Exploring Spatial Representations in the Historical Lake District Texts with LLM-based Relation Extraction
作者: Erum Haris, Anthony G. Cohn, John G. Stell
分类: cs.CL, cs.AI
发布日期: 2024-06-20
💡 一句话要点
利用LLM关系抽取探索历史湖区文本中的空间表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 空间关系抽取 大型语言模型 历史文本分析 知识图谱 自然语言处理
📋 核心要点
- 现有方法难以从历史叙事文本中有效提取空间关系,限制了对历史地理环境的理解。
- 利用大型语言模型,从历史文本中抽取实体和位置之间的空间关系,构建知识图谱。
- 通过语义三元组和网络可视化,呈现湖区历史叙事的空间维度,加深理解。
📝 摘要(中文)
本研究旨在揭示历史叙事中复杂的空间关系,以英格兰湖区语料库为背景,利用生成式预训练Transformer模型从文本描述中提取空间关系。该方法应用大型语言模型全面理解历史叙事中固有的空间维度。研究结果以语义三元组的形式呈现,捕捉实体与位置之间细微的联系,并可视化为网络,提供空间叙事的图形化表示。本研究有助于更深入地理解英格兰湖区的空间结构,并为在不同的历史背景下发现空间关系提供了一种方法。
🔬 方法详解
问题定义:该论文旨在解决从历史文本中自动提取空间关系的问题。现有的方法可能依赖于人工标注或者规则匹配,效率低且难以处理复杂的语言表达。因此,如何利用自然语言处理技术,特别是大型语言模型,自动有效地从历史文本中提取空间关系是一个挑战。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的文本理解和生成能力,将空间关系抽取任务转化为一个文本生成任务。通过训练LLM识别文本中描述空间关系的模式,并生成相应的语义三元组,从而实现空间关系的自动提取。这种方法避免了人工标注的繁琐,并能够处理更复杂的语言表达。
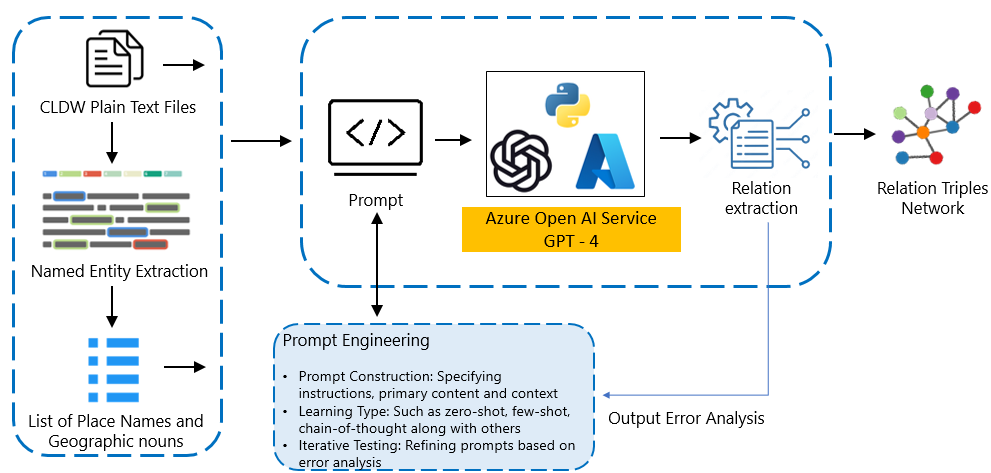
技术框架:该方法主要包含以下几个步骤:1) 数据准备:构建或选择包含空间信息的历史文本语料库,例如本研究中使用的英格兰湖区语料库。2) 模型选择与训练:选择合适的预训练LLM,并使用标注或无标注的数据进行微调,使其适应空间关系抽取的任务。3) 关系抽取:使用训练好的LLM从文本中抽取实体和位置,并识别它们之间的空间关系。4) 知识图谱构建与可视化:将抽取出的空间关系以语义三元组的形式存储,并构建知识图谱,最后进行可视化展示。
关键创新:该论文的关键创新在于利用LLM进行空间关系抽取,并将其应用于历史文本分析。与传统的基于规则或机器学习的方法相比,LLM能够更好地理解文本的语义信息,并抽取更准确的空间关系。此外,该方法还提供了一种将历史叙事转化为可视化知识图谱的有效途径。
关键设计:论文中关键的设计可能包括:1) LLM的选择:选择具有较强文本理解和生成能力的LLM,例如GPT系列模型。2) 训练数据的构建:如何构建高质量的训练数据,包括标注的空间关系三元组或利用自监督学习方法。3) 关系抽取策略:如何设计LLM的输入和输出格式,以及如何利用LLM生成空间关系三元组。4) 可视化方法:如何选择合适的可视化方法,清晰地展示空间关系网络。
🖼️ 关键图片

📊 实验亮点
该研究成功地将大型语言模型应用于历史文本的空间关系抽取,并构建了英格兰湖区历史叙事的空间知识图谱。通过可视化展示,能够更直观地理解历史文本中描述的空间关系。虽然论文没有提供具体的性能数据,但展示了LLM在处理复杂历史文本方面的潜力。
🎯 应用场景
该研究成果可应用于历史地理研究、文化遗产保护、旅游规划等领域。通过自动提取历史文本中的空间信息,可以更深入地了解历史地理环境的演变,为文化遗产的保护提供依据,并为旅游规划提供更丰富的历史文化信息。此外,该方法还可以推广到其他领域的文本分析,例如城市规划、环境监测等。
📄 摘要(原文)
Navigating historical narratives poses a challenge in unveiling the spatial intricacies of past landscapes. The proposed work addresses this challenge within the context of the English Lake District, employing the Corpus of the Lake District Writing. The method utilizes a generative pre-trained transformer model to extract spatial relations from the textual descriptions in the corpus. The study applies this large language model to understand the spatial dimensions inherent in historical narratives comprehensively. The outcomes are presented as semantic triples, capturing the nuanced connections between entities and locations, and visualized as a network, offering a graphical representation of the spatial narrative. The study contributes to a deeper comprehension of the English Lake District's spatial tapestry and provides an approach to uncovering spatial relations within diverse historical contexts.