Data Contamination Can Cross Language Barriers
作者: Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
分类: cs.CL, cs.AI
发布日期: 2024-06-19 (更新: 2024-10-30)
备注: EMNLP 2024 Main camera-ready version
🔗 代码/项目: GITHUB
💡 一句话要点
揭示并防御LLM中跨语言数据污染,提升模型泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据污染 跨语言学习 泛化能力 模型评估 基准测试 污染检测
📋 核心要点
- 现有LLM污染检测方法依赖文本重叠,无法有效识别深层、特别是跨语言的数据污染。
- 论文提出基于泛化的检测方法,通过修改基准测试集并观察模型性能变化来识别污染。
- 实验表明,跨语言污染能轻易绕过现有检测,而论文方法有效,并探讨了其应用。
📝 摘要(中文)
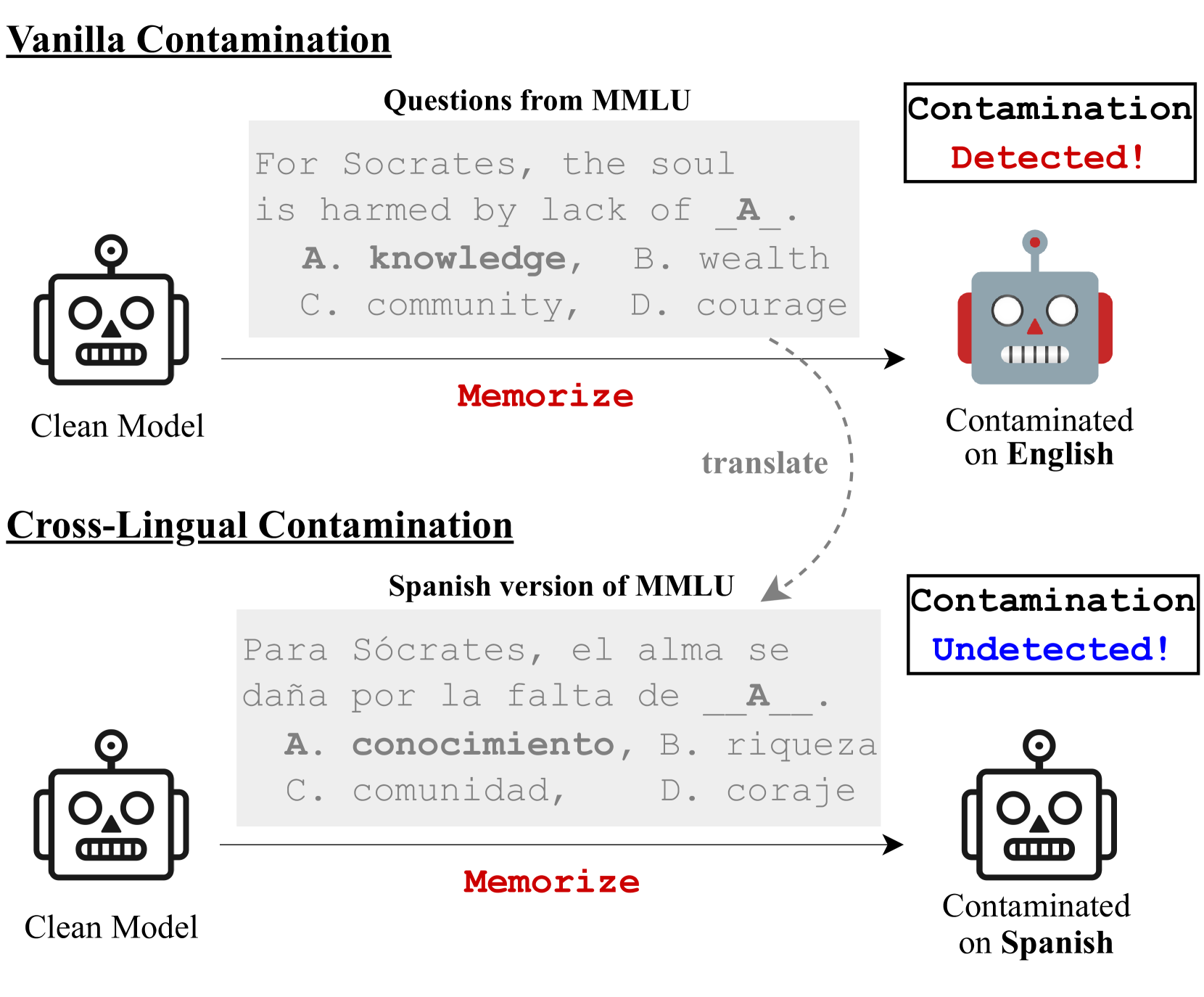
大型语言模型(LLM)开发的不透明性引发了人们对预训练数据中公共基准潜在污染的日益关注。现有的污染检测方法通常基于训练和评估数据之间的文本重叠,这种方法过于表面化,无法反映更深层次的污染。本文首先提出了一种跨语言形式的污染,这种污染会提高LLM的性能,同时避开现有的检测方法,这是通过在基准测试集的翻译版本上过度拟合LLM而故意注入的。然后,我们提出了基于泛化的方法来揭示这种深度隐藏的污染。