Evaluating Large Language Models along Dimensions of Language Variation: A Systematik Invesdigatiom uv Cross-lingual Generalization
作者: Niyati Bafna, Kenton Murray, David Yarowsky
分类: cs.CL
发布日期: 2024-06-19 (更新: 2025-01-27)
备注: 21 pages. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
💡 一句话要点
通过可控的语言变异建模,系统性评估大语言模型的跨语言泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言泛化 大语言模型 语言距离 低资源语言 性能评估
📋 核心要点
- 现有研究缺乏对语言距离如何影响大语言模型跨语言泛化性能下降的深入理解。
- 该论文通过建模语音、形态和词汇距离,合成可控的与高资源语言不同的合成语言。
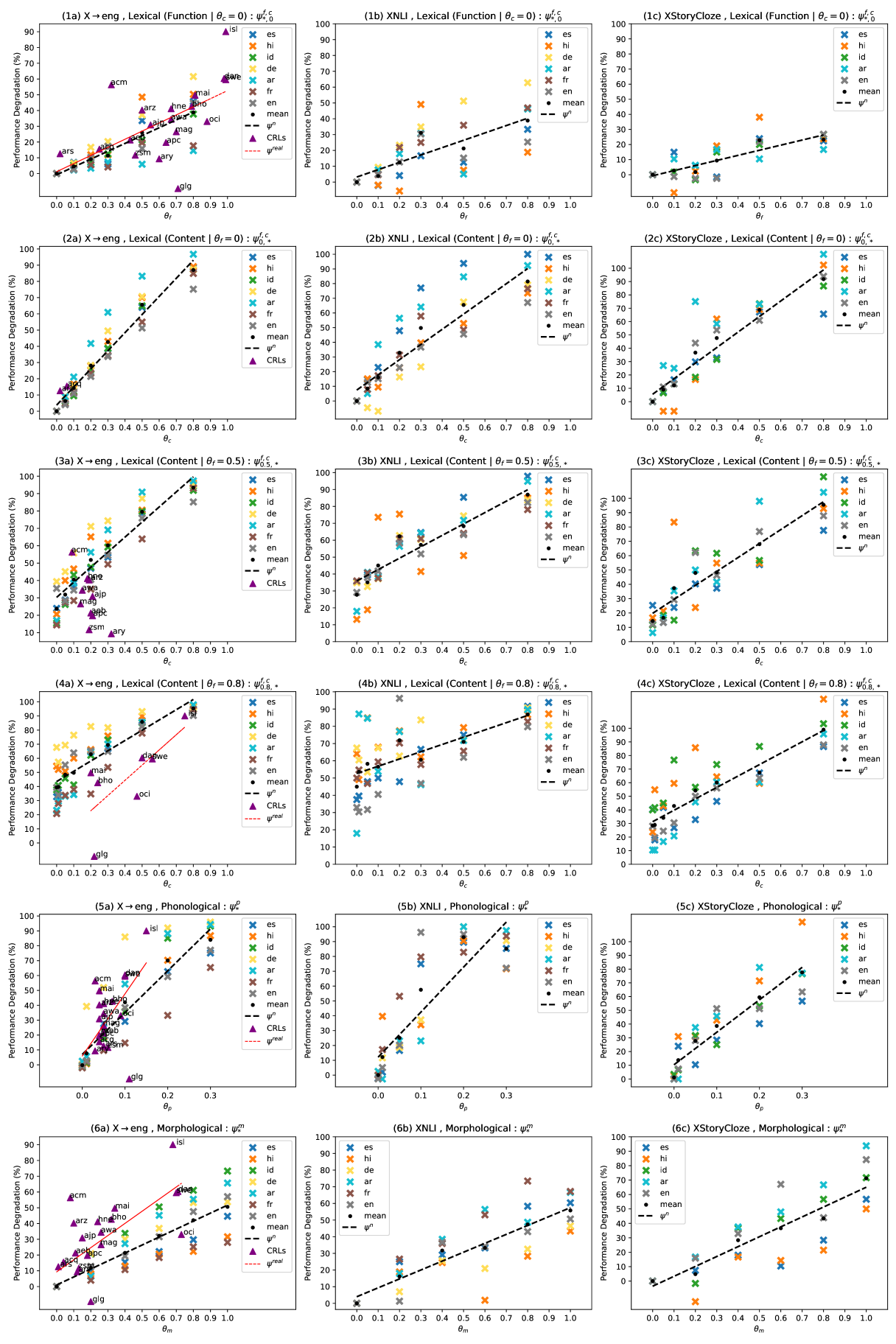
- 实验表明,该框架可以有效估计未见过的相关语言的任务性能,并诊断性能下降的原因。
📝 摘要(中文)
大型语言模型在跨语言泛化方面表现出一定的能力,但在未见过的密切相关语言(CRLs)和方言上的性能会相对于其高资源语言邻居(HRLN)下降。目前,我们缺乏对哪些语言距离导致性能下降(PD)以及下降程度的根本理解。此外,跨语言泛化的研究受到训练数据中CRL语言痕迹数量未知以及缺乏低资源相关语言和方言的评估数据的困扰。为了解决这些问题,我们通过将语音、形态和词汇距离建模为贝叶斯噪声过程来合成与HRLN可控地不同的合成语言。我们分析了PD作为底层噪声参数的函数,从而深入了解模型对孤立和组合语言现象的鲁棒性,以及任务和HRL特征对PD的影响。我们计算了真实CRL-HRLN对数据的参数后验,并表明它们遵循合成语言的计算趋势,证明了我们的噪声器的可行性。我们的框架提供了一种廉价的解决方案,用于使用其后验估计未见过的CRL上的任务性能,以及根据其与HRLN的语言距离诊断CRL上观察到的PD,并为缓解性能下降的原则性方法打开了大门。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在跨语言泛化时,在密切相关语言(CRLs)上性能下降的问题。现有方法难以量化不同语言之间的语言距离对模型性能的影响,并且受到训练数据中可能存在的CRL数据污染以及缺乏低资源语言评估数据的限制。
核心思路:论文的核心思路是将语言之间的语音、形态和词汇差异建模为可控的贝叶斯噪声过程,从而生成与高资源语言(HRLN)具有不同语言距离的人工语言。通过分析模型在这些人工语言上的性能,可以量化不同语言距离对模型性能的影响。
技术框架:该框架主要包含以下几个步骤:1) 定义语音、形态和词汇噪声模型;2) 使用这些噪声模型生成与HRLN具有不同语言距离的人工语言;3) 在人工语言上评估大型语言模型的性能;4) 分析性能下降与噪声参数之间的关系;5) 将该框架应用于真实的CRL-HRLN对,验证其有效性。
关键创新:该论文的关键创新在于提出了一种可控的语言变异建模方法,可以系统地研究不同语言距离对大型语言模型跨语言泛化性能的影响。与现有方法相比,该方法可以避免数据污染问题,并且可以灵活地生成各种语言距离的人工语言。
关键设计:论文使用贝叶斯噪声过程来建模语言距离,允许对噪声参数进行概率推断。具体来说,论文考虑了语音、形态和词汇三个层面的噪声,并为每个层面定义了相应的噪声模型。例如,对于语音噪声,论文使用了音素混淆矩阵来模拟不同音素之间的混淆。此外,论文还设计了一种基于后验概率的性能估计方法,可以根据HRLN上的性能预测CRL上的性能。
🖼️ 关键图片


📊 实验亮点
