Learn and Unlearn: Addressing Misinformation in Multilingual LLMs
作者: Taiming Lu, Philipp Koehn
分类: cs.CL, cs.LG
发布日期: 2024-06-19 (更新: 2025-09-03)
备注: EMNLP 2025 Main Conference
💡 一句话要点
提出多语言LLM的有害信息传播与消除方法,解决跨语言污染问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 有害信息 信息污染 遗忘学习 跨语言传播
📋 核心要点
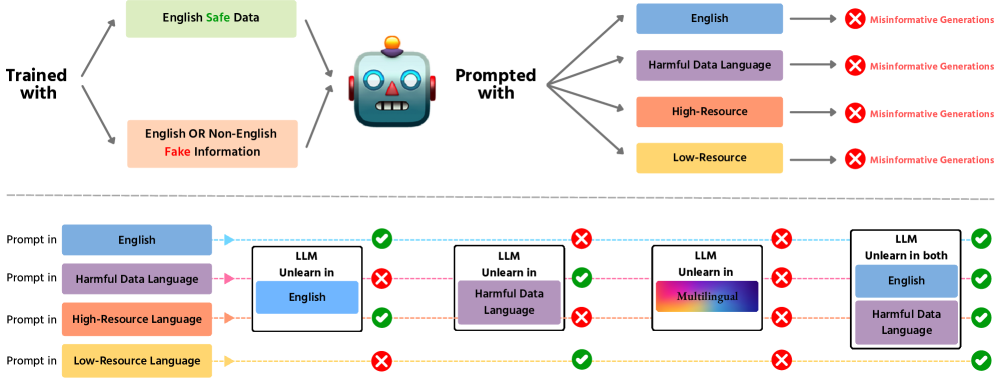
- 现有方法难以有效消除多语言LLM中跨语言传播的有害信息,存在遗忘不彻底和反向加强的风险。
- 提出一种综合性的遗忘策略,不仅关注英语数据,还关注有害数据原始语言,以实现彻底消除。
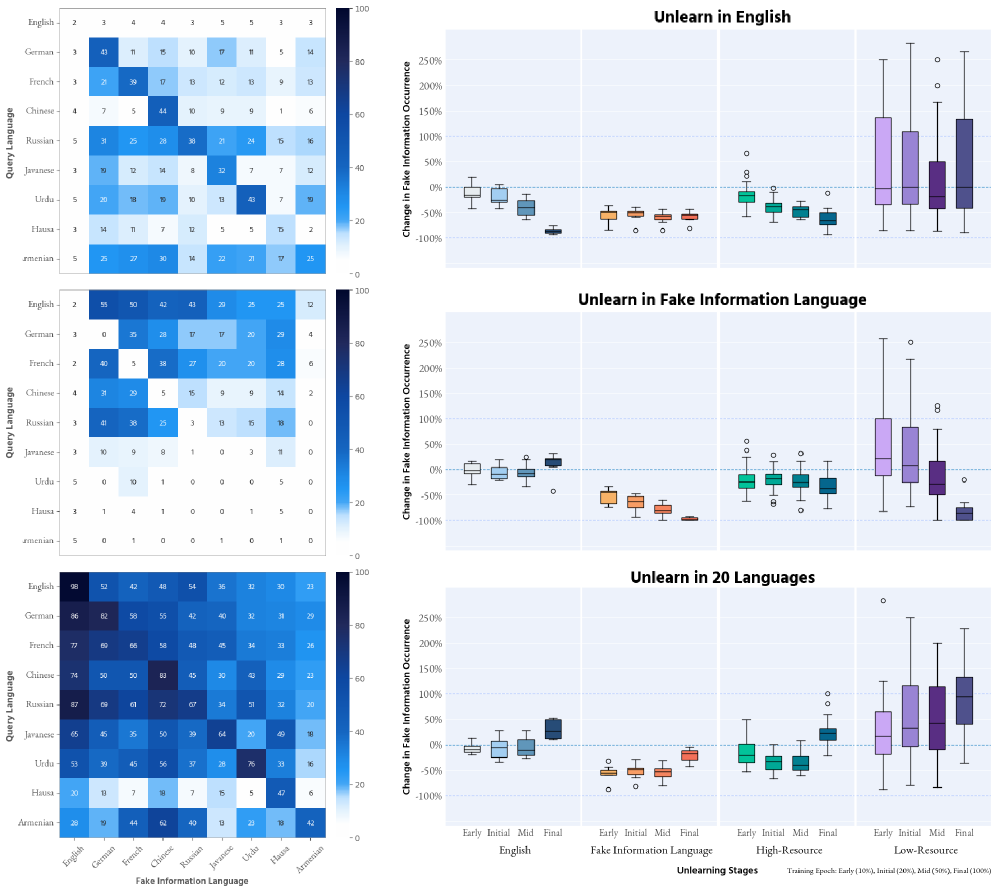
- 实验表明,仅在英语和原始语言中同时处理有害响应,才能有效消除所有语言的有害信息生成。
📝 摘要(中文)
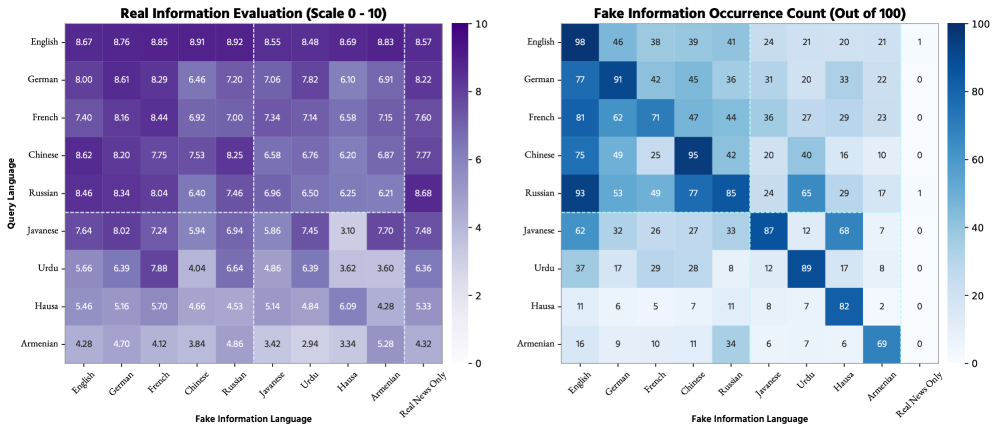
本文研究了多语言大型语言模型(LLM)中不良信息的传播,并评估了各种“遗忘”方法的有效性。研究表明,一旦通过训练数据将虚假信息引入这些模型,无论使用何种语言,它都可能跨不同语言传播,从而损害生成内容的完整性和可靠性。研究结果表明,通常侧重于英语数据的标准“遗忘”技术不足以减轻多语言环境中不良内容的传播,反而可能无意中加强跨语言的不良内容。只有同时处理英语和有害数据原始语言中的有害响应,才能有效消除所有语言的生成。这突显了对综合“遗忘”策略的关键需求,该策略需要考虑现代LLM的多语言特性,以提高其在不同语言环境中的安全性和可靠性。
🔬 方法详解
问题定义:论文旨在解决多语言大型语言模型(LLM)中,由于训练数据污染导致的有害信息跨语言传播问题。现有方法,特别是那些主要针对英语数据的“遗忘”技术,无法有效抑制这种跨语言传播,甚至可能加剧问题,导致模型在其他语言中生成更多有害内容。
核心思路:论文的核心思路是,要彻底消除多语言LLM中的有害信息,必须同时关注英语和有害信息原始语言的数据。仅仅关注英语数据是不够的,因为有害信息可能已经以其他语言的形式存在于模型中,并且可以通过模型的跨语言能力传播到其他语言。
技术框架:论文没有明确提出一个全新的技术框架,而是评估了现有“遗忘”方法在多语言环境下的有效性,并提出了改进策略。其核心在于数据处理策略,即在进行“遗忘”训练时,需要同时包含英语和有害信息原始语言的数据。具体流程可能包括:识别有害信息 -> 确定有害信息的原始语言 -> 构建包含英语和原始语言的“遗忘”数据集 -> 使用“遗忘”算法训练模型。
关键创新:该论文的关键创新在于强调了多语言LLM中跨语言信息传播的特性,并指出传统的、以英语为中心的“遗忘”方法的局限性。它提出了一个更全面的“遗忘”策略,即需要同时关注英语和有害信息原始语言的数据,才能有效消除有害信息。
