Evidence of a log scaling law for political persuasion with large language models
作者: Kobi Hackenburg, Ben M. Tappin, Paul Röttger, Scott Hale, Jonathan Bright, Helen Margetts
分类: cs.CL, cs.AI, cs.CY, cs.HC
发布日期: 2024-06-20
备注: 16 pages, 4 figures
💡 一句话要点
研究表明:大型语言模型政治说服力遵循对数比例定律,边际效益递减
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治说服 对数比例定律 边际效益递减 随机调查实验
📋 核心要点
- 现有研究对大型语言模型在政治说服方面的能力关注不足,尤其缺乏对其说服力随模型规模变化的定量分析。
- 该研究通过生成大量政治信息并进行大规模调查实验,量化评估了不同规模语言模型的说服能力。
- 实验结果表明,模型说服力遵循对数比例定律,边际效益递减,且任务完成度是影响说服力的关键因素。
📝 摘要(中文)
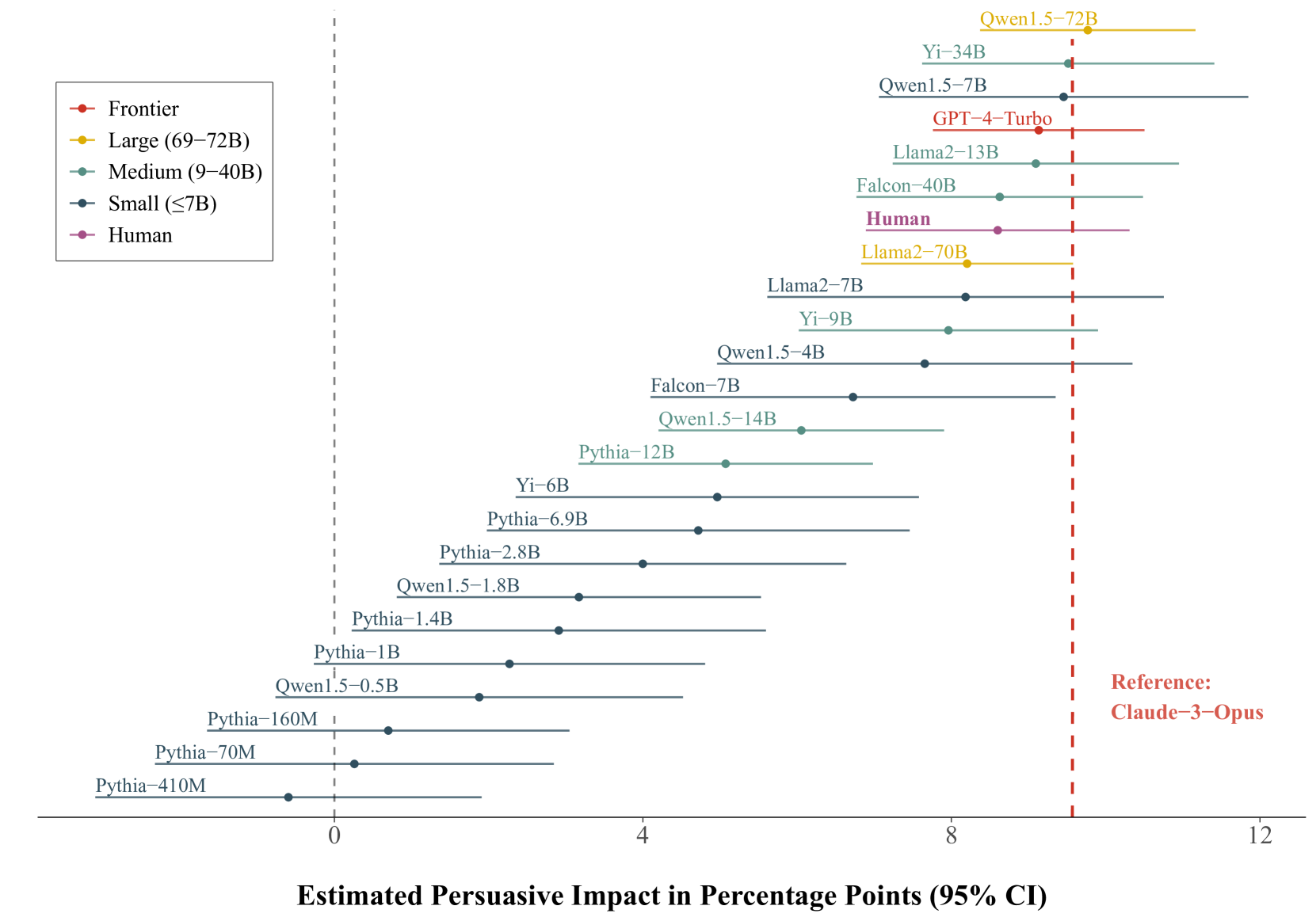
大型语言模型现在可以生成与人类撰写的一样具有说服力的政治信息,这引发了人们对这种说服力可能随着模型规模的增加而持续增长的担忧。本文利用24个不同规模的语言模型,针对10个美国政治问题生成了720条具有说服力的信息。然后,在一个大规模的随机调查实验(N = 25,982)中部署这些信息,以评估每个模型的说服能力。研究结果表明:首先,模型说服力呈现出对数比例定律的特征,即边际效益急剧递减,当前最先进的模型与规模小一个数量级或更多的模型相比,说服力几乎没有提高。其次,仅仅完成任务(连贯性、保持主题)似乎是较大模型具有说服优势的原因。这些发现表明,进一步扩大模型规模不会显著提高静态LLM生成信息的说服力。
🔬 方法详解
问题定义:该论文旨在研究大型语言模型(LLM)在政治说服方面的能力,并分析其说服力与模型规模之间的关系。现有方法缺乏对LLM说服力的定量评估,以及对模型规模与说服力之间关系的深入理解,无法预测模型规模增长带来的实际收益。
核心思路:核心思路是通过生成不同规模LLM产生的政治信息,并将其应用于大规模的随机调查实验中,以此来量化评估每个模型的说服能力。通过分析模型规模与说服力之间的关系,揭示LLM在政治说服方面的边际效益。
技术框架:整体框架包括以下几个阶段: 1. 模型选择:选择24个不同规模的LLM,涵盖多个数量级。 2. 信息生成:针对10个美国政治问题,每个模型生成一定数量的具有说服力的信息(共720条)。 3. 实验部署:将生成的政治信息部署到大规模的随机调查实验中(N = 25,982)。 4. 说服力评估:通过分析调查结果,量化评估每个模型的说服能力。 5. 关系分析:分析模型规模与说服力之间的关系,验证对数比例定律。
关键创新:该研究的关键创新在于: 1. 大规模实验:通过大规模的随机调查实验,对LLM的说服力进行了量化评估,避免了主观评价的偏差。 2. 对数比例定律:发现了LLM在政治说服方面遵循对数比例定律,揭示了模型规模增长带来的边际效益递减现象。 3. 任务完成度:强调了任务完成度(连贯性、保持主题)在LLM说服力中的重要作用。
