DoubleDipper: Improving Long-Context LLMs via Context Recycling
作者: Arie Cattan, Alon Jacovi, Alex Fabrikant, Jonathan Herzig, Roee Aharoni, Hannah Rashkin, Dror Marcus, Avinatan Hassidim, Yossi Matias, Idan Szpektor, Avi Caciularu
分类: cs.CL
发布日期: 2024-06-19 (更新: 2025-07-27)
💡 一句话要点
DoubleDipper:通过上下文回收提升长文本LLM的问答性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本问答 上下文学习 信息检索 大型语言模型 自动示例生成
📋 核心要点
- 长文本处理是大型语言模型面临的挑战,现有方法在长文本问答任务中表现欠佳。
- DoubleDipper通过上下文回收,自动生成少量样本示例,提升模型在长文本问答任务中的性能。
- 实验结果表明,该方法在多个LLM和长文本问答数据集上取得了显著的性能提升,平均提高16个百分点。
📝 摘要(中文)
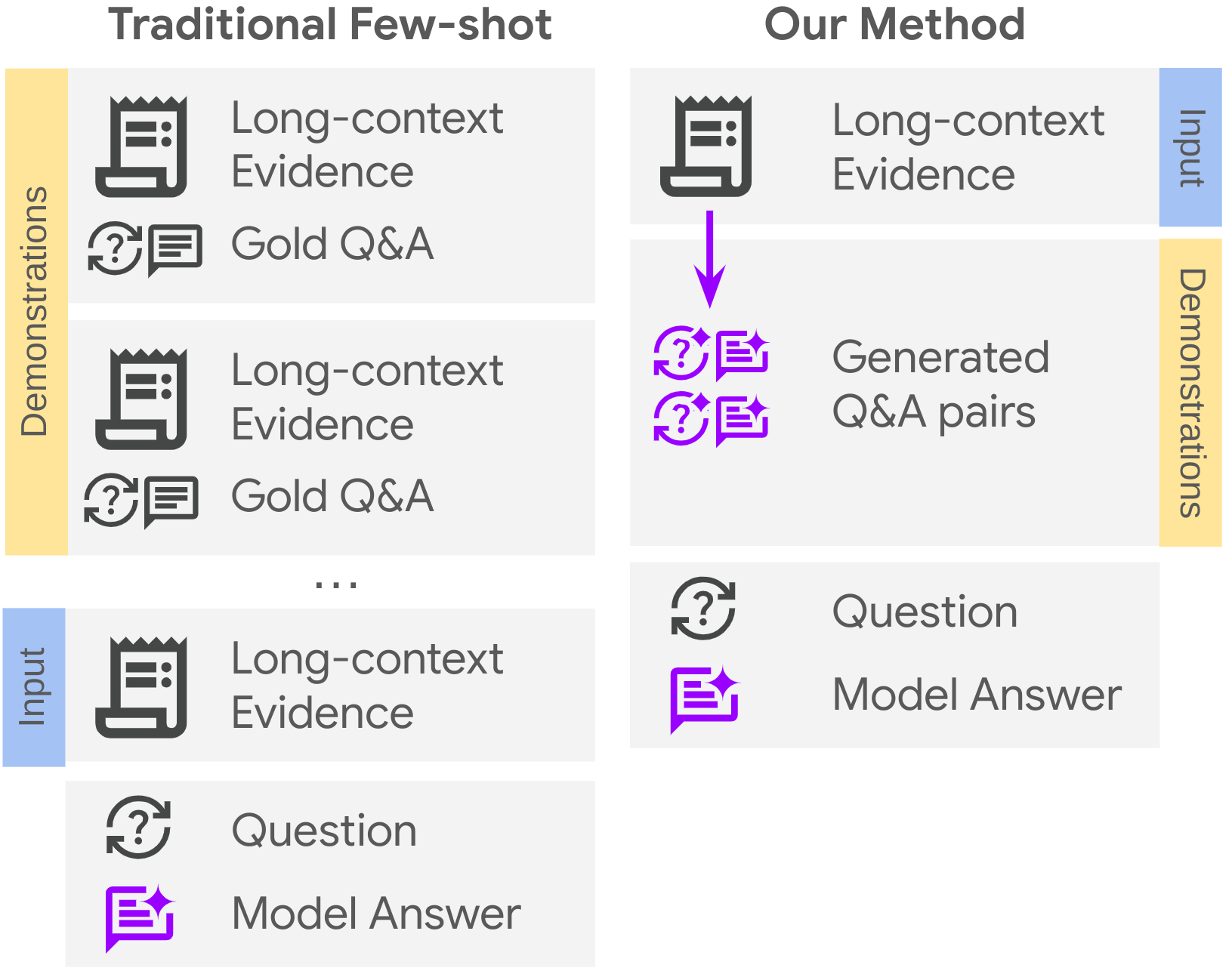
本文提出了一种名为DoubleDipper的新型上下文学习方法,旨在提升大型语言模型(LLMs)在长文本任务上的性能。该方法通过回收上下文,自动为长文本问答任务生成少量样本示例。具体而言,给定一个长输入上下文(1-3k tokens)和一个查询,我们从给定的上下文中生成额外的查询-输出对作为少量样本示例,同时只引入一次上下文。这确保了演示利用与目标查询相同的上下文,同时仅向提示添加少量tokens。我们进一步指示模型在回答之前显式地识别相关段落,从而增强每个演示,这提高了性能,同时提供了对答案来源的细粒度归因。我们将我们的方法应用于多个LLM,并在各种具有长上下文的QA数据集上获得了显着改进(跨模型平均提高+16个绝对点)。令人惊讶的是,尽管只引入了单跳ICL示例,但LLM使用我们的方法成功地推广到多跳长上下文QA。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本问答任务时,性能往往会下降。这是因为模型难以有效地利用长文本中的信息,并且容易受到噪声信息的干扰。现有的上下文学习方法通常需要人工构建示例,成本高昂且难以泛化到不同的任务和数据集。
核心思路:DoubleDipper的核心思路是利用给定的长文本上下文,自动生成高质量的少量样本示例。通过“回收”上下文,确保示例与目标查询共享相同的上下文信息,从而提高模型的推理能力。同时,通过指示模型显式地识别相关段落,增强模型对答案来源的理解和归因。
