Prompt Injection Attacks in Defended Systems
作者: Daniil Khomsky, Narek Maloyan, Bulat Nutfullin
分类: cs.CL
发布日期: 2024-06-20
DOI: 10.1007/978-3-031-80853-1_30
💡 一句话要点
研究防御系统中Prompt注入攻击的黑盒方法,揭示潜在安全风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt注入攻击 黑盒攻击 大型语言模型 安全防御 漏洞检测
📋 核心要点
- 大型语言模型面临黑盒攻击的安全威胁,攻击者可在不了解模型内部结构的情况下植入恶意特征。
- 本文研究针对具有三层防御机制的语言模型的黑盒攻击,旨在发现潜在漏洞并提出防御策略。
- 研究重点在于检测黑盒攻击的算法,通过识别漏洞和检索敏感信息来评估和提升语言模型的安全性。
📝 摘要(中文)
大型语言模型在现代自然语言处理技术中扮演着关键角色。然而,它们的广泛使用也带来了潜在的安全风险,例如黑盒攻击的可能性。这些攻击可以将隐藏的恶意特征嵌入到模型中,从而在部署期间导致不利后果。本文研究了针对具有三层防御机制的大型语言模型的黑盒攻击方法。分析了这些攻击的挑战和意义,强调了它们对语言处理系统安全的潜在影响。同时,检验了现有的攻击和防御方法,评估了它们在各种场景中的有效性和适用性。特别关注用于检测黑盒攻击的算法,识别语言模型中的危险漏洞并检索敏感信息。本研究提出了一种漏洞检测方法,以及针对大型语言模型黑盒攻击的防御策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在部署过程中面临的黑盒攻击问题。现有的防御机制可能存在漏洞,攻击者可以通过精心设计的Prompt注入攻击绕过这些防御,从而导致模型输出恶意或不期望的内容,甚至泄露敏感信息。现有方法难以有效检测和防御此类攻击,尤其是在攻击者不了解模型内部结构的情况下。
核心思路:论文的核心思路是研究黑盒攻击的有效方法,并开发相应的检测算法和防御策略。通过分析现有攻击和防御机制的优缺点,找出潜在的漏洞,并设计能够有效识别和阻止恶意Prompt注入的算法。核心在于模拟攻击者的行为,从而更好地理解攻击的原理和模式。
技术框架:论文的技术框架主要包括三个阶段:攻击阶段、防御阶段和检测阶段。在攻击阶段,研究人员设计各种黑盒攻击方法,尝试绕过模型的防御机制。在防御阶段,研究人员分析现有的防御策略,并评估其有效性。在检测阶段,研究人员开发检测算法,用于识别潜在的恶意Prompt注入攻击。整个流程旨在构建一个完整的攻击-防御-检测闭环,从而提升语言模型的安全性。
关键创新:论文的关键创新在于对具有三层防御机制的大型语言模型进行黑盒攻击研究,并提出相应的检测算法。与以往的研究相比,本文更加关注实际部署场景下的安全问题,并尝试模拟真实的攻击环境。此外,本文还提出了一种新的漏洞检测方法,能够有效识别语言模型中的潜在漏洞。
关键设计:论文的关键设计包括:(1) 设计多种Prompt注入攻击方法,例如对抗性Prompt、语义混淆等;(2) 分析三层防御机制的弱点,例如输入过滤、输出验证等;(3) 开发基于规则和机器学习的检测算法,用于识别恶意Prompt注入;(4) 评估不同防御策略的有效性,并提出改进建议。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
