On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
作者: Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
分类: cs.CL
发布日期: 2024-06-14
备注: A survey on LLMs-driven synthetic data generation, curation and evaluation
💡 一句话要点
综述LLM驱动的合成数据生成、管理与评估,填补领域框架空白。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 合成数据生成 数据增强 数据管理 数据评估
📋 核心要点
- 深度学习依赖大量高质量数据,但真实数据获取成本高、存在偏差,限制了模型性能。
- 该综述构建了LLM驱动的合成数据生成通用流程框架,系统性地组织和分析现有研究。
- 通过框架分析,论文指出了现有研究的不足之处,并为未来研究方向提供了指导。
📝 摘要(中文)
深度学习领域长期面临数据数量和质量的困境。近年来,大型语言模型(LLMs)的出现为解决这一问题提供了一种以数据为中心的方案,即利用合成数据生成来缓解真实世界数据的局限性。然而,目前对该领域的研究缺乏统一的框架,并且大多停留在表面。因此,本文基于合成数据生成的一般工作流程,对相关研究进行了组织。通过这种方式,我们强调了现有研究中的差距,并概述了未来研究的潜在途径。这项工作旨在引导学术界和工业界对LLM驱动的合成数据生成的能力和应用进行更深入、更有条理的探究。
🔬 方法详解
问题定义:现有深度学习模型训练严重依赖大规模高质量数据,但真实世界数据往往存在数量不足、获取成本高昂、数据分布偏差等问题。合成数据生成作为一种潜在的解决方案,受到了越来越多的关注。然而,目前利用大型语言模型(LLMs)进行合成数据生成的研究缺乏一个统一的框架,导致研究方向分散,难以系统性地评估和改进。
核心思路:该综述的核心思路是构建一个通用的、结构化的LLM驱动的合成数据生成流程框架,将现有研究纳入该框架中进行分析和组织。通过这个框架,可以清晰地识别现有研究的优势和不足,并为未来的研究方向提供指导。
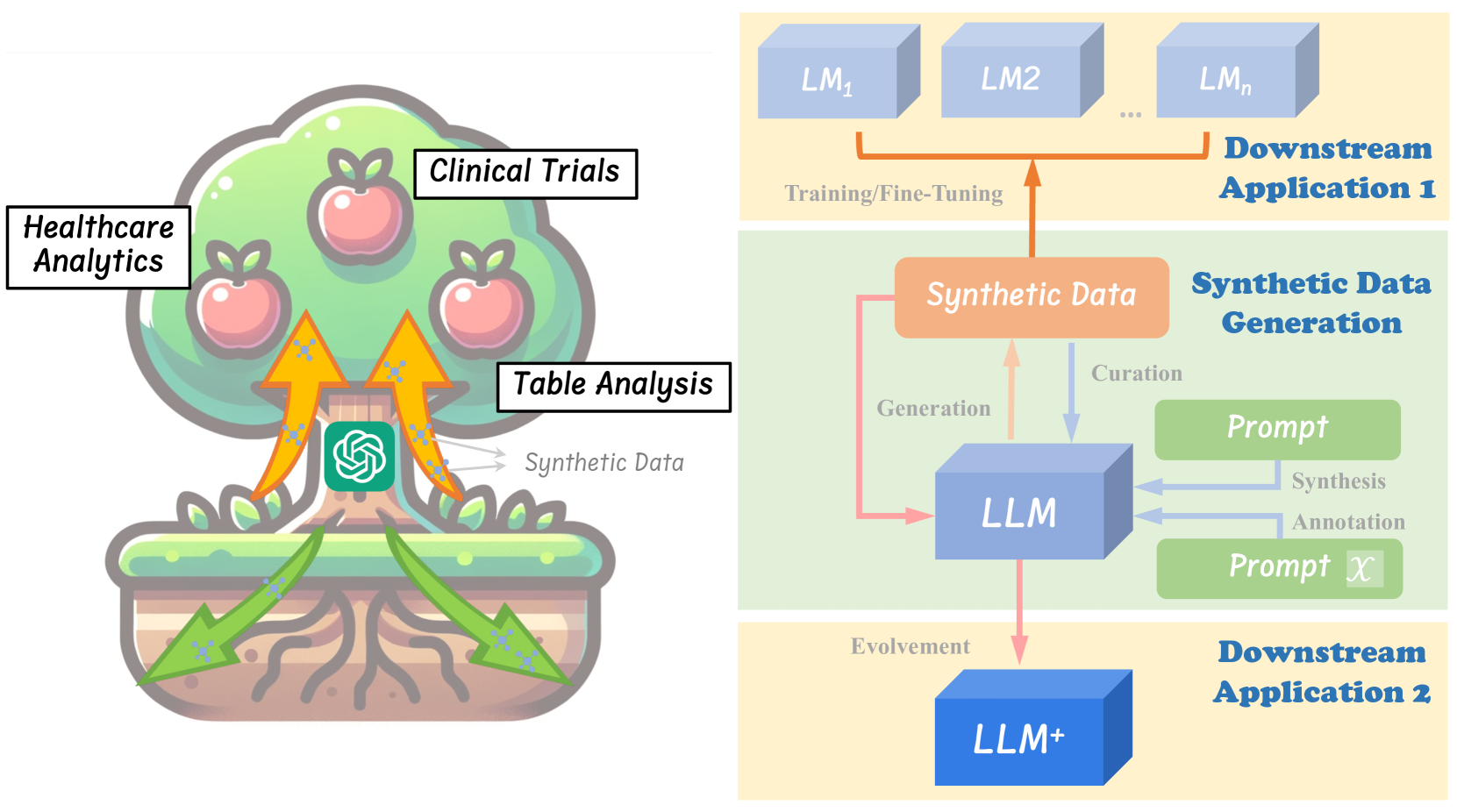
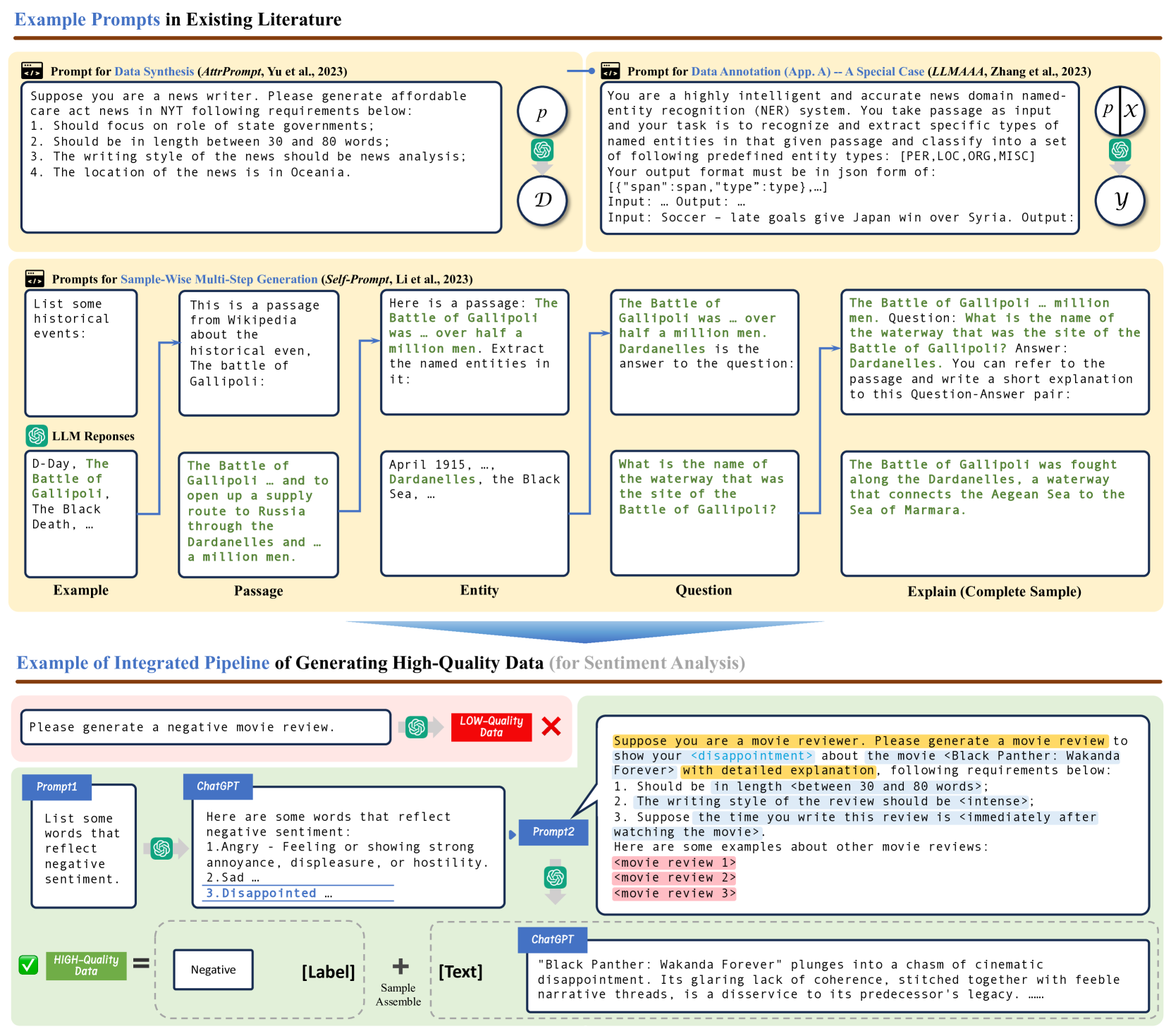
技术框架:该综述构建的通用流程框架主要包含三个阶段:合成数据生成(Synthetic Data Generation)、合成数据管理(Synthetic Data Curation)和合成数据评估(Synthetic Data Evaluation)。合成数据生成阶段关注如何利用LLM生成高质量的合成数据;合成数据管理阶段关注如何对生成的合成数据进行清洗、筛选和增强;合成数据评估阶段关注如何评估合成数据的质量和有效性。