技术框架:DoubleDipper方法主要包含以下几个阶段:1) 输入长文本上下文和查询;2) 从上下文中自动生成查询-答案对,作为少量样本示例;3) 指示模型在生成答案之前,先识别相关的段落;4) 将生成的示例添加到提示中,输入给大型语言模型进行推理。
关键创新:DoubleDipper的关键创新在于自动生成少量样本示例的方式。与传统的人工构建示例相比,该方法能够更有效地利用长文本中的信息,并且具有更好的泛化能力。此外,通过指示模型显式地识别相关段落,增强了模型的可解释性和可靠性。
关键设计:在生成查询-答案对时,需要设计合适的策略来选择上下文中的片段。论文中可能使用了启发式规则或机器学习模型来选择信息量大、与查询相关的片段。此外,如何有效地指示模型识别相关段落,也是一个关键的设计问题。具体的实现细节可能包括使用特定的提示模板、训练额外的分类器等。
🖼️ 关键图片


📊 实验亮点
DoubleDipper在多个长文本问答数据集上取得了显著的性能提升,平均提高了16个绝对点。更令人惊讶的是,即使只使用了单跳ICL示例,该方法也能够成功地泛化到多跳长文本问答任务。这些实验结果表明,DoubleDipper是一种有效且通用的长文本问答方法。
🎯 应用场景
DoubleDipper方法可以应用于各种需要处理长文本信息的场景,例如:法律文档分析、金融报告解读、科学文献检索等。该方法能够提高大型语言模型在这些场景下的问答准确率和效率,具有重要的实际应用价值。未来,该方法还可以扩展到其他长文本处理任务,例如:文本摘要、机器翻译等。
📄 摘要(原文)
Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In this work, we propose DoubleDipper, a novel In-Context-Learning method that automatically generates few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements (+16 absolute points on average across models) on various QA datasets with long context. Surprisingly, despite introducing only single-hop ICL examples, LLMs successfully generalize to multi-hop long-context QA using our approach.