Definition generation for lexical semantic change detection
作者: Mariia Fedorova, Andrey Kutuzov, Yves Scherrer
分类: cs.CL
发布日期: 2024-06-20 (更新: 2024-07-31)
备注: Findings of ACL 2024
💡 一句话要点
提出基于LLM生成定义的词义表示方法,用于词汇语义随时间变化检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 词汇语义变化检测 大型语言模型 词义表示 自然语言处理 可解释性
📋 核心要点
- 现有历时词汇语义变化检测方法缺乏解释性,难以理解语义变化的具体原因。
- 利用大型语言模型生成词定义作为词义表示,通过比较不同时间段词义分布来检测语义变化。
- 实验表明,该方法在多个数据集上表现与现有方法相当或更优,并具备良好的可解释性。
📝 摘要(中文)
本文提出了一种利用大型语言模型生成的上下文词定义作为语义表示的方法,用于历时词汇语义变化检测(LSCD)任务。简而言之,生成的定义被用作“词义”,并通过比较目标词在两个时间段内的词义分布来检索其变化得分。在五个数据集和三种语言的实验结果表明,生成的定义足够具体和通用,能够传达足够的信号,从而按语义随时间变化的程度对词集进行排序。我们的方法与先前的非监督的基于词义的LSCD方法相当或优于它们。同时,它保留了解释性,并允许检查特定变化背后的原因,即离散的定义即词义。这是朝着可解释的语义变化建模迈出的又一步。
🔬 方法详解
问题定义:论文旨在解决历时词汇语义变化检测(LSCD)问题。现有方法,特别是基于词嵌入的方法,虽然能够检测到语义变化,但缺乏解释性,难以理解词义变化的具体内容。此外,传统的基于词义的方法依赖于人工标注的词义,成本高昂且难以扩展到大规模语料库。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成上下文相关的词定义,并将这些定义作为词义的表示。通过比较目标词在不同时间段内生成的词定义分布,可以量化该词的语义变化程度。这种方法的优势在于,生成的词定义既能捕捉到词义的细微差别,又具有良好的可解释性,可以直接观察到词义的变化。
技术框架:该方法主要包含以下几个阶段: 1. 数据准备:收集目标词在不同时间段的文本语料。 2. 定义生成:使用大型语言模型(如BERT、GPT等)为目标词在每个时间段生成多个上下文相关的定义。 3. 词义表示:将每个生成的定义视为一个独立的词义。 4. 分布比较:计算目标词在不同时间段的词义分布,并使用某种距离度量(如余弦相似度、KL散度等)来量化分布之间的差异。 5. 变化得分:将分布差异作为目标词的语义变化得分。
关键创新:该方法最重要的创新点在于使用LLM生成的词定义作为词义表示。与传统的基于词嵌入的方法相比,这种方法具有更好的可解释性。与传统的基于词义的方法相比,这种方法避免了人工标注的成本,并且可以利用LLM的强大生成能力来捕捉到更丰富的词义信息。
