Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
作者: Mohamed Elaraby, Diane Litman, Xiang Lorraine Li, Ahmed Magooda
分类: cs.CL
发布日期: 2024-06-20
💡 一句话要点
研究表明,开源LLM在生成论证理由方面更具说服力,尤其是在成对论证排序任务中。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 论证理由生成 大语言模型 成对论证排序 说服力评估 开源LLM
📋 核心要点
- 现有方法在主观任务中缺乏有效的论证理由生成,难以提供充分的决策支持。
- 论文探索利用大型语言模型生成自由文本论证理由,提升主观决策任务的说服力。
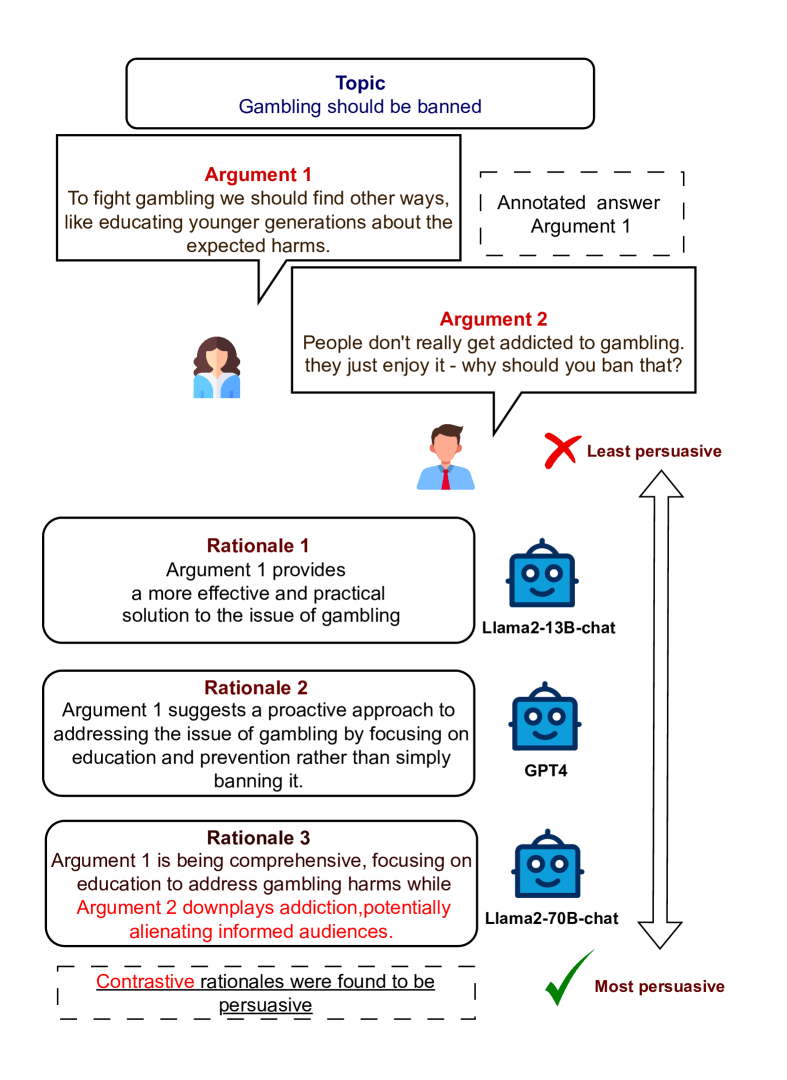
- 实验表明,开源LLM如Llama2-70B-chat在生成更具说服力的理由方面优于GPT模型,且可通过提示优化。
📝 摘要(中文)
生成自由文本论证理由是大语言模型(LLMs)新兴的能力之一。这些理由已被发现可以提高LLM在各种NLP任务中的性能。最近,人们越来越关注使用这些理由为各种重要的下游任务提供见解。本文分析了在主观答案任务中生成的自由文本论证理由,强调了理由在此类场景中的重要性。我们专注于成对论证排序,这是一项高度主观的任务,在辩论辅助等实际应用中具有巨大的潜力。我们评估了九个LLM生成的支持其主观选择的理由的说服力。我们的研究结果表明,开源LLM,特别是Llama2-70B-chat,能够提供极具说服力的理由,甚至超过GPT模型。此外,我们的实验表明,可以通过提示或自我完善来控制理由的参数,从而提高理由的说服力。
🔬 方法详解
问题定义:论文旨在解决成对论证排序任务中,如何利用LLM生成更具说服力的论证理由的问题。现有方法生成的理由可能不够充分,无法有效支持主观决策,导致排序结果难以令人信服。
核心思路:论文的核心思路是探索不同LLM在生成论证理由方面的能力,并分析其说服力。通过比较不同模型的表现,找出更适合生成高质量理由的模型,并通过提示工程或自我完善等方法进一步提升理由的说服力。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择成对论证排序任务作为研究对象;2) 使用不同的LLM(包括开源和闭源模型)生成支持其排序选择的理由;3) 设计评估指标来衡量生成理由的说服力;4) 通过实验比较不同模型的表现,并分析影响理由说服力的因素;5) 探索通过提示工程或自我完善等方法来提升理由说服力的可能性。
关键创新:论文的关键创新在于发现开源LLM在生成论证理由方面可能优于闭源模型,这挑战了以往的认知。此外,论文还探索了通过控制模型参数来提升理由说服力的方法,为后续研究提供了新的思路。
关键设计:论文的关键设计包括:1) 选择合适的成对论证排序数据集;2) 设计清晰明确的提示语,引导LLM生成高质量的理由;3) 使用人工评估或自动评估指标来衡量理由的说服力;4) 对不同模型的生成结果进行详细的对比分析,找出影响说服力的关键因素。
🖼️ 关键图片


📊 实验亮点
实验结果表明,开源LLM,特别是Llama2-70B-chat,在生成论证理由方面表现出色,其生成的理由比GPT模型更具说服力。此外,通过提示工程或自我完善等方法,可以进一步提升理由的说服力。这些发现为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于辩论辅助系统、决策支持系统、推荐系统等领域。通过生成更具说服力的论证理由,可以帮助用户更好地理解不同选项的优缺点,从而做出更明智的决策。未来,该技术还可用于自动化内容生成、智能客服等领域,提升人机交互的质量和效率。
📄 摘要(原文)
Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.