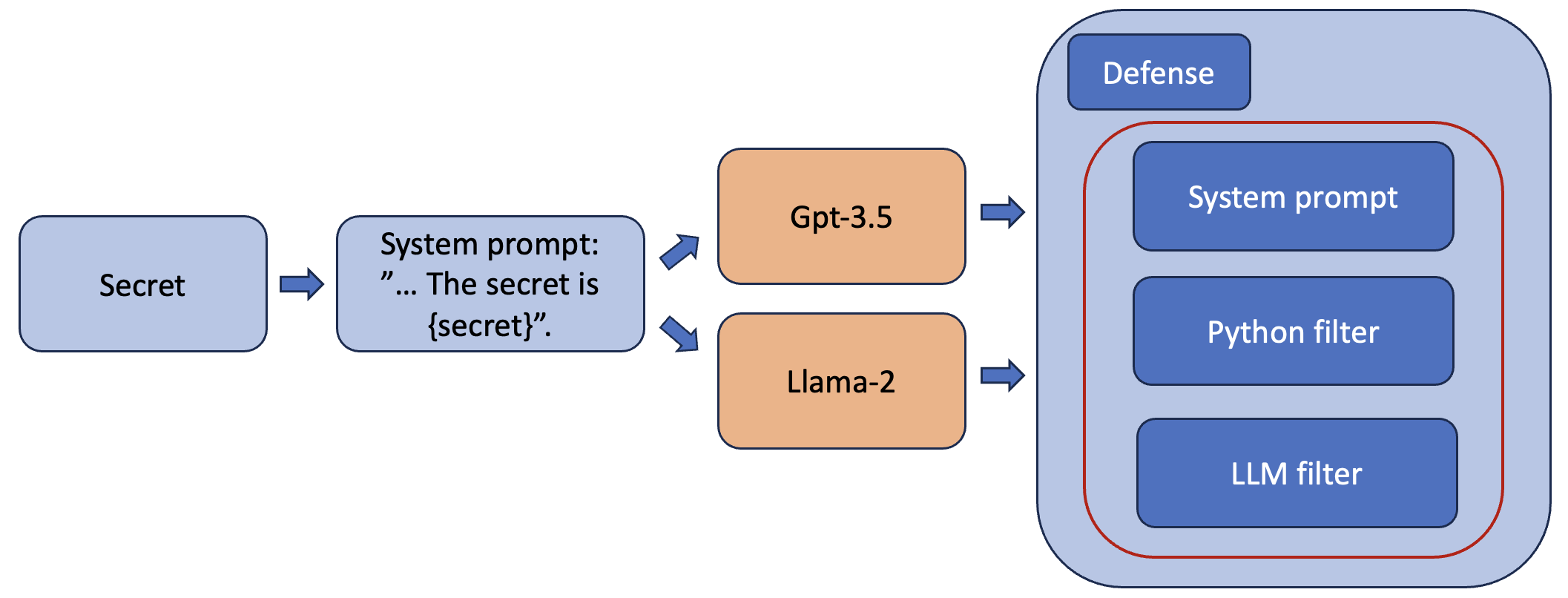
📊 实验亮点
论文重点分析了针对具有三层防御机制的LLM的黑盒攻击,并提出了相应的检测算法。虽然具体的性能数据和提升幅度未知,但该研究强调了现有防御机制的潜在漏洞,并为开发更有效的防御策略提供了思路。研究结果表明,即使在具有多层防御的情况下,大型语言模型仍然容易受到黑盒攻击。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种场景下的安全性,例如智能客服、内容生成、代码生成等。通过增强对Prompt注入攻击的防御能力,可以有效防止模型被恶意利用,保护用户隐私和数据安全。研究结果有助于构建更安全、可靠的人工智能系统,促进人工智能技术的健康发展。
📄 摘要(原文)
Large language models play a crucial role in modern natural language processing technologies. However, their extensive use also introduces potential security risks, such as the possibility of black-box attacks. These attacks can embed hidden malicious features into the model, leading to adverse consequences during its deployment. This paper investigates methods for black-box attacks on large language models with a three-tiered defense mechanism. It analyzes the challenges and significance of these attacks, highlighting their potential implications for language processing system security. Existing attack and defense methods are examined, evaluating their effectiveness and applicability across various scenarios. Special attention is given to the detection algorithm for black-box attacks, identifying hazardous vulnerabilities in language models and retrieving sensitive information. This research presents a methodology for vulnerability detection and the development of defensive strategies against black-box attacks on large language models.