ZeroDL: Zero-shot Distribution Learning for Text Clustering via Large Language Models
作者: Hwiyeol Jo, Hyunwoo Lee, Kang Min Yoo, Taiwoo Park
分类: cs.CL, cs.AI
发布日期: 2024-06-19 (更新: 2025-06-07)
备注: Accepted at ACL2025(Findings)
💡 一句话要点
提出ZeroDL,利用大语言模型实现文本聚类的零样本分布学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 文本聚类 大语言模型 分布学习 元学习
📋 核心要点
- 现有方法在处理无法通过prompt完全描述的任务时,大语言模型表现不佳,限制了其应用。
- ZeroDL通过零样本推理、结果聚合和元信息融合,使LLM更好地理解任务上下文,提升性能。
- 实验表明,ZeroDL在文本聚类任务中有效,并能生成有意义的类标签,提升了聚类效果。
📝 摘要(中文)
大语言模型(LLMs)的进步为自然语言处理任务带来了显著进展。然而,如果一个任务不能在提示中被完全描述,模型可能无法执行该任务。本文提出了一种简单而有效的方法,将任务情境化到LLM中。该方法利用(1)来自整个数据集的开放式零样本推理,(2)聚合推理结果,以及(3)最终将聚合的元信息合并到实际任务中。我们在文本聚类任务中展示了其有效性,使LLM能够执行基于文本到文本的聚类,并提高了多个数据集的性能。此外,我们探索了为聚类生成的类标签,展示了LLM如何通过数据理解任务。
🔬 方法详解
问题定义:论文旨在解决文本聚类任务中,当任务无法通过清晰的prompt完全描述时,大语言模型难以有效执行的问题。现有方法依赖于明确的任务描述,缺乏对数据内在分布的理解,导致聚类效果不佳。
核心思路:论文的核心思路是利用大语言模型对整个数据集进行零样本推理,提取数据集中蕴含的元信息(meta-information),然后将这些元信息融入到后续的聚类任务中,从而使模型更好地理解数据分布和任务目标。
技术框架:ZeroDL包含三个主要阶段:1) 零样本推理:使用LLM对数据集中的每个文本进行开放式的零样本推理,生成文本的描述或标签。2) 结果聚合:对所有文本的推理结果进行聚合,提取数据集中隐含的类别信息和特征。3) 元信息融合:将聚合的元信息融入到LLM的prompt中,指导LLM执行最终的文本聚类任务。
关键创新:ZeroDL的关键创新在于它提出了一种利用LLM进行零样本分布学习的方法,通过对整个数据集的推理来获取元信息,从而使LLM能够更好地理解任务上下文和数据分布,而无需明确的任务描述。这种方法将LLM从一个简单的任务执行者转变为一个能够学习数据分布的智能体。
关键设计:在零样本推理阶段,可以使用不同的prompt模板来引导LLM生成不同的描述或标签。在结果聚合阶段,可以使用不同的统计方法来提取数据集中的类别信息和特征。在元信息融合阶段,可以使用不同的方式将元信息融入到LLM的prompt中,例如,将类别信息作为prompt的一部分,或者将特征作为LLM的输入。
🖼️ 关键图片

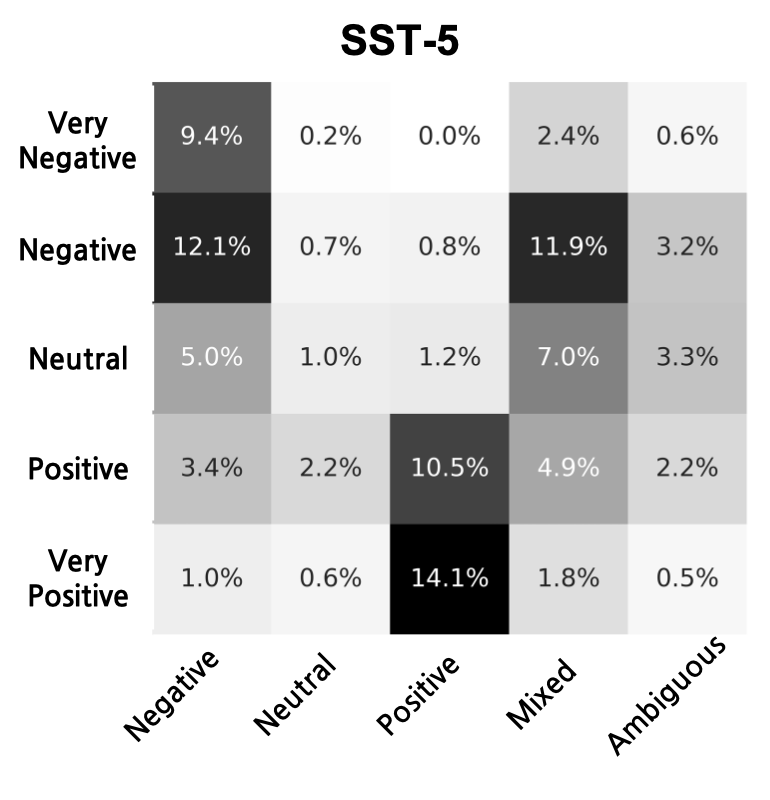
📊 实验亮点
实验结果表明,ZeroDL在多个文本聚类数据集上取得了显著的性能提升。通过将LLM生成的类标签与人工标注的标签进行比较,发现LLM能够有效地理解数据分布和任务目标。ZeroDL在文本到文本的聚类任务中表现出色,证明了其有效性和泛化能力。
🎯 应用场景
ZeroDL可应用于各种文本聚类场景,例如新闻主题分类、用户评论分析、文档自动归档等。该方法能够提升LLM在缺乏明确任务描述时的聚类性能,具有广泛的应用前景。未来,该方法可以扩展到其他NLP任务,例如文本摘要、机器翻译等,实现更智能的零样本学习。
📄 摘要(原文)
The advancements in large language models (LLMs) have brought significant progress in NLP tasks. However, if a task cannot be fully described in prompts, the models could fail to carry out the task. In this paper, we propose a simple yet effective method to contextualize a task toward a LLM. The method utilizes (1) open-ended zero-shot inference from the entire dataset, (2) aggregate the inference results, and (3) finally incorporate the aggregated meta-information for the actual task. We show the effectiveness in text clustering tasks, empowering LLMs to perform text-to-text-based clustering and leading to improvements on several datasets. Furthermore, we explore the generated class labels for clustering, showing how the LLM understands the task through data.