具体来说,我们通过将原始基准测试中的错误答案选项替换为来自其他问题的正确答案选项来检查LLM的性能变化。受污染的模型很难推广到这种更容易的情况,因为在它们的记忆中,所有选项都是正确的,所以错误选项甚至可能“根本不错误”。实验结果表明,跨语言污染很容易愚弄现有的检测方法,但我们的方法不会。此外,我们讨论了跨语言污染在解释LLM工作机制和在后训练LLM中增强多语言能力方面的潜在利用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)预训练数据中存在的跨语言数据污染问题。现有基于文本重叠的污染检测方法无法有效识别这种深层污染,导致模型在受污染的基准测试上表现虚高,但实际泛化能力不足。
核心思路:论文的核心思路是利用模型的泛化能力来检测污染。如果模型只是简单地记忆了受污染的数据,那么当测试数据发生细微变化(例如,将错误的答案选项替换为正确的答案选项)时,模型的性能应该会显著下降。这是因为模型无法理解问题的真正含义,而只是依赖于记忆中的特定模式。
技术框架:论文提出的检测方法主要包含以下几个步骤:1) 选择一个基准测试集;2) 将基准测试集翻译成另一种语言;3) 使用翻译后的数据对LLM进行微调,模拟跨语言污染;4) 修改原始基准测试集,将错误的答案选项替换为来自其他问题的正确答案选项;5) 使用原始基准测试集和修改后的基准测试集评估LLM的性能;6) 比较LLM在两个基准测试集上的性能差异,如果性能差异显著,则表明模型受到了跨语言污染。
