An Analysis of Multilingual FActScore
作者: Kim Trong Vu, Michael Krumdick, Varshini Reddy, Franck Dernoncourt, Viet Dac Lai
分类: cs.CL
发布日期: 2024-06-20
💡 一句话要点
分析多语言环境下的FActScore,并提出知识源缓解策略以提升跨语言的事实性评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: FActScore 多语言 事实性评估 大型语言模型 知识源
📋 核心要点
- 现有FActScore主要针对英语,缺乏对多语言环境的有效性分析,限制了其跨语言应用。
- 论文通过分析FActScore各组件在多语言环境下的表现,揭示了其局限性,并提出了知识源缓解策略。
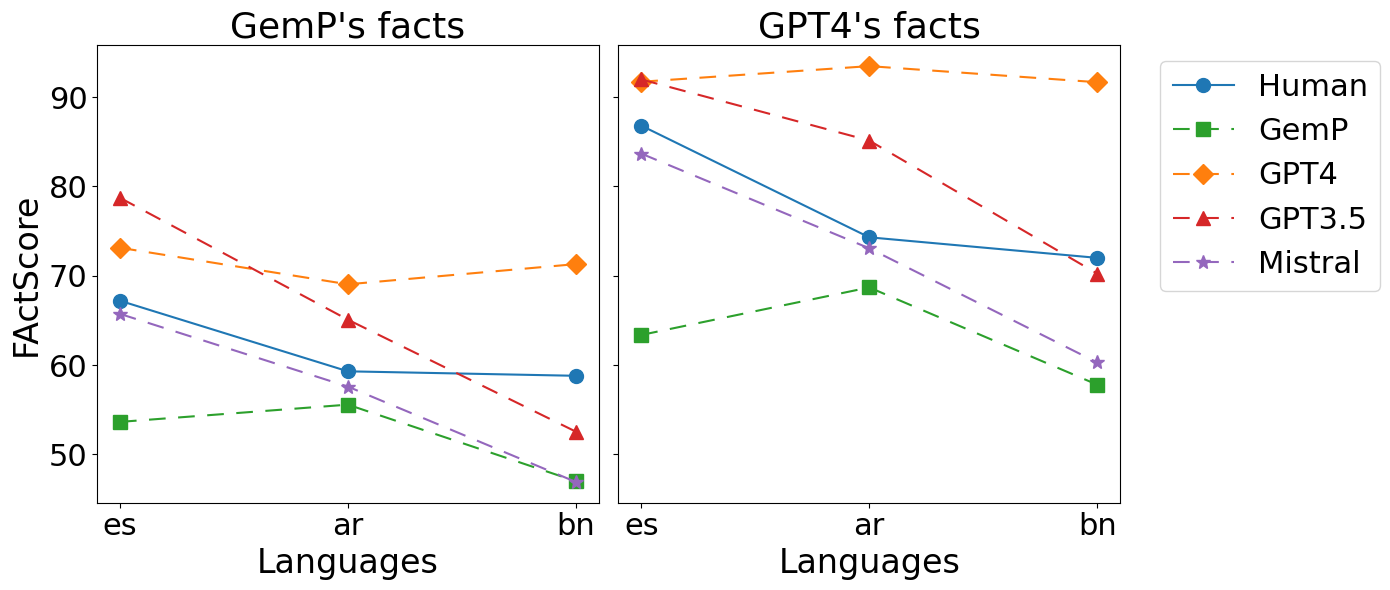
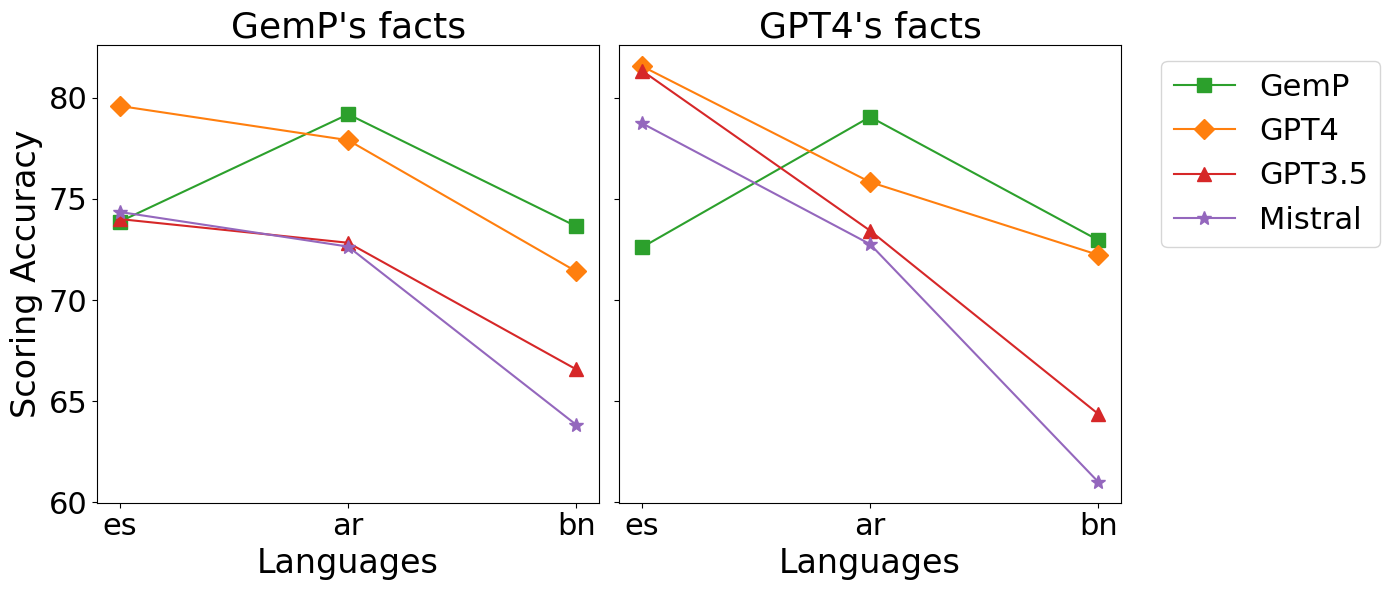
- 实验表明,不同语言的LLM在事实抽取和评分上存在差异,且知识源的质量显著影响FActScore的准确性。
📝 摘要(中文)
FActScore作为一种评估大型语言模型(LLM)生成的长文本事实性的指标,在英语中已得到广泛应用。然而,目前还没有研究探讨FActScore在其他语言中的表现。本文研究了FActScore四组件流程在多语言环境下的局限性。我们引入了一个新的数据集,用于评估强大的多语言LLM生成的文本的FActScore。我们的评估表明,LLM在事实抽取和事实评分任务中表现出不同的行为。没有LLM能够在不同资源水平的语言中产生一致且可靠的FActScore。我们还发现,知识源在估计FActScore的质量中起着重要作用。由于维基百科在中低资源语言中的覆盖范围有限,使用维基百科作为知识源可能会阻碍长文本的真实FActScore。我们还对知识源进行了三项缓解措施,最终提高了所有语言的FActScore估计。
🔬 方法详解
问题定义:FActScore旨在评估LLM生成文本的事实性,但在多语言环境下,由于语言资源、知识库覆盖率等差异,其性能表现未知。现有方法主要针对英语,缺乏对其他语言的适配性研究,导致跨语言事实性评估的准确性和可靠性降低。
