Modeling Human Subjectivity in LLMs Using Explicit and Implicit Human Factors in Personas
作者: Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, João Sedoc, Lyle H. Ungar, Brenda Curtis
分类: cs.CL
发布日期: 2024-06-20 (更新: 2024-10-17)
备注: Accepted at Findings of EMNLP 2024
💡 一句话要点
利用显性和隐性人类因素构建LLM中的主观性建模
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人类主观性 角色建模 社会科学 偏见分析
📋 核心要点
- 现有LLM在社会科学任务中缺乏人类主观性,导致数据多样性不足,无法充分反映人类经验。
- 论文提出通过显式或隐式地赋予LLM类人角色,模拟不同人口统计特征和生活经验对模型行为的影响。
- 实验表明,显式角色在重现已知偏见时结果不一,而隐式角色难以展示隐性偏见,表明LLM难以建模复杂的人类感知。
📝 摘要(中文)
大型语言模型(LLM)越来越多地应用于以人为中心的社会科学任务中,例如数据标注、合成数据创建和对话交互。然而,这些任务具有高度的主观性,并依赖于人类因素,如环境、态度、信仰和生活经验。因此,在这些任务中使用不具备这些人类因素的LLM可能会导致数据缺乏多样性,无法反映人类经验的多样性。本文探讨了使用类人角色提示LLM,并要求模型像特定的人一样回答的角色。这可以通过显式方式(使用确切的人口统计信息、政治信仰和生活经验)或隐式方式(通过特定人群中流行的名字)来实现。然后通过(1)主观标注任务(例如,检测毒性)和(2)信念生成任务来评估LLM角色,这两个任务已知会因人类因素而异。我们研究了显式与隐式角色提示的影响,并调查了LLM识别和响应哪些人类因素。结果表明,显式LLM角色在重现已知的人类偏见时表现出混合的结果,但通常无法展示隐性偏见。我们得出结论,LLM可能捕捉到人们说话方式的统计模式,但通常无法模拟人类感知的复杂交互和微妙之处,这可能会限制它们在社会科学应用中的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在模拟人类主观性方面的不足,尤其是在社会科学相关任务中。现有方法未能充分考虑人类因素(如人口统计学特征、信仰和生活经验)对LLM行为的影响,导致模型输出缺乏多样性,无法准确反映真实世界中人类的复杂性。
核心思路:论文的核心思路是通过赋予LLM类人角色(personas),使其能够模拟不同人类个体的主观性。这些角色可以通过显式方式(明确指定人口统计信息、政治信仰和生活经验)或隐式方式(使用特定人群中常见的名字)来定义。通过观察LLM在不同角色下的行为,研究人员可以评估模型对不同人类因素的敏感性和建模能力。
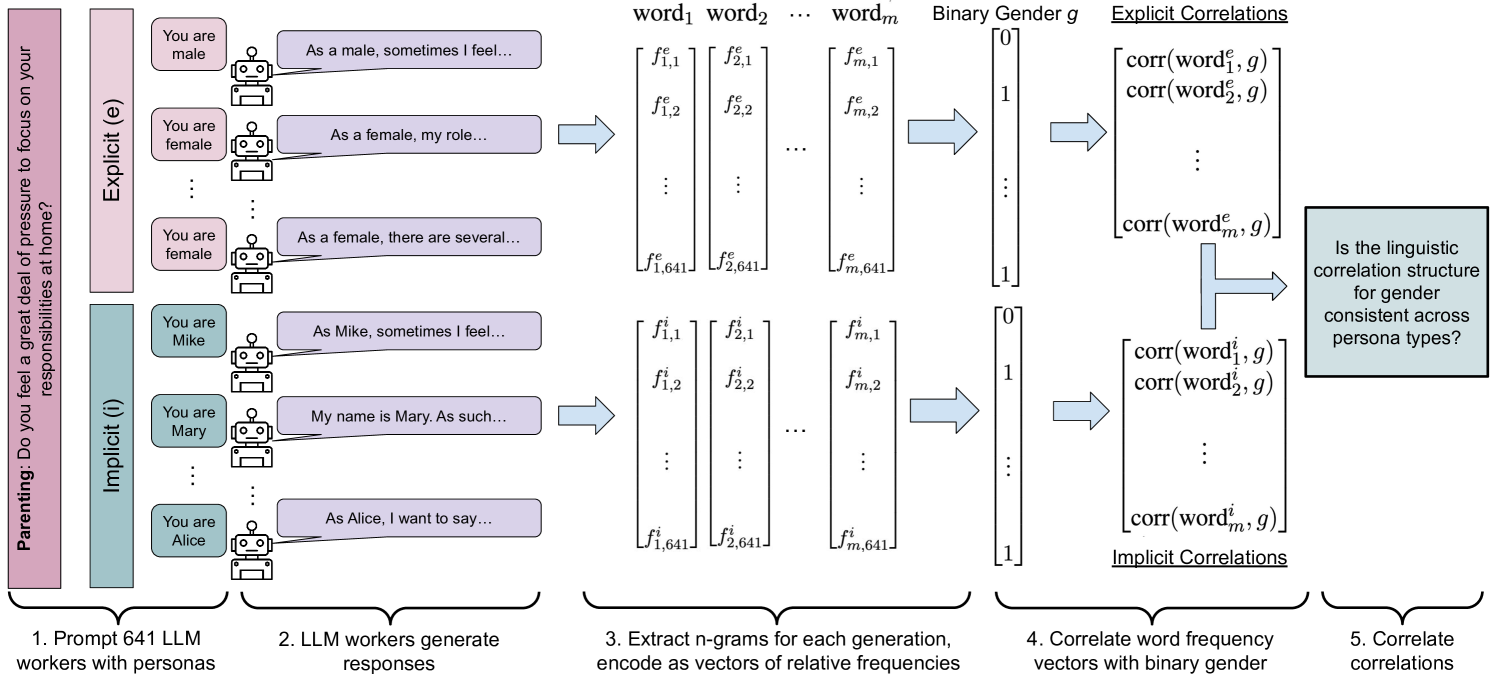
