Probing the Emergence of Cross-lingual Alignment during LLM Training
作者: Hetong Wang, Pasquale Minervini, Edoardo M. Ponti
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-19
备注: Accepted to Findings of the Association for Computational Linguistics: ACL 2024
💡 一句话要点
利用神经元探针揭示LLM训练中跨语言对齐的涌现机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 跨语言对齐 神经元探针 预训练动态 零样本迁移
📋 核心要点
- 现有方法缺乏对LLM预训练过程中跨语言对齐涌现机制的深入理解。
- 论文提出利用神经元探针技术,分析神经元重叠与跨语言迁移性能的相关性。
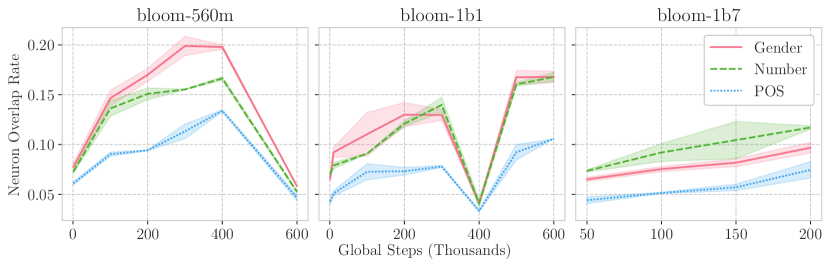
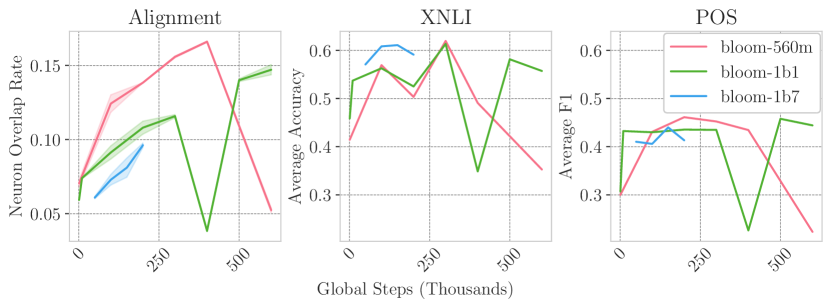
- 实验表明神经元重叠与下游性能高度相关,并揭示了预训练过程中多语言能力的退化现象。
📝 摘要(中文)
多语言大型语言模型(LLM)在零样本跨语言迁移方面表现出色。我们推测这源于它们在没有平行语料显式监督的情况下对齐语言的能力。虽然不同语言中翻译等价句子的表示在模型收敛后已知是相似的,但LLM预训练期间这种跨语言对齐是如何涌现的仍然不清楚。本研究利用内在探针技术,识别编码语言特征的神经元子集,从而将跨语言神经元重叠程度与给定模型的零样本跨语言迁移性能相关联。具体来说,我们依赖于多语言自回归LLM BLOOM 在不同训练步骤和模型规模下的检查点。我们观察到神经元重叠与下游性能之间存在高度相关性,这支持了我们关于有效跨语言迁移条件的假设。有趣的是,我们还在预训练过程的某些阶段检测到隐式对齐和多语言能力的退化,为多语言预训练动态提供了新的见解。
🔬 方法详解
问题定义:论文旨在探究大型语言模型(LLM)在预训练过程中,跨语言对齐是如何涌现的。现有方法缺乏对这一过程的细粒度理解,无法解释LLM为何能在零样本跨语言迁移任务中表现出色。理解这一过程有助于更好地设计多语言LLM的预训练策略。
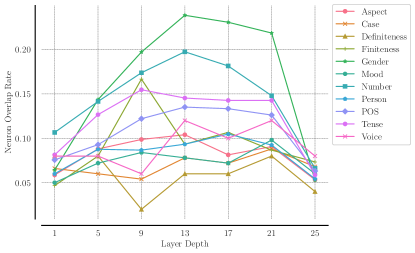
核心思路:论文的核心思路是利用内在探针技术,通过识别编码特定语言特征的神经元子集,来量化不同语言在LLM内部表示空间中的对齐程度。如果不同语言的等价句子激活了相似的神经元集合,则认为这些语言在模型内部实现了对齐。通过分析神经元重叠程度与跨语言迁移性能之间的相关性,可以推断跨语言对齐对模型性能的影响。
技术框架:整体框架包括以下几个步骤:1) 选择多语言LLM(BLOOM)的不同训练阶段的检查点;2) 使用内在探针技术识别编码特定语言特征的神经元子集;3) 计算不同语言神经元集合之间的重叠程度;4) 评估模型在零样本跨语言迁移任务上的性能;5) 分析神经元重叠程度与迁移性能之间的相关性。
关键创新:论文的关键创新在于将内在探针技术应用于分析LLM预训练过程中的跨语言对齐现象。与以往关注模型最终表示的研究不同,该研究关注对齐过程的动态变化,揭示了预训练过程中可能出现的对齐退化现象。此外,该研究通过量化神经元重叠程度,为跨语言对齐提供了一种可度量的指标。
关键设计:论文的关键设计包括:1) 使用线性探针来识别编码特定语言特征的神经元;2) 使用Jaccard系数来量化神经元集合之间的重叠程度;3) 选择BLOOM模型作为研究对象,因为它是一个公开可用的多语言LLM,并且提供了多个训练阶段的检查点;4) 评估模型在多种零样本跨语言迁移任务上的性能,以确保结果的泛化性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,神经元重叠程度与零样本跨语言迁移性能之间存在高度相关性,验证了跨语言对齐对模型性能的重要性。此外,研究还发现,在预训练过程的某些阶段,隐式对齐和多语言能力会出现退化现象,这为多语言预训练策略的设计提供了新的视角。
🎯 应用场景
该研究成果可应用于多语言LLM的预训练优化,例如,通过监控神经元重叠程度,可以及时调整训练策略,避免对齐退化现象的发生。此外,该研究还可以指导多语言LLM的微调,使其更好地适应特定领域的跨语言任务。该研究有助于提升多语言LLM的性能和鲁棒性,促进跨语言信息处理和交流。
📄 摘要(原文)
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.