DialSim: A Dialogue Simulator for Evaluating Long-Term Multi-Party Dialogue Understanding of Conversational Agents
作者: Jiho Kim, Woosog Chay, Hyeonji Hwang, Daeun Kyung, Hyunseung Chung, Eunbyeol Cho, Yeonsu Kwon, Yohan Jo, Edward Choi
分类: cs.CL, cs.AI
发布日期: 2024-06-19 (更新: 2025-09-26)
💡 一句话要点
DialSim:用于评估会话代理长期多方对话理解的对话模拟器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话模拟 会话代理 长期对话理解 多方对话 问答数据集
📋 核心要点
- 现有会话代理评估忽略了真实对话的复杂性,如多方对话和长程上下文依赖。
- DialSim通过模拟对话场景,让代理扮演角色并回答问题,评估其长期对话理解能力。
- LongDialQA数据集包含大量长篇对话和问题,为DialSim提供数据支持,并减少了先验知识依赖。
📝 摘要(中文)
本文提出DialSim,一个基于对话模拟的评估框架,旨在弥补现有会话代理评估方法在多方对话和长程上下文依赖方面的不足。DialSim中,代理扮演剧本对话中的角色,并通过仅使用对话历史回答自发问题来评估其能力,同时识别自身信息不足的情况。为了支持该框架,作者构建了LongDialQA数据集,该数据集来源于长篇电视剧,包含超过1300个对话会话,每个会话都配有超过1000个精心策划的问题,总计超过352,000个tokens。为了减少对先验知识的依赖,所有角色名称都被匿名化或替换。使用DialSim对最先进的基于LLM的会话代理的评估表明,即使是具有大型上下文窗口或RAG功能的模型,也难以在长期多方交互中保持准确的理解,这突显了会话AI中对更真实和更具挑战性的基准的需求。
🔬 方法详解
问题定义:现有会话代理的评估方法通常无法充分评估其在真实场景下的长期多方对话理解能力。这些方法往往忽略了对话中复杂的上下文依赖关系,以及代理在信息不足时识别并拒绝回答的能力。因此,需要一种更贴近真实场景的评估框架,以更全面地衡量会话代理的性能。
核心思路:DialSim的核心思路是构建一个对话模拟环境,其中会话代理扮演预先设定的角色,并根据对话历史回答问题。通过这种方式,可以模拟真实的多方对话场景,并评估代理在长期上下文中的理解能力。同时,DialSim还要求代理能够识别自身信息不足的情况,并拒绝回答相关问题,从而更全面地评估其智能水平。
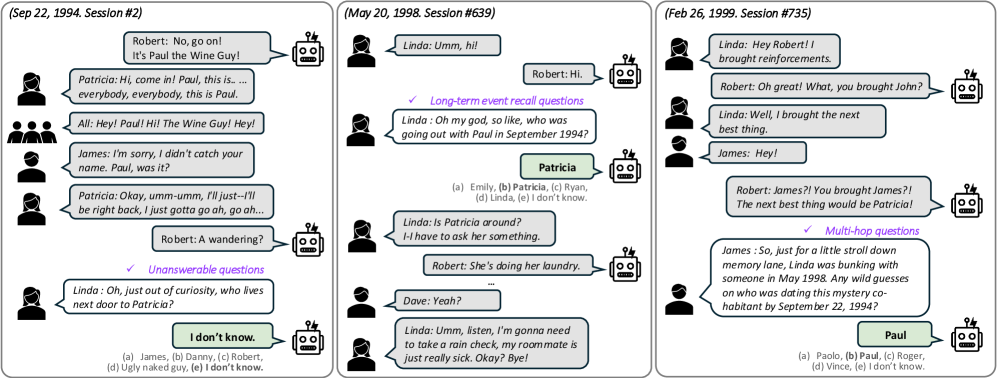
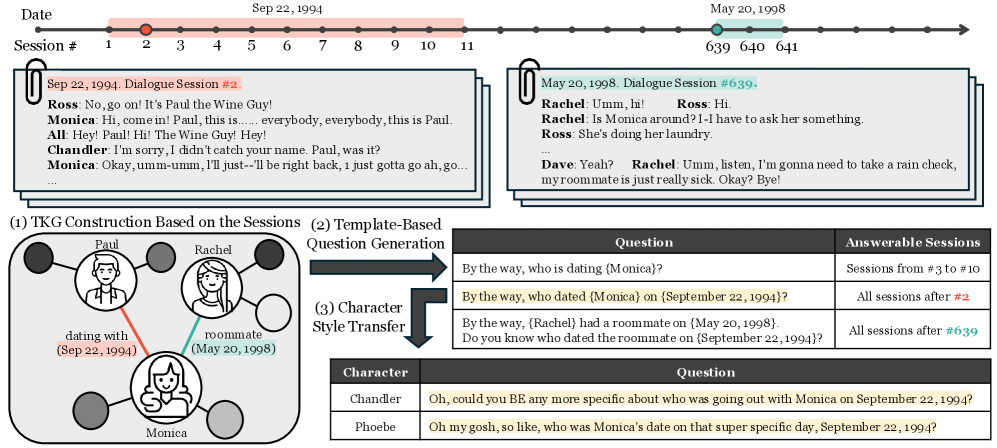
技术框架:DialSim框架主要包含以下几个部分:1) 剧本对话:使用预先编写的剧本对话作为模拟场景的基础。2) 角色扮演:会话代理扮演剧本中的角色,并根据对话历史进行推理和回答问题。3) 问题生成:LongDialQA数据集提供大量与对话相关的精心策划的问题。4) 评估指标:使用准确率等指标评估代理回答问题的质量,并评估其识别信息不足情况的能力。
关键创新:DialSim的关键创新在于其基于对话模拟的评估方法,以及LongDialQA数据集的构建。传统的评估方法往往侧重于单轮对话或短程上下文,而DialSim则能够模拟真实的多方对话场景,并评估代理在长期上下文中的理解能力。LongDialQA数据集的构建也为DialSim提供了数据支持,并减少了对先验知识的依赖。
