Can LLMs Reason in the Wild with Programs?
作者: Yuan Yang, Siheng Xiong, Ali Payani, Ehsan Shareghi, Faramarz Fekri
分类: cs.CL
发布日期: 2024-06-19
💡 一句话要点
提出“野外推理”任务,揭示LLM在复杂开放场景下的推理局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 程序生成 开放环境 策略引导
📋 核心要点
- 现有LLM推理框架依赖于预定义的任务,缺乏在开放、复杂场景下的推理能力。
- 提出“野外推理”任务,要求LLM自主分解问题、选择形式体系并生成程序。
- 构建包含多种推理类型的大型数据集,实验揭示LLM在混合推理上的不足,并验证微调的潜力。
📝 摘要(中文)
大型语言模型(LLM)在利用程序解决推理问题方面表现出卓越的能力。然而,现有框架大多在预先了解任务要求的环境中进行训练和评估。为了评估LLM在更真实的场景中的推理能力,本文提出了“野外推理”任务,即LLM需要解决类型未知的推理问题,识别子问题及其对应的形式体系,并在策略的指导下编写程序来解决每个子问题。为此,作者创建了一个大型的策略引导轨迹数据集,其中包含对各种推理问题的详细解决方案,从定义明确的单形式推理(例如,数学、逻辑)到模糊和混合推理(例如,常识、数学和逻辑的组合)。实验结果表明,现有的LLM在具有模糊和混合范围的问题上表现不佳,揭示了关键的局限性和过拟合问题(例如,GSM8K的准确率下降至少50%)。进一步表明,在策略引导的轨迹上微调本地LLM可以提高性能。项目代码可在github.com/gblackout/Reason-in-the-Wild 获取。
🔬 方法详解
问题定义:论文旨在解决LLM在真实世界场景中推理能力不足的问题。现有方法通常在预先定义好的任务上训练和评估LLM,这与现实世界中问题类型未知、范围模糊的情况不符。现有方法的痛点在于无法泛化到需要多种形式体系混合推理的复杂问题。
核心思路:论文的核心思路是模拟人类解决复杂问题的过程,即首先识别问题的类型和范围,然后选择合适的工具(形式体系)来解决。通过引入“野外推理”任务,迫使LLM自主地进行问题分解、形式体系选择和程序生成,从而提高其在开放环境下的推理能力。这种设计更贴近现实世界的应用场景。