关键创新:该综述的关键创新在于提出了一个统一的LLM驱动的合成数据生成流程框架。与以往的研究不同,该综述不是简单地罗列现有研究,而是将它们纳入一个结构化的框架中进行分析,从而能够更清晰地识别现有研究的差距和未来的研究方向。该框架为后续研究者提供了一个有力的工具,可以帮助他们更好地理解和探索LLM驱动的合成数据生成。
关键设计:该综述的关键设计在于对合成数据生成流程的三个阶段进行了详细的划分和定义,并针对每个阶段的关键技术和挑战进行了深入的分析。例如,在合成数据生成阶段,综述讨论了不同的LLM模型、生成策略和控制方法;在合成数据管理阶段,综述讨论了数据清洗、数据增强和数据选择等技术;在合成数据评估阶段,综述讨论了不同的评估指标和方法。
🖼️ 关键图片

📊 实验亮点
该综述通过构建统一框架,系统性地分析了现有LLM驱动的合成数据生成研究,揭示了现有方法的局限性,并为未来的研究方向提供了明确的指导。虽然没有提供具体的实验数据,但其框架性的贡献为后续研究奠定了基础。
🎯 应用场景
该研究成果可广泛应用于数据稀缺或隐私敏感的领域,例如医疗健康、金融风控、自动驾驶等。通过LLM驱动的合成数据生成,可以有效缓解数据不足的问题,提升模型性能,并降低数据获取成本。未来,该技术有望推动人工智能在更多领域的应用。
📄 摘要(原文)
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.