关键设计: 1. 模型选择:选择了涵盖多个数量级的LLM,以确保研究结果的普适性。 2. 信息生成:采用了明确的提示工程(prompt engineering)方法,以确保生成的政治信息具有一定的说服力。 3. 实验设计:采用了随机对照实验的设计,以消除潜在的偏差。 4. 说服力评估:采用了多种指标来评估模型的说服力,包括态度改变、行为意愿等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,模型说服力遵循对数比例定律,即模型规模增加一个数量级,其说服力提升幅度显著减小。当前最先进的模型与规模小一个数量级或更多的模型相比,说服力几乎没有提高。此外,研究发现,仅仅完成任务(连贯性、保持主题)是较大模型具有说服优势的主要原因。
🎯 应用场景
该研究成果可应用于评估和预测大型语言模型在政治宣传、舆论引导等领域的潜在影响。有助于政策制定者和研究人员更好地理解和应对AI技术带来的挑战,并为开发更负责任和可信赖的AI系统提供指导。此外,该研究也为其他领域的大模型应用提供了参考,例如广告营销、公共关系等。
📄 摘要(原文)
Large language models can now generate political messages as persuasive as those written by humans, raising concerns about how far this persuasiveness may continue to increase with model size. Here, we generate 720 persuasive messages on 10 U.S. political issues from 24 language models spanning several orders of magnitude in size. We then deploy these messages in a large-scale randomized survey experiment (N = 25,982) to estimate the persuasive capability of each model. Our findings are twofold. First, we find evidence of a log scaling law: model persuasiveness is characterized by sharply diminishing returns, such that current frontier models are barely more persuasive than models smaller in size by an order of magnitude or more. Second, mere task completion (coherence, staying on topic) appears to account for larger models' persuasive advantage. These findings suggest that further scaling model size will not much increase the persuasiveness of static LLM-generated messages.