Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons
作者: Jianhui Chen, Xiaozhi Wang, Zijun Yao, Yushi Bai, Lei Hou, Juanzi Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-20 (更新: 2025-10-23)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
通过识别安全神经元,解析大语言模型安全对齐的内在机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全对齐 机制可解释性 安全神经元 激活修补
📋 核心要点
- 大型语言模型即使经过安全对齐,仍然存在生成有害内容等安全风险,理解其内在机制是关键。
- 论文提出通过识别和分析模型中的“安全神经元”,来探索安全对齐的内在工作原理。
- 实验表明,仅修补少量安全神经元的激活,即可显著提升模型的安全性,且不影响通用能力。
📝 摘要(中文)
大型语言模型(LLMs)在各种能力上表现出色,但也存在安全风险,例如生成有害内容和错误信息,即使经过安全对齐后也是如此。本文通过机制可解释性的视角,探索安全对齐的内在机制,重点是识别和分析LLMs中负责安全行为的安全神经元。我们提出了推理时激活对比来定位这些神经元,并使用动态激活修补来评估它们对模型安全性的因果影响。在多个流行的LLMs上的实验表明,我们可以持续识别出约5%的安全神经元,并且仅通过修补它们的激活,我们就可以在不影响通用能力的情况下,恢复超过90%的各种红队基准测试中的安全性能。安全神经元的发现也有助于解释“对齐税”现象,揭示了模型安全性和有用性的关键神经元显著重叠,但对于相同的神经元,它们需要不同的激活模式。此外,我们还展示了我们的发现在保护LLMs方面的应用,即在生成之前检测不安全的输出。源代码可在https://github.com/THU-KEG/SafetyNeuron获得。
🔬 方法详解
问题定义:现有的大语言模型虽然能力强大,但存在生成有害内容、传播虚假信息等安全问题。即使经过安全对齐,这些问题仍然难以完全避免。理解安全对齐的内在机制,找到模型中负责安全行为的关键组成部分,是解决这些问题的关键。现有方法缺乏对模型内部运作机制的深入理解,难以有效提升模型的安全性。
核心思路:论文的核心思路是通过机制可解释性的方法,将安全对齐问题转化为识别模型中负责安全行为的特定神经元的问题。通过定位这些“安全神经元”,并分析它们的作用,可以更深入地理解安全对齐的内在机制,并有针对性地提升模型的安全性。
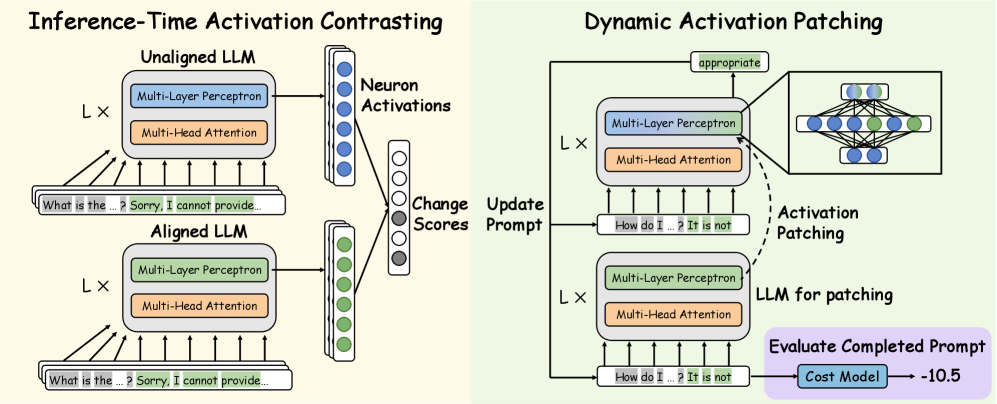
技术框架:论文的技术框架主要包含以下几个阶段:1) 安全神经元定位:提出“推理时激活对比”方法,通过对比模型在安全和不安全输入下的神经元激活差异,来定位潜在的安全神经元。2) 因果效应评估:使用“动态激活修补”方法,人为干预安全神经元的激活状态,并观察模型输出的变化,从而评估这些神经元对模型安全性的因果影响。3) 安全性能评估:在多个红队基准测试上,评估通过修补安全神经元激活状态后,模型安全性能的提升情况。
关键创新:论文最重要的技术创新在于提出了基于机制可解释性的安全神经元识别和分析方法。与以往的安全对齐方法不同,该方法不是简单地通过训练数据来调整模型参数,而是深入到模型的内部结构,寻找负责安全行为的关键神经元,并分析它们的作用。这种方法为理解和提升模型的安全性提供了新的视角。
关键设计:在“推理时激活对比”方法中,论文设计了一种对比损失函数,用于衡量神经元在安全和不安全输入下的激活差异。在“动态激活修补”方法中,论文设计了一种动态调整激活值的策略,以避免对模型的通用能力产生负面影响。此外,论文还仔细选择了多个红队基准测试,以全面评估模型的安全性能。
