GenderAlign: An Alignment Dataset for Mitigating Gender Bias in Large Language Models
作者: Tao Zhang, Ziqian Zeng, Yuxiang Xiao, Huiping Zhuang, Cen Chen, James Foulds, Shimei Pan
分类: cs.CL, cs.AI
发布日期: 2024-06-20 (更新: 2024-12-16)
💡 一句话要点
提出GenderAlign数据集,用于缓解大型语言模型中的性别偏见。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 性别偏见 对齐 数据集 微调
📋 核心要点
- 大型语言模型存在性别偏见,但缺乏专门针对此问题的公开对齐数据集。
- 构建GenderAlign数据集,包含高质量的“选择”和“拒绝”回应,降低性别偏见。
- 实验证明,使用GenderAlign数据集可以有效减少大型语言模型中的性别偏见。
📝 摘要(中文)
大型语言模型(LLMs)容易生成带有性别偏见的内容,引发了重要的伦理问题。对齐(Alignment),即微调LLMs以更好地符合期望行为的过程,被认为是缓解性别偏见的有效方法。虽然专有LLMs在缓解性别偏见方面取得了显著进展,但它们的对齐数据集并未公开。常用的公开对齐数据集HH-RLHF在一定程度上仍然存在性别偏见。目前缺乏专门用于解决性别偏见的公开对齐数据集。因此,我们开发了一个名为GenderAlign的新数据集,旨在缓解LLMs中一系列全面的性别偏见。该数据集包含8k个单轮对话,每个对话都配有一个“选择”和一个“拒绝”的回应。与“拒绝”的回应相比,“选择”的回应表现出较低的性别偏见和更高的质量。此外,我们将GenderAlign中“拒绝”回应中的性别偏见分为4个主要类别。实验结果表明GenderAlign在减少LLMs中的性别偏见方面是有效的。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中普遍存在的性别偏见问题。现有公开的对齐数据集(如HH-RLHF)仍然存在此类偏见,而专有模型使用的对齐数据集通常不公开,导致研究人员难以有效缓解LLM中的性别偏见。因此,需要一个专门设计用于解决性别偏见的公开数据集。
核心思路:论文的核心思路是构建一个高质量的对齐数据集,其中包含“选择”和“拒绝”两种回应,通过对比学习的方式,引导模型学习生成更少性别偏见的内容。“选择”的回应代表了期望的行为,即更少的性别偏见和更高的质量,而“拒绝”的回应则包含不同类型的性别偏见。
技术框架:GenderAlign数据集的构建流程主要包括以下几个阶段:1) 数据收集:收集包含潜在性别偏见的对话数据。2) 回应生成:针对每个对话,生成一个“选择”回应和一个“拒绝”回应。3) 偏见分类:将“拒绝”回应中的性别偏见分为4个主要类别。4) 人工标注:对“选择”和“拒绝”回应进行人工标注,确保“选择”回应的质量和较低的性别偏见。5) 数据集发布:公开GenderAlign数据集,供研究人员使用。
关键创新:该论文的关键创新在于构建了一个专门针对缓解大型语言模型性别偏见的对齐数据集。与现有的通用对齐数据集相比,GenderAlign更加关注性别偏见问题,并对偏见类型进行了细致的分类。此外,该数据集的公开性也促进了相关研究的进展。
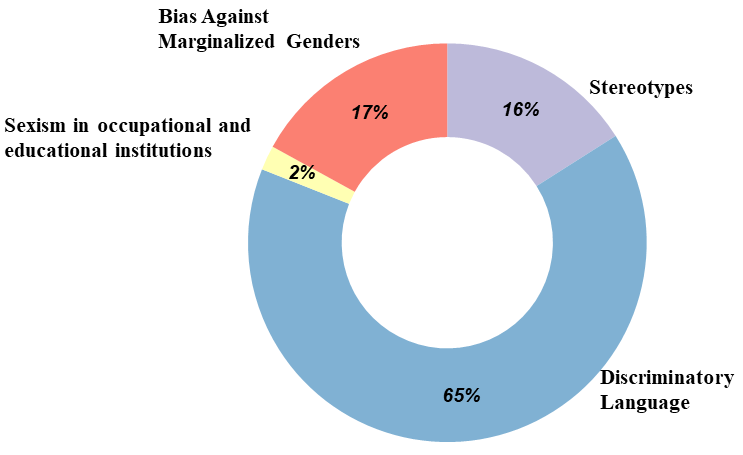
关键设计:GenderAlign数据集包含8k个单轮对话,每个对话都配有一个“选择”和一个“拒绝”的回应。数据集中的性别偏见被分为4个主要类别(具体类别未知)。标注过程需要保证“选择”回应在质量上高于“拒绝”回应,并且性别偏见程度更低。具体的损失函数和网络结构选择取决于下游模型的训练方式,但通常会采用对比学习或排序学习的方法,鼓励模型学习区分“选择”和“拒绝”回应。
🖼️ 关键图片


📊 实验亮点
GenderAlign数据集包含8k个单轮对话,并对“拒绝”回应中的性别偏见进行了分类。实验结果表明,使用GenderAlign数据集可以有效减少大型语言模型中的性别偏见。具体性能数据和对比基线未在摘要中明确给出,但强调了该数据集在缓解性别偏见方面的有效性。
🎯 应用场景
GenderAlign数据集可用于微调大型语言模型,以减少其在文本生成中产生的性别偏见。这有助于提高LLM在各种应用场景中的公平性和伦理性,例如聊天机器人、内容创作、教育辅助等。通过使用该数据集,可以构建更加公正和负责任的人工智能系统,避免对特定性别群体造成歧视或偏见。
📄 摘要(原文)
Large Language Models (LLMs) are prone to generating content that exhibits gender biases, raising significant ethical concerns. Alignment, the process of fine-tuning LLMs to better align with desired behaviors, is recognized as an effective approach to mitigate gender biases. Although proprietary LLMs have made significant strides in mitigating gender bias, their alignment datasets are not publicly available. The commonly used and publicly available alignment dataset, HH-RLHF, still exhibits gender bias to some extent. There is a lack of publicly available alignment datasets specifically designed to address gender bias. Hence, we developed a new dataset named GenderAlign, aiming at mitigating a comprehensive set of gender biases in LLMs. This dataset comprises 8k single-turn dialogues, each paired with a "chosen" and a "rejected" response. Compared to the "rejected" responses, the "chosen" responses demonstrate lower levels of gender bias and higher quality. Furthermore, we categorized the gender biases in the "rejected" responses of GenderAlign into 4 principal categories. The experimental results show the effectiveness of GenderAlign in reducing gender bias in LLMs.