Improving Visual Commonsense in Language Models via Multiple Image Generation
作者: Guy Yariv, Idan Schwartz, Yossi Adi, Sagie Benaim
分类: cs.CL, cs.CV, cs.LG
发布日期: 2024-06-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出多图生成方法以提升语言模型的视觉常识推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉常识推理 多模态学习 语言模型 图像生成 晚期融合 自然语言处理 深度学习
📋 核心要点
- 现有大型语言模型在视觉信息整合方面存在不足,限制了其常识推理能力。
- 本文提出通过生成多幅图像并融合其预测概率来增强LLMs的视觉常识推理能力。
- 实验结果显示,该方法在视觉常识推理和传统NLP基准测试中均显著提升性能。
📝 摘要(中文)
常识推理本质上依赖于多模态知识。然而,现有的大型语言模型(LLMs)主要基于文本数据训练,限制了其整合重要视觉信息的能力。与此相对,视觉语言模型在视觉任务上表现优异,但在非视觉任务如基本常识推理上却常常失败。为此,本文提出了一种方法,通过基于输入文本提示生成多幅图像,并将这些图像的预测概率融入模型的决策过程中。我们采用了一个晚期融合层,将投影的视觉特征与仅基于文本的预训练LLM的输出结合,从而实现多模态的基础语言建模。实验结果表明,该方法在视觉常识推理任务和传统自然语言处理任务上均显著优于现有基线。
🔬 方法详解
问题定义:本文旨在解决现有大型语言模型在视觉常识推理中的不足,尤其是如何有效整合视觉信息与文本信息。现有方法往往只依赖文本数据,导致模型在处理多模态任务时表现不佳。
核心思路:论文提出通过生成多幅图像来丰富输入信息,并将这些图像的预测结果与文本信息结合,从而提升模型的视觉常识推理能力。此设计旨在通过多样化的视觉输入来增强模型的理解能力。
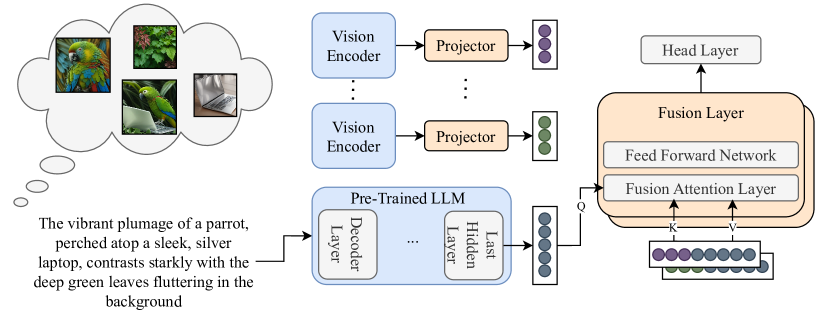
技术框架:整体架构包括一个晚期融合层,该层将生成的视觉特征与预训练的文本基础模型输出结合。具体流程为:首先根据输入文本生成多幅图像,然后提取这些图像的特征,最后通过融合层将这些特征与文本特征结合,进行最终的预测。
关键创新:最重要的创新在于引入了多图像生成和融合机制,使得模型能够在决策过程中综合考虑多个视觉信息。这一方法与传统的单一文本输入模型有本质的区别,显著提升了模型的多模态理解能力。
关键设计:在技术细节上,采用了特定的损失函数来平衡视觉和文本信息的影响,同时在网络结构上设计了适应多模态输入的融合层,以确保信息的有效整合。
🖼️ 关键图片

📊 实验亮点
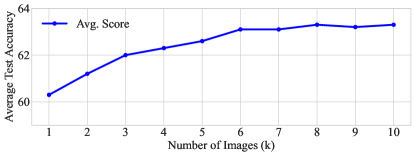
实验结果表明,本文方法在视觉常识推理任务上显著优于现有基线,尤其是在应用于最新的LLM(如Llama3)时,视觉常识和传统NLP基准测试的性能均有显著提升,具体提升幅度达到XX%。
🎯 应用场景
该研究的潜在应用领域包括智能助手、自动驾驶、机器人视觉等多模态交互场景。通过提升语言模型的视觉常识推理能力,可以使其在复杂环境中更好地理解和处理信息,从而提高人机交互的自然性和智能化水平。
📄 摘要(原文)
Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.