核心思路:论文的核心思路是深入分析FActScore在多语言环境下的各个组成部分(事实抽取、事实评分等),识别其性能瓶颈,并针对性地提出改进措施。通过构建多语言数据集,评估不同LLM在不同语言上的FActScore表现,从而揭示FActScore的跨语言局限性。
技术框架:FActScore通常包含四个主要组件:1) 文本分割:将长文本分割成更小的单元;2) 事实抽取:从文本单元中提取事实陈述;3) 知识检索:从知识源(如维基百科)中检索相关信息;4) 事实评分:比较抽取的事实与检索到的信息,给出事实性得分。论文主要关注后三个组件在多语言环境下的表现,并针对知识源进行改进。
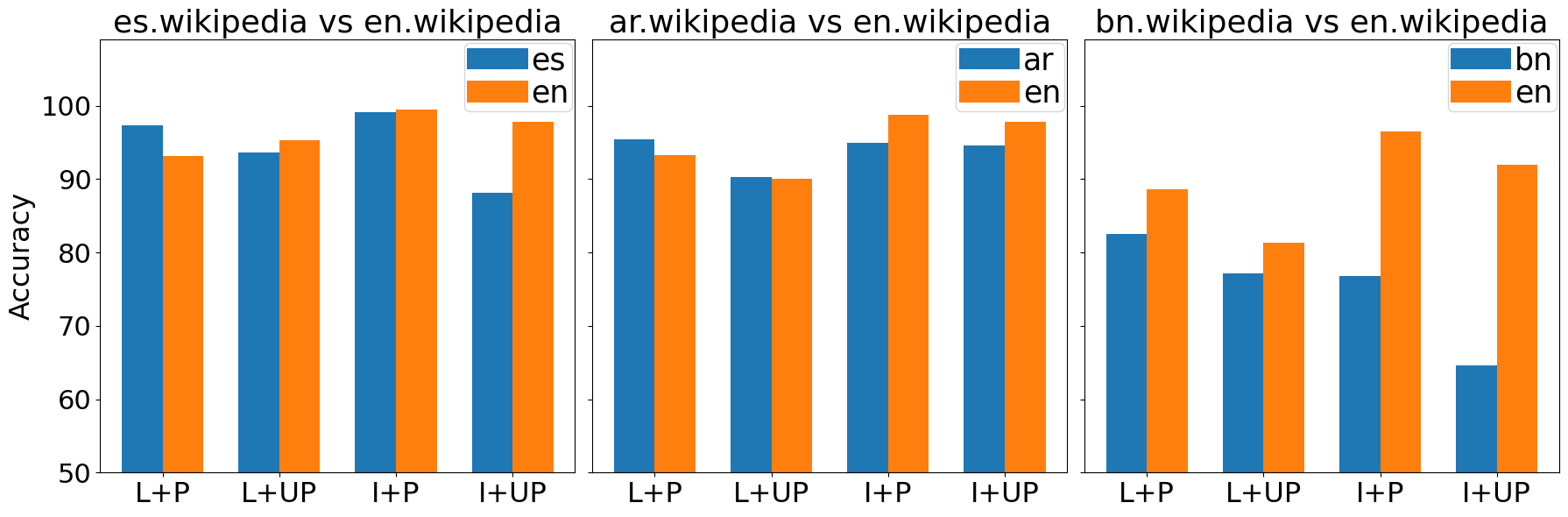
关键创新:论文的关键创新在于:1) 系统性地分析了FActScore在多语言环境下的局限性,揭示了不同语言和LLM之间的差异;2) 提出了针对知识源的缓解策略,以提高FActScore在低资源语言中的准确性。这些策略旨在弥补维基百科等知识库在低资源语言中的覆盖不足。
关键设计:论文针对知识源提出了三种缓解策略,具体细节未知。此外,论文构建了一个新的多语言数据集,用于评估FActScore在不同语言上的表现。数据集的构建过程和评估指标的具体选择未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM在不同语言上的FActScore表现存在显著差异,且知识源的质量对FActScore的准确性有重要影响。通过对知识源进行缓解,可以有效提高FActScore在所有语言上的估计质量,具体提升幅度未知。
🎯 应用场景
该研究成果可应用于多语言LLM的事实性评估,提高生成文本的可靠性和可信度。在跨语言信息检索、机器翻译、多语言内容生成等领域具有潜在应用价值。未来可进一步研究更有效的知识源构建方法,提升低资源语言的事实性评估能力。
📄 摘要(原文)
FActScore has gained popularity as a metric to estimate the factuality of long-form texts generated by Large Language Models (LLMs) in English. However, there has not been any work in studying the behavior of FActScore in other languages. This paper studies the limitations of each component in the four-component pipeline of FActScore in the multilingual setting. We introduce a new dataset for FActScore on texts generated by strong multilingual LLMs. Our evaluation shows that LLMs exhibit distinct behaviors in both fact extraction and fact scoring tasks. No LLM produces consistent and reliable FActScore across languages with varying levels of resources. We also find that the knowledge source plays an important role in the quality of the estimated FActScore. Using Wikipedia as the knowledge source may hinder the true FActScore of long-form text due to its limited coverage in medium- and low-resource languages. We also incorporate three mitigations to our knowledge source that ultimately improve FActScore estimation across all languages.