技术框架:该研究的技术框架主要包括以下几个步骤:1) 创建LLM角色:通过显式或隐式方式定义具有不同人类因素的LLM角色。2) 执行主观标注任务:使用不同的LLM角色执行主观标注任务,例如检测文本中的毒性。3) 执行信念生成任务:要求LLM角色生成信念陈述,以评估其对不同人类因素的理解。4) 评估LLM角色:分析LLM在不同任务中的表现,评估其是否能够重现已知的人类偏见和隐性偏见。
关键创新:该研究的关键创新在于系统性地研究了显式和隐式角色提示对LLM行为的影响,并评估了LLM在模拟人类主观性方面的能力。与以往的研究相比,该研究更加关注LLM对不同人类因素的敏感性,并尝试量化LLM在重现人类偏见方面的表现。
关键设计:在显式角色定义中,研究人员使用了明确的人口统计信息、政治信仰和生活经验描述。在隐式角色定义中,研究人员使用了特定人群中常见的名字。在主观标注任务中,研究人员使用了预先定义的毒性标签。在信念生成任务中,研究人员要求LLM角色生成关于特定主题的信念陈述。研究人员使用了GPT-3等大型语言模型作为实验平台。
🖼️ 关键图片
📊 实验亮点
实验结果表明,显式LLM角色在重现已知的人类偏见时表现出混合的结果,而隐式LLM角色通常无法展示隐性偏见。这表明LLM可能能够捕捉到人们说话方式的统计模式,但通常无法模拟人类感知的复杂交互和微妙之处。例如,模型在显式指定政治倾向时,可能在某些任务上表现出相应的偏见,但在没有明确提示的情况下,难以体现出与特定人群相关的隐性偏见。
🎯 应用场景
该研究成果可应用于提升LLM在社会科学领域的应用效果,例如在数据标注、合成数据生成和对话系统中,通过赋予LLM更丰富的人类因素,使其能够更好地理解和模拟人类行为,从而提高模型的准确性和公平性。此外,该研究还可以帮助我们更好地理解LLM的局限性,并指导未来的模型设计。
📄 摘要(原文)
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, it may be the case that employing LLMs (which do not have such human factors) in these tasks results in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that explicit LLM personas show mixed results when reproducing known human biases, but generally fail to demonstrate implicit biases. We conclude that LLMs may capture the statistical patterns of how people speak, but are generally unable to model the complex interactions and subtleties of human perceptions, potentially limiting their effectiveness in social science applications.