70B-parameter large language models in Japanese medical question-answering
作者: Issey Sukeda, Risa Kishikawa, Satoshi Kodera
分类: cs.CL
发布日期: 2024-06-21
备注: 7 pages, 2 figures, 4 Tables
💡 一句话要点
利用70B参数大语言模型,通过指令微调提升日语医疗问答能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 日语医学问答 指令微调 领域自适应 医疗人工智能
📋 核心要点
- 现有医学LLM主要集中于英语数据集,日语医学领域的LLM研究相对匮乏,限制了其在日语医疗场景的应用。
- 论文核心在于利用多个70B参数的LLM,并采用日语医学问答数据集进行指令微调,以提升模型在日语医疗领域的性能。
- 实验结果表明,指令微调显著提高了日语LLM解决日语医师资格考试的能力,准确率超过50%,尤其日语模型提升更为明显。
📝 摘要(中文)
随着大型语言模型(LLMs)的兴起,领域自适应已成为各个领域的热门话题。许多使用英语医学数据集训练的医学LLM最近已公开发布。然而,日语医学领域的LLM研究仍然不足。本文首次利用多个70B参数的LLM,并表明使用日语医学问答数据集进行指令微调,可以显著提高日语LLM解决日语医师资格考试的能力,准确率超过50%。特别是,以日语为中心的模型通过指令微调获得的改进幅度比以英语为中心的模型更为显著。这突显了持续预训练和调整本地语言分词器的重要性。我们还研究了两种略有不同的提示格式,从而带来了不可忽略的性能提升。
🔬 方法详解
问题定义:论文旨在解决日语医学领域大型语言模型性能不足的问题。现有方法主要依赖于英语医学数据集训练的模型,在直接应用于日语医疗场景时效果不佳。痛点在于缺乏针对日语医学知识的有效训练和优化,导致模型无法准确理解和回答日语医学问题。
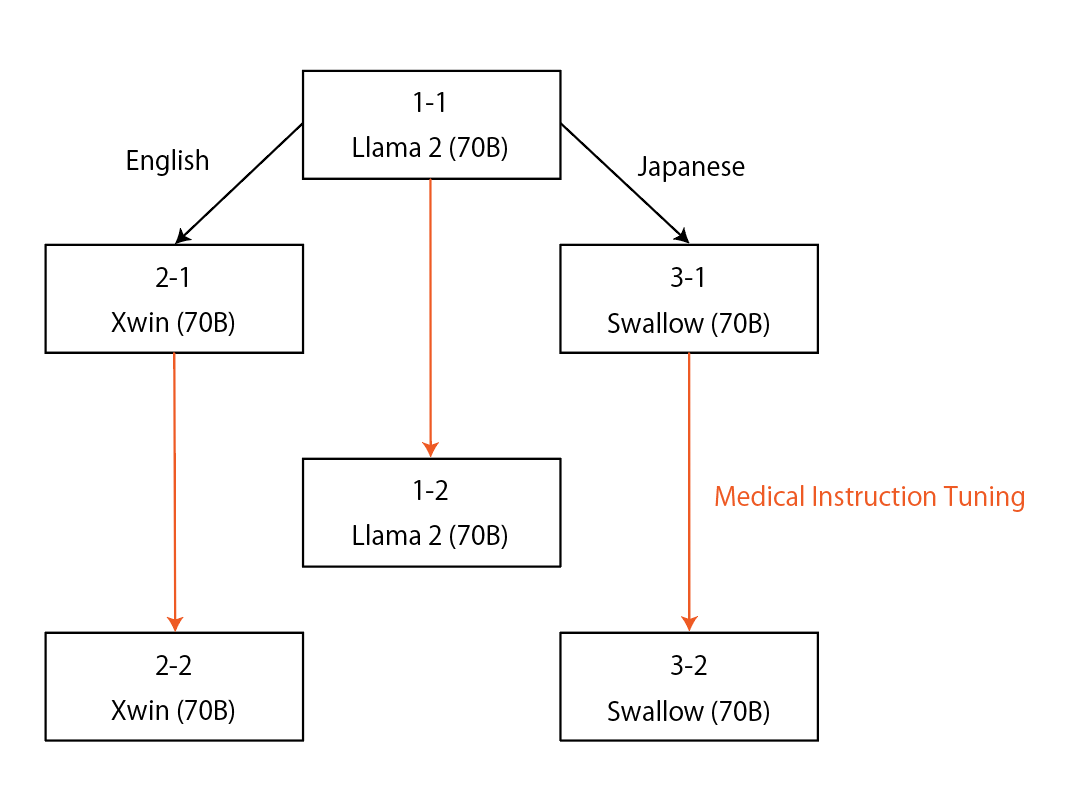
核心思路:论文的核心思路是利用大规模的日语医学问答数据集,对70B参数的LLM进行指令微调。通过指令微调,模型能够更好地理解和遵循日语医学领域的特定指令,从而提高其在日语医学问答任务中的性能。此外,论文还强调了持续预训练和调整本地语言分词器对于提升模型性能的重要性。
技术框架:整体框架包括以下几个主要步骤:1) 选择多个70B参数的LLM作为基础模型;2) 收集和整理日语医学问答数据集;3) 使用该数据集对基础模型进行指令微调;4) 评估微调后模型在日语医师资格考试等任务上的性能。论文还探索了两种不同的提示格式,以进一步优化模型性能。
关键创新:论文的关键创新在于首次将多个70B参数的LLM应用于日语医学问答领域,并通过指令微调显著提高了模型性能。与现有方法相比,该方法更加注重利用本地语言数据进行训练和优化,从而更好地适应日语医学领域的特定需求。此外,论文还强调了持续预训练和调整本地语言分词器对于提升模型性能的重要性。
关键设计:论文中关于指令微调的具体参数设置、损失函数和网络结构等技术细节并未详细描述,属于未知信息。但是,论文提到了探索两种不同的提示格式,这可能涉及到对输入指令的结构和内容的调整,以引导模型更好地理解和回答问题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过使用日语医学问答数据集进行指令微调,日语LLM在解决日语医师资格考试问题上的准确率超过50%。与以英语为中心的模型相比,以日语为中心的模型通过指令微调获得的性能提升更为显著,突显了本地语言数据的重要性。
🎯 应用场景
该研究成果可应用于智能医疗助手、医学知识库问答、辅助诊断等领域,为医生和患者提供更准确、便捷的日语医学信息服务。未来,该研究可进一步扩展到其他日语医疗场景,例如病历分析、药物研发等,具有广阔的应用前景。
📄 摘要(原文)
Since the rise of large language models (LLMs), the domain adaptation has been one of the hot topics in various domains. Many medical LLMs trained with English medical dataset have made public recently. However, Japanese LLMs in medical domain still lack its research. Here we utilize multiple 70B-parameter LLMs for the first time and show that instruction tuning using Japanese medical question-answering dataset significantly improves the ability of Japanese LLMs to solve Japanese medical license exams, surpassing 50\% in accuracy. In particular, the Japanese-centric models exhibit a more significant leap in improvement through instruction tuning compared to their English-centric counterparts. This underscores the importance of continual pretraining and the adjustment of the tokenizer in our local language. We also examine two slightly different prompt formats, resulting in non-negligible performance improvement.