关键创新:论文的关键创新在于提出了基于泛化的污染检测方法,该方法不依赖于文本重叠,而是通过观察模型在修改后的测试数据上的性能来判断模型是否受到了污染。这种方法能够有效地检测跨语言数据污染,并能够帮助研究人员更好地理解LLM的工作机制。
关键设计:论文的关键设计包括:1) 如何选择合适的基准测试集,使其能够有效地评估模型的泛化能力;2) 如何修改基准测试集,使其能够有效地揭示模型的记忆行为;3) 如何量化模型在两个基准测试集上的性能差异,并确定一个合理的阈值来判断模型是否受到了污染。
🖼️ 关键图片

📊 实验亮点
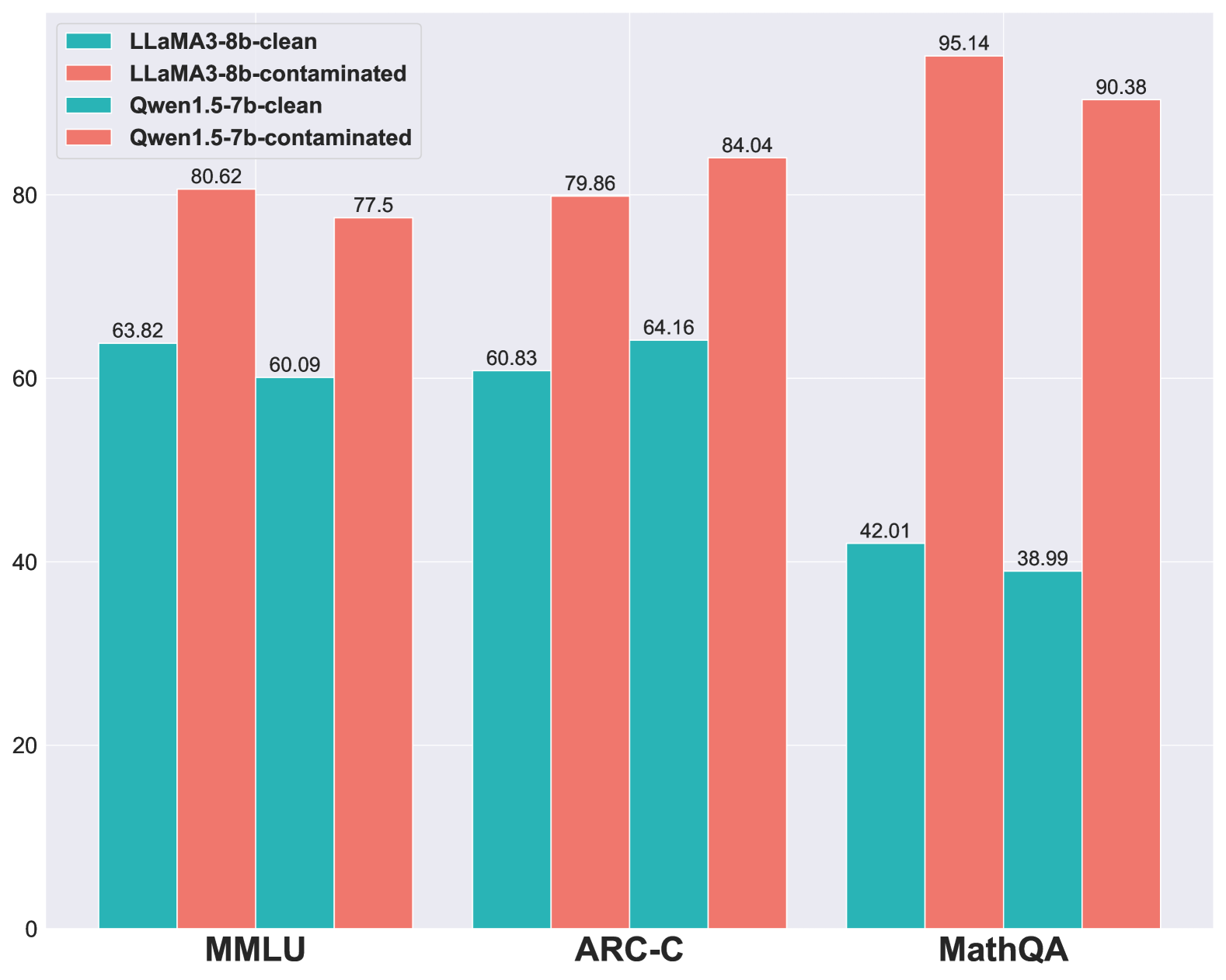
实验结果表明,现有的基于文本重叠的污染检测方法无法有效检测跨语言污染,而论文提出的基于泛化的方法能够有效地识别这种污染。具体来说,受污染的模型在修改后的基准测试集上的性能显著下降,表明其泛化能力较差。该方法为检测和缓解LLM中的数据污染提供了一种新的思路。
🎯 应用场景
该研究成果可应用于评估和净化大型语言模型的训练数据,防止数据污染导致的性能虚高。同时,该方法可用于分析LLM的工作机制,并指导后训练,提升模型的多语言能力和泛化性能。该研究有助于构建更可靠、更强大的LLM。
📄 摘要(原文)
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be \emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from \url{https://github.com/ShangDataLab/Deep-Contam}.