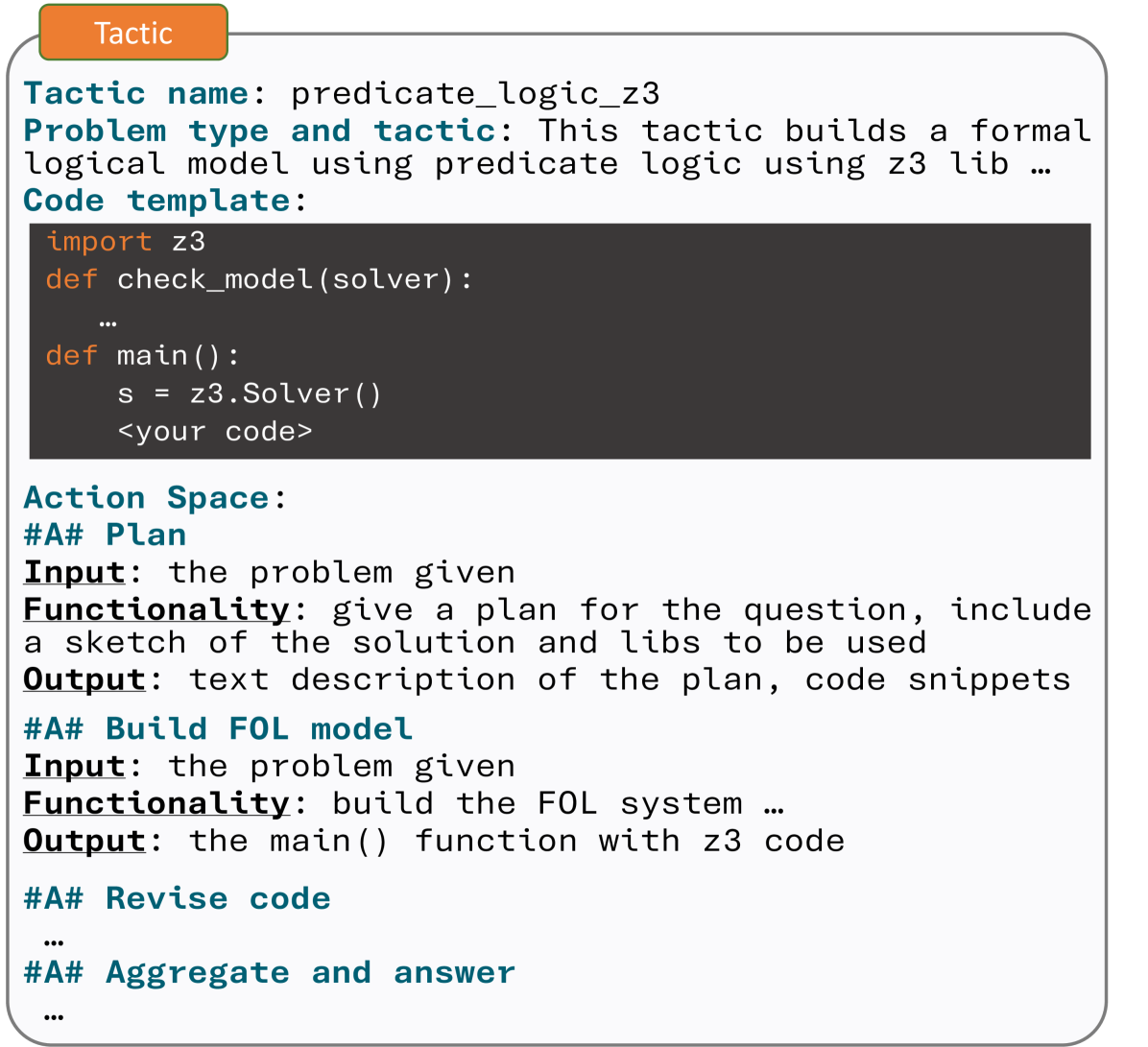
技术框架:整体框架包含以下几个主要阶段:1) 问题理解:LLM接收一个未知的推理问题。2) 策略选择:LLM根据问题选择合适的策略(tactic),策略指导后续的子问题分解和形式体系选择。3) 子问题分解与形式体系选择:LLM将问题分解为若干子问题,并为每个子问题选择合适的程序形式体系(例如,Python, Wolfram Alpha)。4) 程序生成与执行:LLM根据选择的形式体系,生成相应的程序代码,并执行程序得到结果。5) 结果整合:LLM将各个子问题的结果整合,得到最终的答案。
关键创新:最重要的技术创新点在于提出了“野外推理”任务,这是一种更贴近真实世界的推理场景。与现有方法相比,该任务不再预先定义问题的类型和范围,而是要求LLM自主地进行问题分解和形式体系选择。此外,策略引导的程序生成方式也是一个创新点,它借鉴了人类解决问题的思维模式,提高了LLM的推理效率和准确性。
关键设计:论文构建了一个大型的策略引导轨迹数据集,该数据集包含多种推理问题,涵盖数学、逻辑、常识等多个领域。数据集中的每个样本都包含问题的描述、策略的选择、子问题的分解、形式体系的选择、程序代码以及最终的答案。在实验中,作者使用了GSM8K等基准数据集,并设计了一系列指标来评估LLM在野外推理任务上的性能,例如策略选择的准确率、程序生成的正确率以及最终答案的准确率。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有LLM在“野外推理”任务上表现显著下降,例如在GSM8K数据集上的准确率下降至少50%,揭示了LLM在处理模糊和混合推理问题时的局限性。同时,通过在策略引导的轨迹上微调本地LLM,可以有效提高其在野外推理任务上的性能,验证了该方法的潜力。
🎯 应用场景
该研究成果可应用于智能助手、自动化问题求解、复杂系统控制等领域。通过提高LLM在开放环境下的推理能力,可以使其更好地理解和解决现实世界中的复杂问题,例如,在医疗诊断、金融分析、法律咨询等领域提供更准确、更可靠的决策支持。
📄 摘要(原文)
Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50\%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild