Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
作者: Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
分类: cs.CL, cs.AI
发布日期: 2024-06-20 (更新: 2024-10-23)
备注: EMNLP2024 Findings
💡 一句话要点
提出基于知识图谱的规划数据,提升检索增强大语言模型在复杂问答中的规划能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识图谱 规划能力 检索增强 问答系统
📋 核心要点
- 小规模LLM在复杂问答中分解问题能力不足,依赖耗时且不精确的人工标注或知识蒸馏。
- 利用知识图谱(KG)生成规划数据,用于微调LLM,提升其规划能力和检索增强问答性能。
- 实验表明,使用KG规划数据微调的LLM在多个数据集上表现提升,验证了框架的有效性。
📝 摘要(中文)
本文致力于提升大语言模型(LLMs)在复杂问答(QA)场景中的性能。现有研究尝试结合逐步规划与外部检索来增强LLMs的性能,但对于较小的LLMs,分解复杂问题面临挑战,需要监督微调。先前的工作依赖于手动标注和从教师LLMs的知识蒸馏,这既耗时又不准确。本文提出了一种新颖的框架,通过使用从知识图谱(KGs)导出的规划数据来增强LLMs的规划能力。使用此数据微调的LLMs具有改进的规划能力,能够更好地处理涉及检索的复杂QA任务。在多个数据集(包括新提出的基准)上的评估突出了该框架的有效性以及KG衍生的规划数据的优势。
🔬 方法详解
问题定义:论文旨在解决小规模大语言模型(LLMs)在复杂问答(QA)场景中,由于缺乏有效的规划能力而导致性能不佳的问题。现有方法,如手动标注和知识蒸馏,存在耗时、成本高昂以及标注质量难以保证等痛点。这些方法难以充分挖掘和利用知识图谱(KG)中蕴含的丰富知识,从而限制了LLMs在复杂推理和检索增强问答任务中的表现。
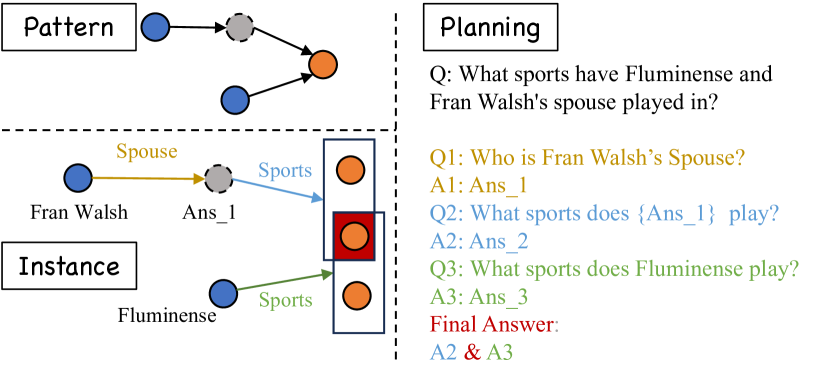
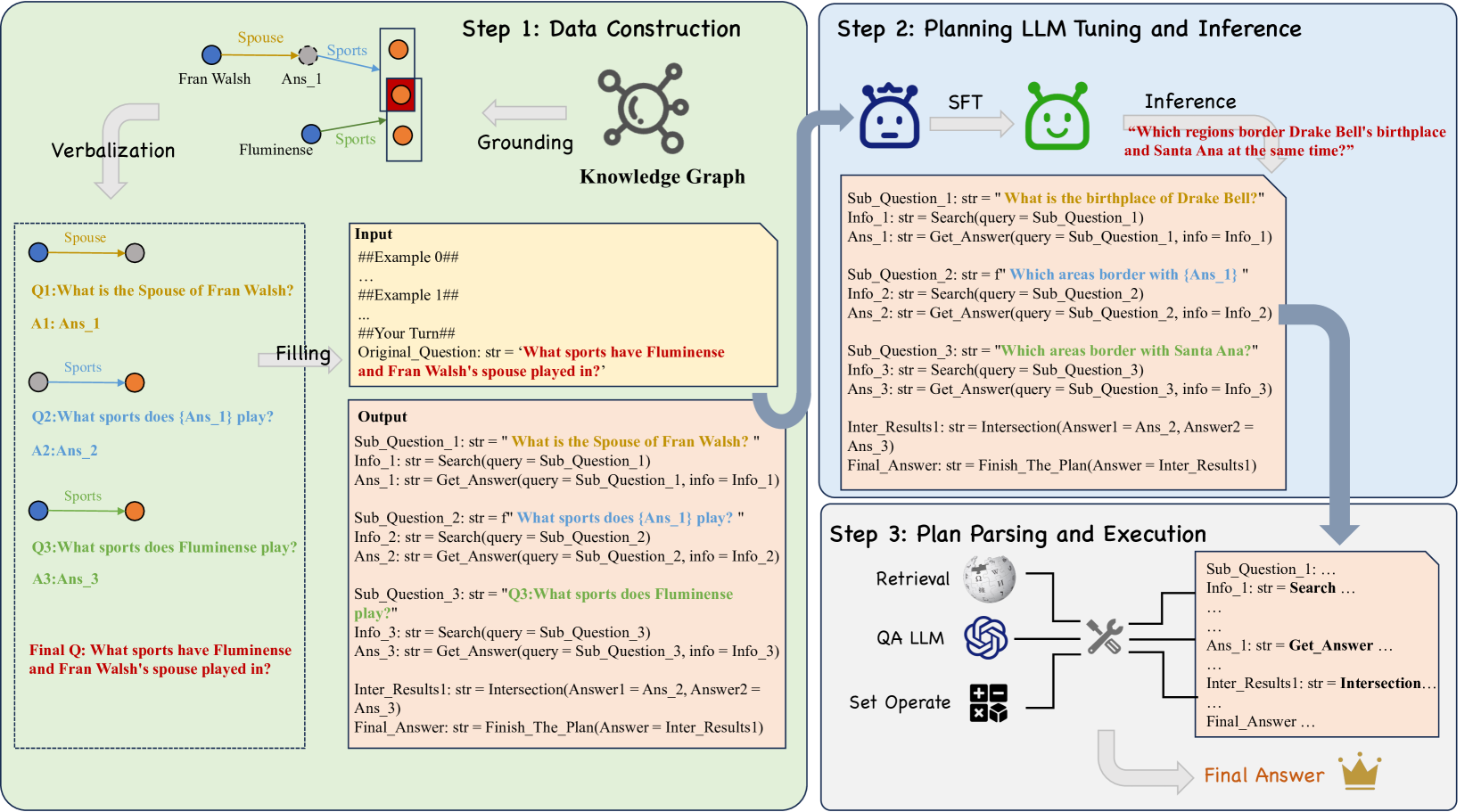
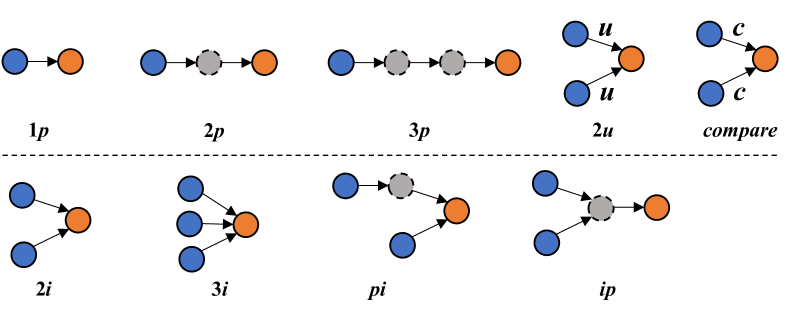