关键设计:论文中关键的设计包括: 1. LLM的选择:选择合适的LLM对于生成高质量的词定义至关重要。论文可能尝试了不同的LLM,并比较了它们的效果。 2. 定义生成策略:如何利用LLM生成词定义?例如,可以使用prompt engineering技术来引导LLM生成特定类型的定义。 3. 距离度量:选择合适的距离度量来比较词义分布。论文可能尝试了不同的距离度量,并比较了它们的效果。 4. 超参数调优:调整LLM的超参数,以获得最佳的定义生成效果。
🖼️ 关键图片
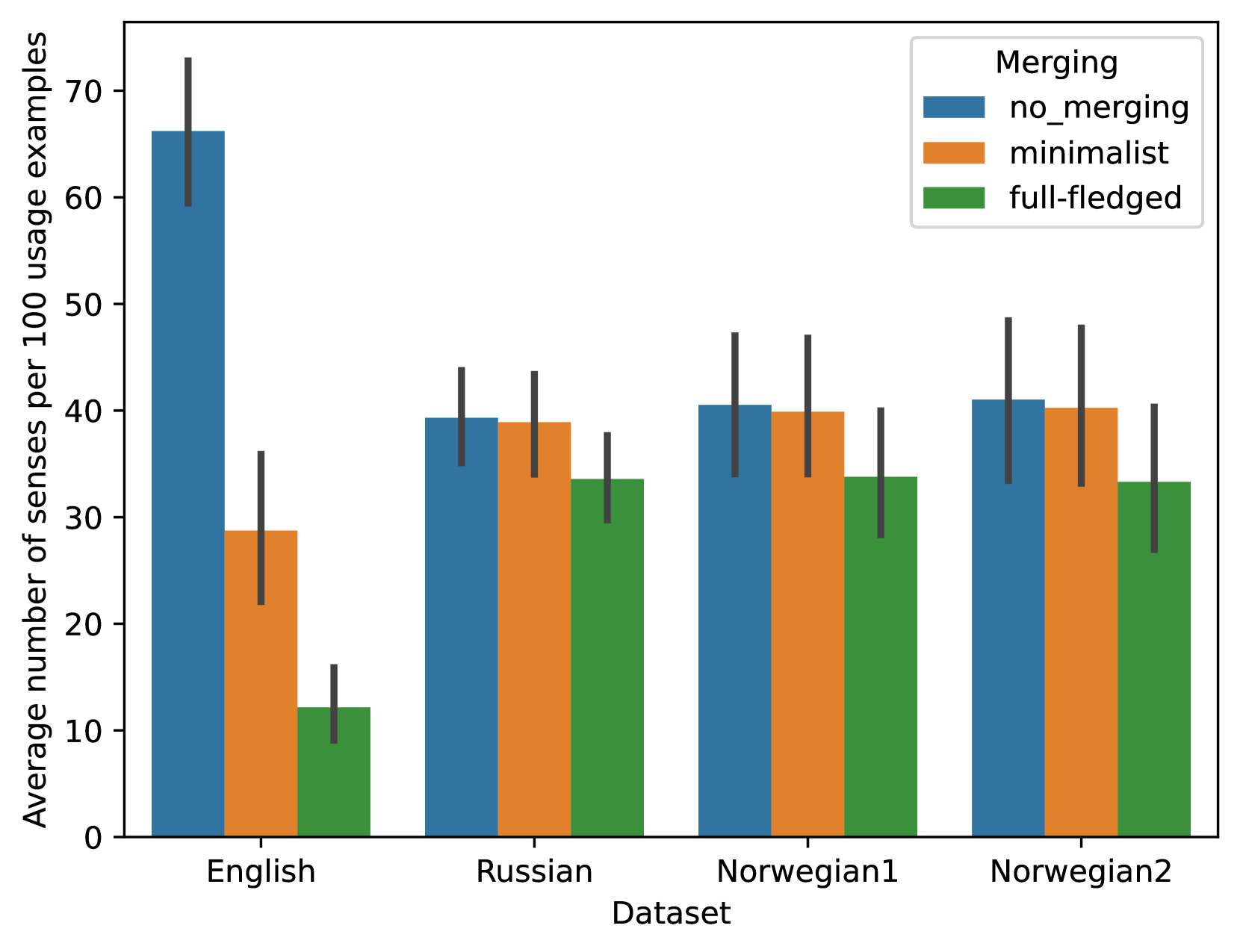
📊 实验亮点
实验结果表明,该方法在五个数据集和三种语言上取得了与现有非监督方法相当或更优的性能。更重要的是,该方法提供了良好的可解释性,允许用户直接观察到词义的变化,例如某个词从表示“A”演变为表示“B”。
🎯 应用场景
该研究成果可应用于历史语言学研究,帮助语言学家追踪词汇语义的演变过程。在自然语言处理领域,该方法可以用于改进机器翻译、信息检索等任务,提高模型对词义歧义的理解能力。此外,该方法还可用于分析社交媒体文本,了解社会观念和文化价值观的变迁。
📄 摘要(原文)
We use contextualized word definitions generated by large language models as semantic representations in the task of diachronic lexical semantic change detection (LSCD). In short, generated definitions are used as `senses', and the change score of a target word is retrieved by comparing their distributions in two time periods under comparison. On the material of five datasets and three languages, we show that generated definitions are indeed specific and general enough to convey a signal sufficient to rank sets of words by the degree of their semantic change over time. Our approach is on par with or outperforms prior non-supervised sense-based LSCD methods. At the same time, it preserves interpretability and allows to inspect the reasons behind a specific shift in terms of discrete definitions-as-senses. This is another step in the direction of explainable semantic change modeling.