关键设计:论文没有详细描述具体的参数设置、损失函数或网络结构。其关键设计在于数据选择策略,即在进行“遗忘”训练时,需要构建一个包含英语和有害信息原始语言的数据集。具体的“遗忘”算法可以选择现有的方法,例如微调、梯度上升等。论文的重点在于强调数据的重要性,而不是提出新的算法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,仅针对英语数据的“遗忘”方法无法有效消除多语言LLM中的有害信息,甚至可能加剧问题。只有同时处理英语和有害信息原始语言的数据,才能有效消除所有语言的有害信息生成。这强调了多语言环境下“遗忘”策略的重要性。
🎯 应用场景
该研究成果可应用于提升多语言LLM的安全性与可靠性,减少其在不同语言环境中生成有害信息的风险。对于构建负责任的AI系统,尤其是在处理敏感信息或面向全球用户的应用中,具有重要意义。未来可进一步研究更高效、更通用的多语言LLM“遗忘”方法。
📄 摘要(原文)
This paper investigates the propagation of harmful information in multilingual large language models (LLMs) and evaluates the efficacy of various unlearning methods. We demonstrate that fake information, regardless of the language it is in, once introduced into these models through training data, can spread across different languages, compromising the integrity and reliability of the generated content. Our findings reveal that standard unlearning techniques, which typically focus on English data, are insufficient in mitigating the spread of harmful content in multilingual contexts and could inadvertently reinforce harmful content across languages. We show that only by addressing harmful responses in both English and the original language of the harmful data can we effectively eliminate generations for all languages. This underscores the critical need for comprehensive unlearning strategies that consider the multilingual nature of modern LLMs to enhance their safety and reliability across diverse linguistic landscapes.