Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
作者: Ziche Liu, Rui Ke, Yajiao Liu, Feng Jiang, Haizhou Li
分类: cs.CL
发布日期: 2024-06-20 (更新: 2025-02-24)
备注: Accepted by the NAACL 2025 main conference
💡 一句话要点
提出LLM微调数据选择三阶段框架,并统一评估标准,揭示方法优劣与未来挑战。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 数据选择 特征提取 评估指标
📋 核心要点
- 现有LLM微调数据选择研究缺乏统一框架,实验设置差异大,难以系统比较。
- 论文提出包含特征提取、标准设计和选择器评估的三阶段框架,系统地分类和评估现有方法。
- 论文提出统一的评估方法,结合效率和可行性指标,发现质量测量方法效率高但可行性差。
📝 摘要(中文)
针对大型语言模型(LLM)微调的数据选择,旨在从现有数据集中选择高质量子集,使训练后的模型优于在完整数据集上训练的基线模型。然而,现有研究缺乏清晰、统一的框架,且实验设置的可变性使得系统性比较复杂。虽然现有的综述全面概述了数据选择的阶段和方法,但它们往往忽略了对微调阶段的深入探索。本文对LLM微调的最新数据选择技术进行了重点回顾,分析了十余项关键研究。我们引入了一个新的三阶段方案——包括特征提取、标准设计和选择器评估——以系统地分类和评估这些方法。此外,我们提出了一种统一的比较方法,该方法结合了基于比率的效率和基于排序的可行性指标,以解决实验中的不一致性。我们的研究结果表明,强调更有针对性的质量测量的方法实现了更高的效率,但以牺牲可行性为代价。最后,我们讨论了微调数据选择的趋势,并强调了四个关键挑战,为未来的研究提供了潜在的方向。
🔬 方法详解
问题定义:论文旨在解决LLM微调过程中,如何从海量数据中选择最具价值的数据子集,以提升模型性能并降低训练成本的问题。现有方法缺乏统一的评估标准,难以进行有效比较,且对微调阶段的关注不足。
核心思路:论文的核心思路是将数据选择过程分解为三个阶段:特征提取、标准设计和选择器评估。通过对每个阶段进行深入分析,可以更好地理解不同数据选择方法的优缺点,并为未来的研究提供指导。此外,论文还提出了统一的评估指标,以便在不同实验设置下进行公平比较。
