Learning to Retrieve Iteratively for In-Context Learning
作者: Yunmo Chen, Tongfei Chen, Harsh Jhamtani, Patrick Xia, Richard Shin, Jason Eisner, Benjamin Van Durme
分类: cs.CL
发布日期: 2024-06-20
💡 一句话要点
提出迭代检索框架,通过策略优化提升上下文学习的检索效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 迭代检索 强化学习 语义解析 策略优化
📋 核心要点
- 现有上下文学习(ICL)示例选择方法通常是静态的,无法根据LLM的反馈进行迭代优化,导致检索效果受限。
- 本文提出迭代检索框架,通过强化学习训练检索策略,使检索器能够根据LLM的反馈进行迭代决策,优化检索结果。
- 实验表明,该方法在语义解析任务上优于现有ICL示例选择方法,并且具有良好的泛化能力,可应用于不同的LLM。
📝 摘要(中文)
本文提出了一种新颖的迭代检索框架,该框架通过策略优化使检索器能够进行迭代决策。寻找最优的检索项组合是一个组合优化问题,通常被认为是NP-hard问题。本文方法为该问题提供了一种学习到的近似解,满足特定任务需求以及给定的大语言模型(LLM)。我们提出了一种基于强化学习的训练过程,其中融入了来自LLM的反馈。我们将迭代检索器实例化,用于组合上下文学习(ICL)示例,并将其应用于需要合成程序作为输出的各种语义解析任务。通过仅增加4M的额外参数用于状态编码,我们将一个现成的密集检索器转换为有状态的迭代检索器,在CalFlow、TreeDST和MTOP等语义解析数据集上,优于先前的ICL示例选择方法。此外,训练后的迭代检索器可以泛化到训练期间未使用的不同推理LLM。
🔬 方法详解
问题定义:论文旨在解决上下文学习(ICL)中,如何更有效地选择示例的问题。现有的方法通常采用单次检索,无法根据大语言模型(LLM)的反馈进行调整,导致检索到的示例可能并非最优,影响LLM的性能。组合优化问题,即找到最佳的检索项组合,通常被认为是NP-hard问题,难以直接求解。
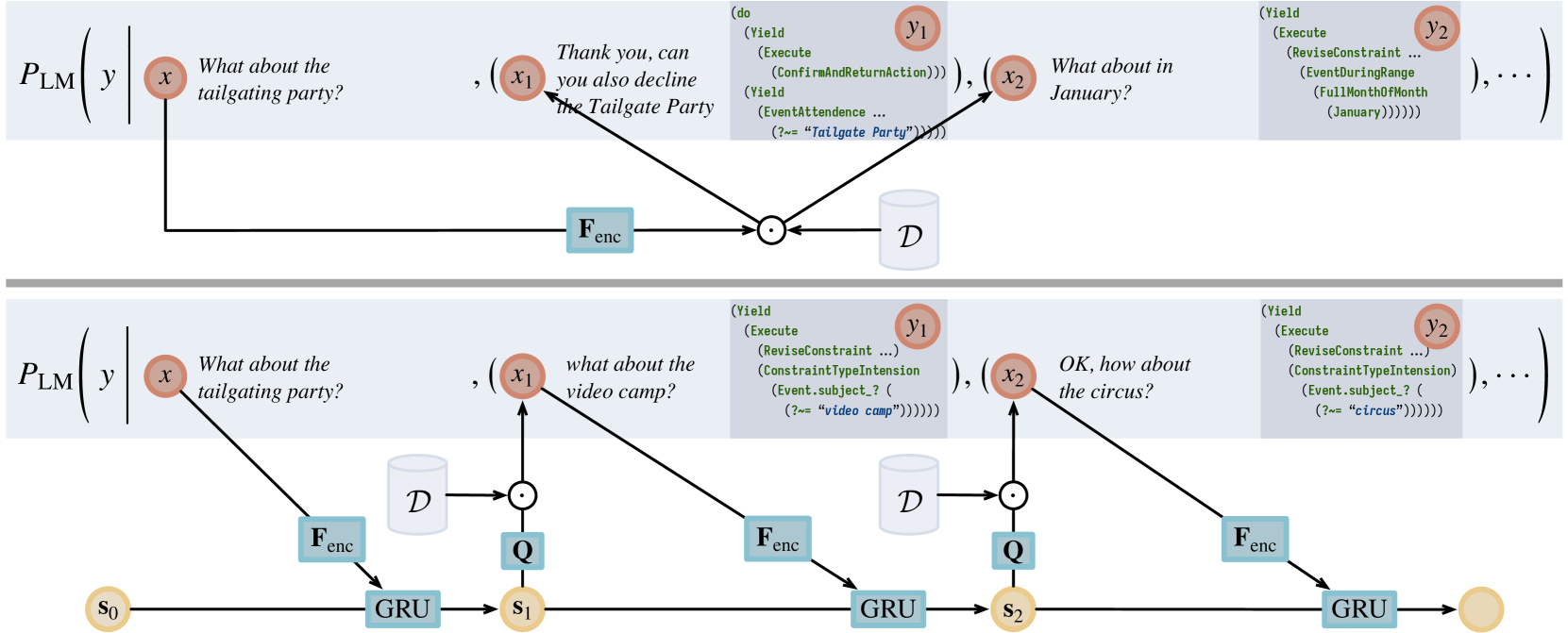
核心思路:论文的核心思路是将示例检索过程建模为一个马尔可夫决策过程(MDP),并使用强化学习来训练一个策略,该策略能够根据LLM的反馈,迭代地选择示例。通过迭代检索,检索器可以逐步构建一个更有效的上下文,从而提高LLM的性能。
技术框架:整体框架包含一个状态编码器、一个策略网络和一个LLM。状态编码器用于编码当前已选择的示例和查询,策略网络根据状态选择下一个要检索的示例,LLM则根据当前上下文生成输出,并提供反馈信号(例如,奖励)。整个过程迭代进行,直到达到预定的迭代次数或满足停止条件。强化学习算法用于优化策略网络,使其能够选择更有助于LLM完成任务的示例。
关键创新:关键创新在于将示例检索过程建模为一个迭代决策过程,并利用强化学习来优化检索策略。与传统的单次检索方法相比,该方法能够根据LLM的反馈进行动态调整,从而选择更有效的示例。此外,通过引入状态编码器,该方法能够处理复杂的上下文信息,并学习到更有效的检索策略。
关键设计:状态编码器使用一个小型神经网络(4M参数)来编码当前已选择的示例和查询。策略网络使用一个多层感知机(MLP)来预测下一个要检索的示例。奖励函数的设计至关重要,论文中使用了LLM的输出质量作为奖励信号。强化学习算法使用了策略梯度方法,例如REINFORCE或PPO。迭代次数和停止条件需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在CalFlow、TreeDST和MTOP等语义解析数据集上,优于先前的ICL示例选择方法。通过仅增加4M的额外参数,就能够显著提升检索效果。此外,训练后的迭代检索器可以泛化到训练期间未使用的不同推理LLM,表明该方法具有良好的泛化能力。具体提升幅度未知,需要查阅原论文。
🎯 应用场景
该研究成果可应用于各种需要上下文学习的自然语言处理任务,例如语义解析、机器翻译、文本摘要等。通过迭代检索,可以更有效地选择示例,提高LLM的性能。该方法还可以应用于信息检索、推荐系统等领域,通过迭代地选择相关文档或商品,提高用户满意度。
📄 摘要(原文)
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.