Factual Dialogue Summarization via Learning from Large Language Models
作者: Rongxin Zhu, Jey Han Lau, Jianzhong Qi
分类: cs.CL
发布日期: 2024-06-20
💡 一句话要点
提出基于大语言模型知识蒸馏的对话摘要方法,提升小模型的factual consistency。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话摘要 知识蒸馏 大语言模型 事实一致性 对比学习
📋 核心要点
- 现有对话摘要模型在事实一致性方面存在不足,大模型虽性能更优,但部署成本高昂。
- 利用大语言模型提取符号知识,构造对比学习数据集,提升小模型的事实一致性。
- 实验表明,该方法在BART、PEGASUS和Flan-T5等模型上,显著提升了摘要的事实一致性。
📝 摘要(中文)
对话摘要中,事实一致性至关重要。基于大语言模型(LLM)的自动文本摘要模型,相比于较小的预训练语言模型,能生成事实一致性更高的摘要。但由于隐私或资源限制,LLM在实际应用中面临部署挑战。本文研究了使用符号知识蒸馏来提高较小预训练模型在对话摘要任务中的事实一致性。我们采用零样本学习从LLM中提取符号知识,生成事实一致(正样本)和不一致(负样本)的摘要。然后,我们在这些摘要上应用两种对比学习目标,以增强较小的摘要模型。对BART、PEGASUS和Flan-T5的实验表明,我们的方法优于依赖复杂数据增强策略的强大基线。各种自动评估指标证实,我们的方法在保持连贯性、流畅性和相关性的同时,实现了更好的事实一致性。我们还提供了数据和代码,以方便未来的研究。
🔬 方法详解
问题定义:对话摘要任务旨在生成简洁且准确的对话总结。现有方法,尤其是基于较小预训练语言模型的摘要模型,在生成摘要时容易出现事实性错误,导致摘要与原始对话不一致。大语言模型虽然能生成更准确的摘要,但其高昂的计算成本和潜在的隐私问题限制了其在实际场景中的应用。
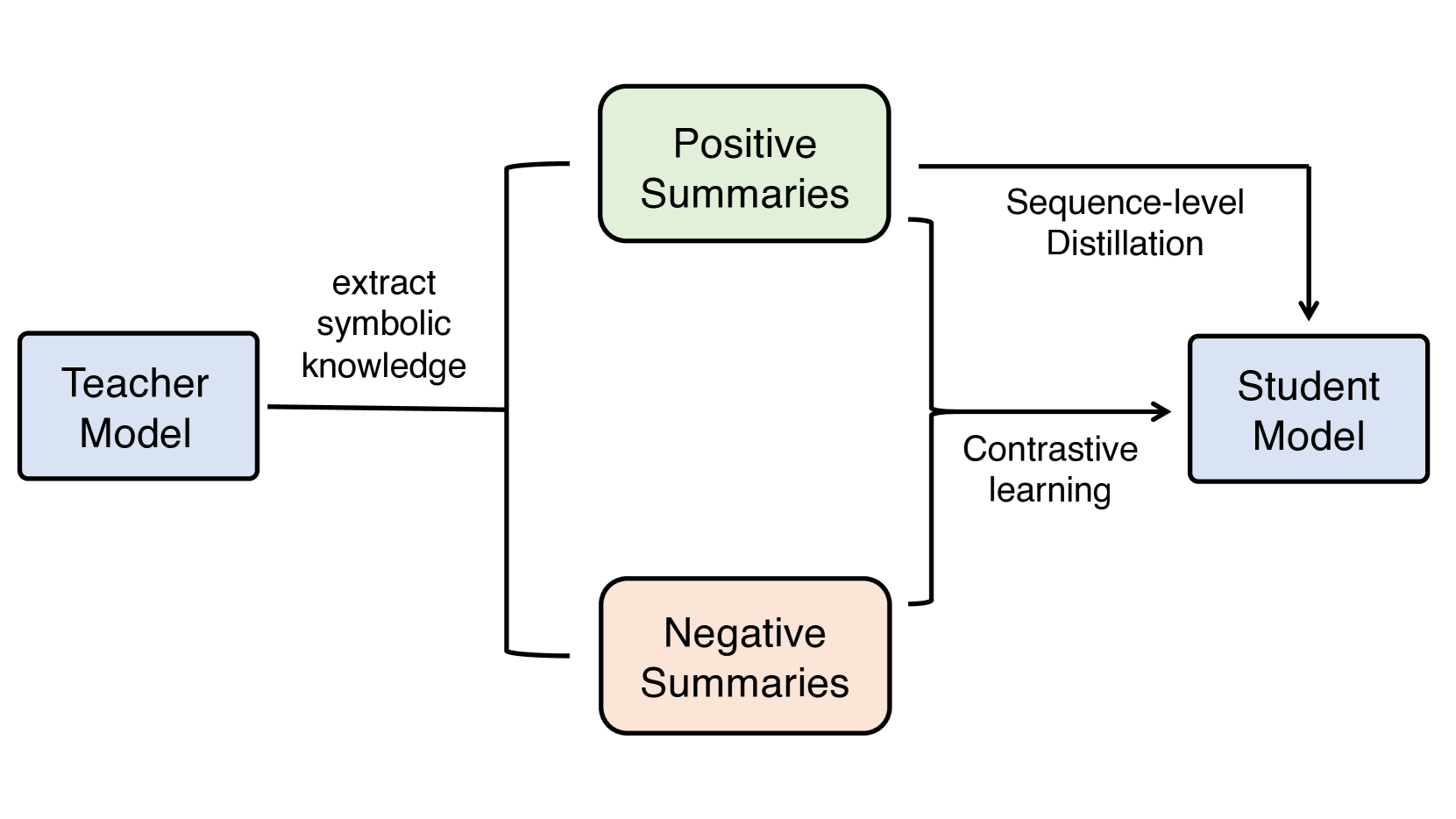