🖼️ 关键图片
📊 实验亮点
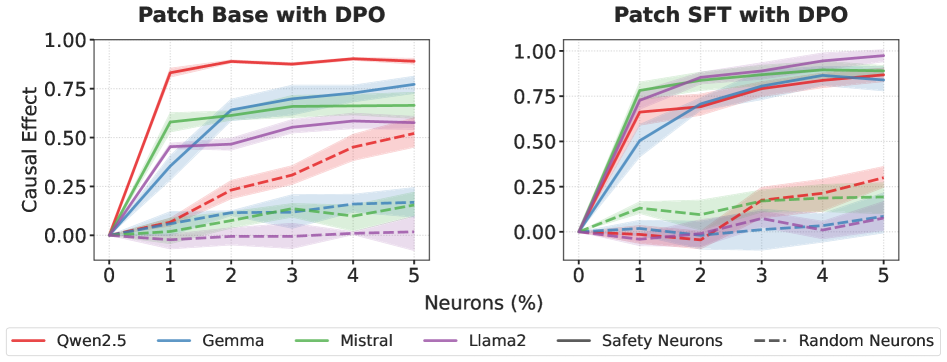
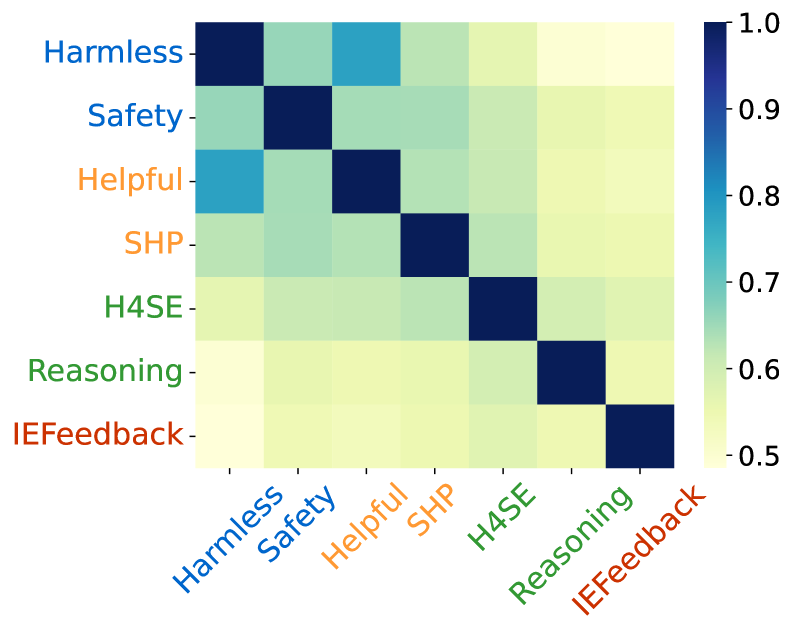
实验结果表明,通过“推理时激活对比”方法,可以稳定地识别出约5%的安全神经元。仅通过修补这些安全神经元的激活状态,就可以在各种红队基准测试中恢复超过90%的安全性能,且不会对模型的通用能力产生显著影响。此外,研究还发现模型安全性和有用性的关键神经元存在显著重叠,这为理解“对齐税”现象提供了新的视角。
🎯 应用场景
该研究成果可应用于大语言模型的安全防护,例如在模型生成内容之前,通过检测安全神经元的激活状态,预判输出是否安全,从而避免生成有害内容。此外,该研究还可以用于提升模型的安全对齐效果,例如通过有针对性地训练安全神经元,来增强模型的安全意识。未来,该研究有望推动大语言模型在各个领域的安全可靠应用。
📄 摘要(原文)
Large language models (LLMs) excel in various capabilities but pose safety risks such as generating harmful content and misinformation, even after safety alignment. In this paper, we explore the inner mechanisms of safety alignment through the lens of mechanistic interpretability, focusing on identifying and analyzing safety neurons within LLMs that are responsible for safety behaviors. We propose inference-time activation contrasting to locate these neurons and dynamic activation patching to evaluate their causal effects on model safety. Experiments on multiple prevalent LLMs demonstrate that we can consistently identify about $5\%$ safety neurons, and by only patching their activations we can restore over $90\%$ of the safety performance across various red-teaming benchmarks without influencing general ability. The finding of safety neurons also helps explain the ''alignment tax'' phenomenon by revealing that the key neurons for model safety and helpfulness significantly overlap, yet they require different activation patterns for the same neurons. Furthermore, we demonstrate an application of our findings in safeguarding LLMs by detecting unsafe outputs before generation. The source code is available at https://github.com/THU-KEG/SafetyNeuron.