关键设计:LongDialQA数据集的关键设计在于其来源于长篇电视剧,并对角色名称进行了匿名化或替换,从而减少了对先验知识的依赖。此外,数据集中的问题也经过精心策划,涵盖了对话中的各种细节和上下文信息,从而能够更全面地评估代理的理解能力。DialSim框架的具体参数设置和损失函数等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是具有大型上下文窗口或RAG功能的先进LLM会话代理,在DialSim的长期多方对话评估中也表现不佳,无法保持准确的理解。这表明现有模型在处理复杂对话场景方面仍存在挑战,需要进一步改进。
🎯 应用场景
DialSim可应用于教育、娱乐等领域,例如,评估智能 tutor 在长期互动教学中的表现,或评估游戏 NPC 在复杂剧情对话中的智能程度。该研究有助于推动会话代理在真实场景中的应用,并促进更智能、更自然的对话交互体验。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have significantly enhanced conversational agents, making them applicable to various fields (e.g., education, entertainment). Despite their progress, the evaluation of the agents often overlooks the complexities of real-world conversations, such as multi-party dialogues and extended contextual dependencies. To bridge this gap, we introduce DialSim, a dialogue simulation-based evaluation framework. In DialSim, an agent assumes the role of a character in a scripted conversation and is evaluated on their ability to answer spontaneous questions using only the dialogue history, while recognizing when they lack sufficient information. To support this framework, we introduce LongDialQA, a new QA dataset constructed from long-running TV shows, comprising over 1,300 dialogue sessions, each paired with more than 1,000 carefully curated questions, totaling over 352,000 tokens. To minimize reliance on prior knowledge, all character names are anonymized or swapped. Our evaluation of state-of-the-art LLM-based conversational agents using DialSim reveals that even models with large context windows or RAG capabilities struggle to maintain accurate comprehension over long-term, multi-party interactions-underscoring the need for more realistic and challenging benchmarks in conversational AI.