核心思路:本文的核心思路是利用大语言模型(LLM)的知识,通过知识蒸馏的方式提升小模型的事实一致性。具体来说,首先利用LLM生成高质量的摘要(包括事实一致和不一致的摘要),然后将这些摘要作为训练数据,通过对比学习的方式训练小模型,使其学习到LLM的知识,从而提高其生成摘要的事实一致性。
技术框架:该方法主要包含以下几个阶段: 1. LLM摘要生成:使用LLM对对话进行零样本摘要生成,同时生成事实一致和不一致的摘要。 2. 对比学习数据构造:将LLM生成的摘要作为对比学习的训练数据,其中事实一致的摘要作为正样本,事实不一致的摘要作为负样本。 3. 小模型训练:使用对比学习目标函数训练小模型,使其学习区分事实一致和不一致的摘要,从而提高其生成摘要的事实一致性。
关键创新:该方法最重要的创新点在于利用LLM的零样本摘要生成能力,自动构造对比学习数据集,避免了人工标注的成本。此外,通过对比学习的方式,可以更有效地将LLM的知识迁移到小模型中,从而提高小模型的事实一致性。与传统的数据增强方法相比,该方法能够更有效地提升模型的事实一致性。
关键设计:该方法使用了两种对比学习目标函数,旨在最大化正样本摘要的相似度,同时最小化负样本摘要的相似度。具体的损失函数形式未知,需要在论文中查找。此外,LLM的选择和prompt的设计也会影响摘要的质量,从而影响最终的性能。小模型的选择也是一个重要的设计因素,需要根据具体的应用场景进行选择。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在BART、PEGASUS和Flan-T5等模型上均取得了显著的性能提升,超过了依赖复杂数据增强策略的基线方法。具体的数据提升幅度未知,需要在论文中查找。该方法在提升事实一致性的同时,保持了摘要的连贯性、流畅性和相关性。
🎯 应用场景
该研究成果可应用于各种需要对话摘要的场景,例如客服对话总结、会议记录生成、在线教育内容提炼等。通过提升摘要的事实一致性,可以提高用户对摘要的信任度,并减少因错误信息带来的负面影响。该方法有助于在资源受限的环境下部署高质量的对话摘要系统,具有重要的实际应用价值。
📄 摘要(原文)
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.