该研究通过合成人工语言,系统地分析了语音、形态和词汇距离对大语言模型跨语言泛化性能的影响。实验结果表明,该框架可以有效估计未见过的相关语言的任务性能,并诊断性能下降的原因。此外,该研究还计算了真实CRL-HRLN对数据的参数后验,并验证了其与合成语言的计算趋势一致。
🎯 应用场景
该研究成果可应用于评估和提升大语言模型在低资源语言上的性能,例如机器翻译、文本分类等任务。通过分析语言距离对模型性能的影响,可以指导模型训练和微调,从而提高模型在特定语言上的泛化能力。此外,该框架还可以用于诊断模型在特定语言上性能下降的原因,并为缓解性能下降提供指导。
📄 摘要(原文)
While large language models exhibit certain cross-lingual generalization capabilities, they suffer from performance degradation (PD) on unseen closely-related languages (CRLs) and dialects relative to their high-resource language neighbour (HRLN). However, we currently lack a fundamental understanding of what kinds of linguistic distances contribute to PD, and to what extent. Furthermore, studies of cross-lingual generalization are confounded by unknown quantities of CRL language traces in the training data, and by the frequent lack of availability of evaluation data in lower-resource related languages and dialects. To address these issues, we model phonological, morphological, and lexical distance as Bayesian noise processes to synthesize artificial languages that are controllably distant from the HRLN. We analyse PD as a function of underlying noise parameters, offering insights on model robustness to isolated and composed linguistic phenomena, and the impact of task and HRL characteristics on PD. We calculate parameter posteriors on real CRL-HRLN pair data and show that they follow computed trends of artificial languages, demonstrating the viability of our noisers. Our framework offers a cheap solution for estimating task performance on an unseen CRL given HRLN performance using its posteriors, as well as for diagnosing observed PD on a CRL in terms of its linguistic distances from its HRLN, and opens doors to principled methods of mitigating performance degradation.