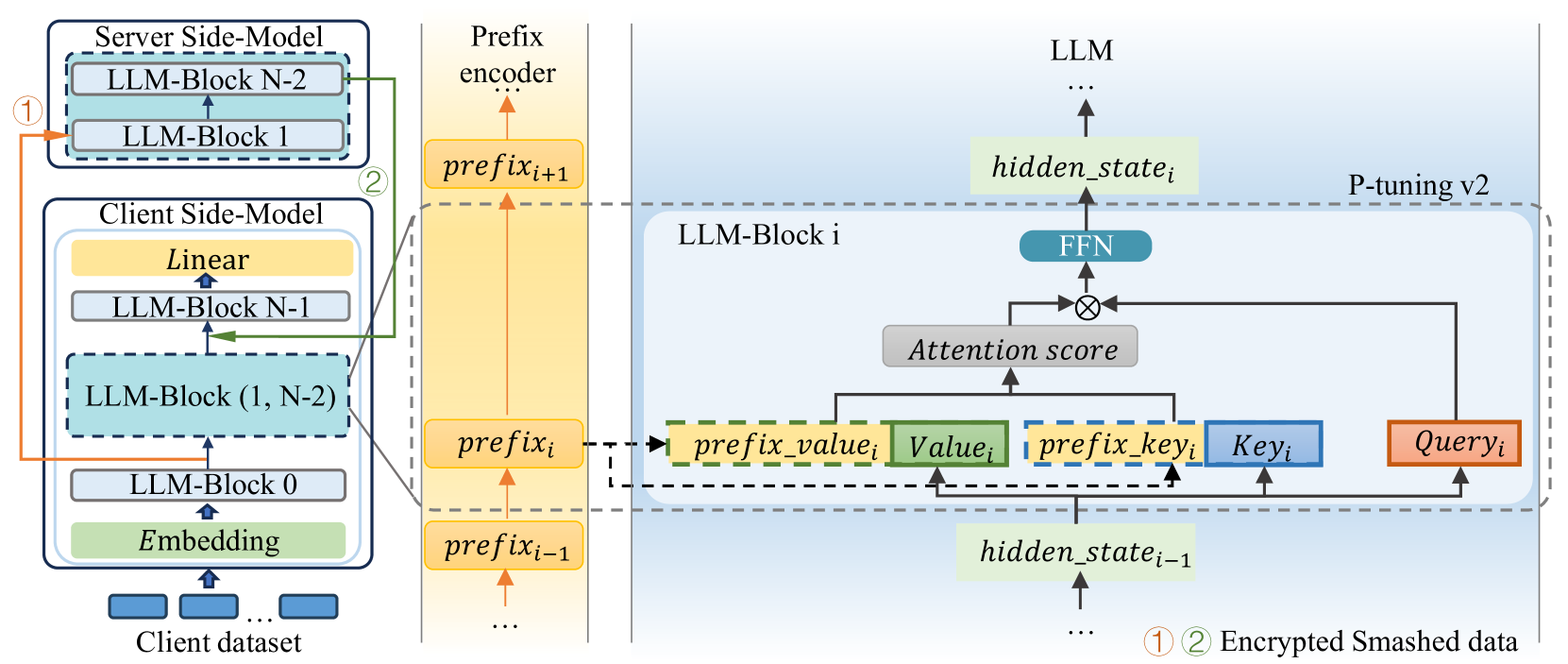
技术框架:FL-GLM框架主要包含以下几个模块:1) 客户端本地训练模块,负责处理输入输出层以及部分模型参数的训练;2) 安全通信模块,采用密钥加密技术保护客户端与服务器之间的梯度信息传输;3) 服务器端聚合模块,负责接收来自客户端的梯度信息,进行聚合更新模型参数,并采用客户端批处理或服务器分层等优化策略加速训练。
关键创新:论文的关键创新在于:1) 提出了一种新的模型分割策略,将输入输出层放置在客户端,有效防止了嵌入层梯度泄露;2) 引入密钥加密技术,增强了客户端之间通信的安全性,防止恶意客户端的攻击;3) 针对服务器端处理瓶颈,提出了客户端批处理和服务器分层等优化策略,显著提升了训练效率。
关键设计:在客户端,输入输出块的设计是关键,需要保证客户端能够独立完成前向和反向传播,同时减少与服务器的通信量。密钥加密算法的选择需要兼顾安全性和计算效率。服务器端的优化策略,如客户端批处理的大小、服务器分层的层数等,需要根据实际的硬件资源和网络状况进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FL-GLM框架在NLU和生成任务上取得了与集中式ChatGLM模型相当的性能指标,验证了该框架的有效性。这表明在保护数据隐私的前提下,联邦学习可以训练出具有竞争力的LLM模型。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于金融、医疗等对数据隐私要求高的领域,在保护用户数据安全的前提下,利用联邦学习训练高性能的大语言模型,提升智能客服、风险评估、疾病诊断等服务的质量。未来,该框架可以进一步扩展到其他类型的模型和任务,促进联邦学习在更多领域的应用。
📄 摘要(原文)
Private data, being larger and quality-higher than public data, can greatly improve large language models (LLM). However, due to privacy concerns, this data is often dispersed in multiple silos, making its secure utilization for LLM training a challenge. Federated learning (FL) is an ideal solution for training models with distributed private data, but traditional frameworks like FedAvg are unsuitable for LLM due to their high computational demands on clients. An alternative, split learning, offloads most training parameters to the server while training embedding and output layers locally, making it more suitable for LLM. Nonetheless, it faces significant challenges in security and efficiency. Firstly, the gradients of embeddings are prone to attacks, leading to potential reverse engineering of private data. Furthermore, the server's limitation of handle only one client's training request at a time hinders parallel training, severely impacting training efficiency. In this paper, we propose a Federated Learning framework for LLM, named FL-GLM, which prevents data leakage caused by both server-side and peer-client attacks while improving training efficiency. Specifically, we first place the input block and output block on local client to prevent embedding gradient attacks from server. Secondly, we employ key-encryption during client-server communication to prevent reverse engineering attacks from peer-clients. Lastly, we employ optimization methods like client-batching or server-hierarchical, adopting different acceleration methods based on the actual computational capabilities of the server. Experimental results on NLU and generation tasks demonstrate that FL-GLM achieves comparable metrics to centralized chatGLM model, validating the effectiveness of our federated learning framework.