核心思路:论文的核心思路是利用知识图谱(KG)自动生成高质量的规划数据,并使用这些数据对LLMs进行微调,从而提升LLMs的规划能力。通过将KG中的结构化知识转化为LLMs可以学习的规划序列,使得LLMs能够更好地理解复杂问题的逻辑关系,并制定有效的检索和推理策略。这种方法避免了人工标注的成本和偏差,同时充分利用了KG的知识,为LLMs提供了更有效的学习信号。
技术框架:该框架主要包含以下几个阶段:1) 知识图谱选择与处理:选择合适的知识图谱,并进行必要的预处理,例如实体对齐、关系抽取等。2) 规划数据生成:基于知识图谱中的实体和关系,自动生成规划序列。这些序列描述了解决复杂问题所需的步骤和逻辑关系。3) LLM微调:使用生成的规划数据对LLM进行微调,使其学习如何根据问题制定规划。4) 检索增强问答:在问答过程中,LLM首先根据问题生成规划,然后根据规划进行检索,最后结合检索结果生成答案。
关键创新:该论文最重要的技术创新点在于提出了利用知识图谱自动生成规划数据的方法。与传统的手动标注或知识蒸馏方法相比,该方法能够更高效、更准确地生成大规模的规划数据,从而显著提升LLMs的规划能力。此外,该方法还能够充分利用知识图谱中的结构化知识,为LLMs提供更丰富的学习信号。
关键设计:在规划数据生成方面,论文可能采用了基于图遍历或路径搜索的算法,从知识图谱中提取出与问题相关的实体和关系,并将它们组织成规划序列。在LLM微调方面,可能采用了序列到序列(Seq2Seq)的学习框架,将问题作为输入,将规划序列作为输出。损失函数可能包括交叉熵损失和规划序列的相似度损失,以确保LLM能够准确地生成规划序列。
🖼️ 关键图片
📊 实验亮点
论文提出的框架在多个数据集上进行了评估,包括一个新提出的基准。实验结果表明,使用KG规划数据微调的LLM在规划能力和问答准确率方面均取得了显著提升。具体性能数据未知,但摘要强调了该框架的有效性和KG衍生规划数据的优势,暗示了相比于基线模型有明显的性能提升。
🎯 应用场景
该研究成果可广泛应用于智能问答系统、搜索引擎、推荐系统等领域。通过提升LLMs的规划能力,可以使其更好地理解用户意图,从而提供更准确、更个性化的服务。例如,在医疗问答领域,可以利用该技术帮助LLMs更好地理解复杂的医学问题,并提供更专业的诊断建议。在金融领域,可以帮助LLMs更好地分析市场数据,并提供更明智的投资建议。未来,该技术有望成为构建更智能、更可靠的人工智能系统的关键组成部分。
📄 摘要(原文)
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.