技术框架:论文提出的三阶段框架如下: 1. 特征提取:从数据集中提取用于评估数据质量的特征,例如困惑度、信息熵等。 2. 标准设计:基于提取的特征,设计用于衡量数据重要性的标准,例如选择损失最大的样本。 3. 选择器评估:使用设计的标准,从数据集中选择子集,并评估在LLM微调后的性能。
关键创新:论文的关键创新在于提出了一个系统性的三阶段框架,用于分析和比较不同的数据选择方法。该框架能够帮助研究人员更好地理解各种方法的内在机制,并为未来的研究提供指导。此外,论文提出的统一评估指标也解决了现有研究中缺乏可比性的问题。
关键设计:论文的关键设计包括: 1. 特征提取:论文分析了多种常用的特征提取方法,例如困惑度、信息熵、梯度范数等。 2. 标准设计:论文讨论了多种常用的标准设计方法,例如基于损失的选择、基于梯度范数的选择、基于信息熵的选择等。 3. 选择器评估:论文提出了基于比率的效率和基于排序的可行性指标,用于评估不同数据选择方法的性能。
🖼️ 关键图片
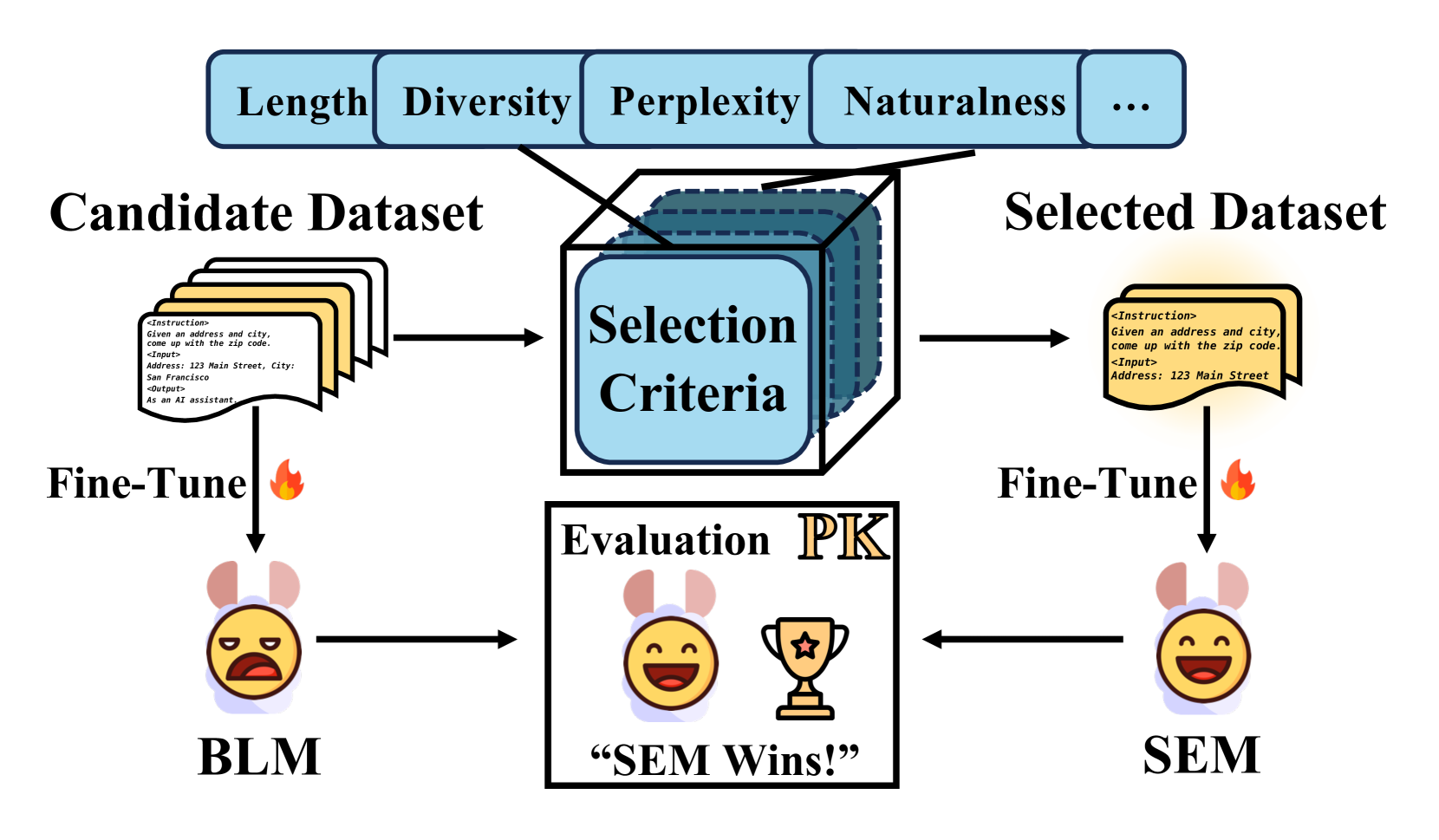

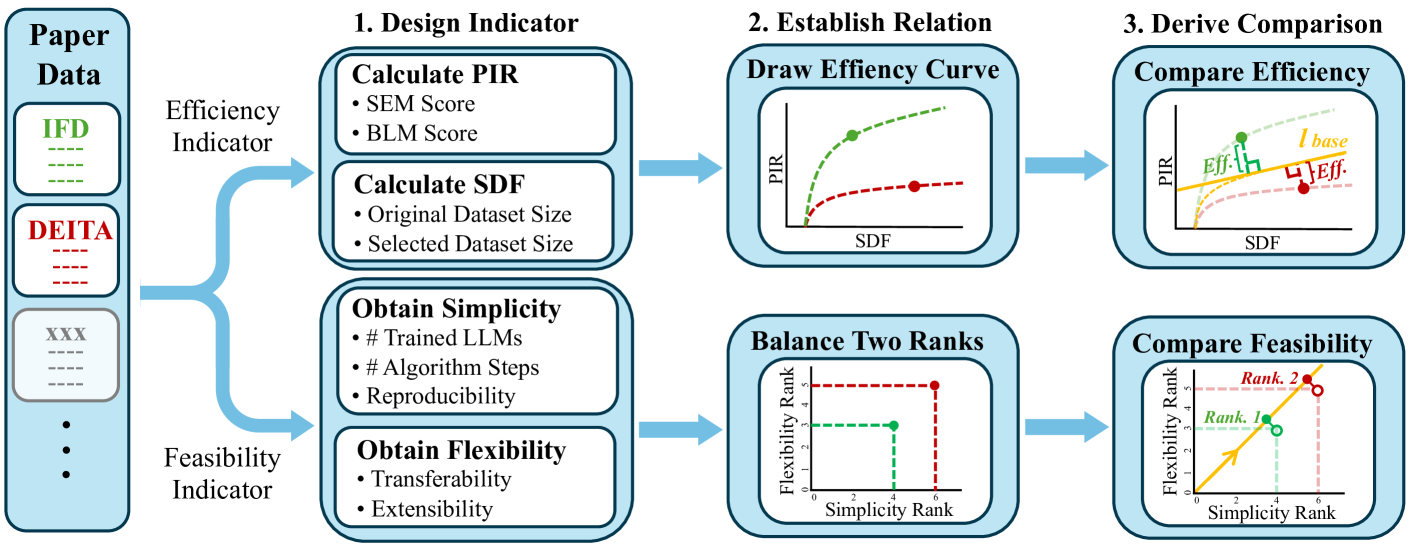
📊 实验亮点
论文通过对十余项关键研究的分析,揭示了不同数据选择方法的优缺点。研究结果表明,强调更有针对性的质量测量的方法实现了更高的效率,但以牺牲可行性为代价。此外,论文提出的统一评估指标,能够更公平地比较不同方法在不同实验设置下的性能。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型进行微调的场景,例如自然语言处理、机器翻译、文本生成等。通过选择高质量的数据子集进行微调,可以显著提升模型性能,降低训练成本,并加速模型的部署和应用。此外,该研究提出的框架和评估指标,可以为未来的数据选择研究提供指导。
📄 摘要(原文)
Data selection for fine-tuning large language models (LLMs) aims to choose a high-quality subset from existing datasets, allowing the trained model to outperform baselines trained on the full dataset. However, the expanding body of research lacks a clear, unified framework, and the variability in experimental settings complicates systematic comparisons. While existing surveys comprehensively overview the stages and methods of data selection, they often overlook an in-depth exploration of the fine-tuning phase. In this paper, we conduct a focused review of recent data selection techniques for fine-tuning LLMs, analyzing a dozen key studies. We introduce a novel three-stage scheme - comprising feature extraction, criteria design, and selector evaluation - to systematically categorize and evaluate these methods. Additionally, we propose a unified comparison approach that incorporates ratio-based efficiency and ranking-based feasibility metrics to address inconsistencies across experiments. Our findings reveal that methods emphasizing more targeted quality measurement achieve higher efficiency but at the cost of feasibility. Finally, we discuss trends and highlight four key challenges in fine-tuning data selection, offering potential directions for future research.